![]()
如何成为一名优秀的程序员
如何快速成长
- 要写代码先看代码
- 好的代码让人看到时可以快速了解,并且能够抓住主要设计精髓
- 多看代码,保持代码的敏感度
- 写代码时,多做总结
- 写的代码要体现设计的思想
如何提升技术
- 了解项目中架构方面的相关知识,尤其是封装的组件
- 架构师工作内容简要介绍:
- 搭建高可用的框架:
- 搭建数据库时,要考虑如果一台MySQL服务宕机,如何保证业务切换到另一台机器上
- 要考虑高并发因素:
- 需要会用nginx,mycat,netty,redis之类的工具
- 考虑搭建实现负载均衡
- 要把设计好的架构部署上线:
- 要知道如何将nginx集群等组件部署上线
- 了解部署的linux命令和脚本
- 了解jenkins之类的部署工具
- 能够解决部署和运行时的问题:
- 懂得如何搭建系统
- 具备针对netty等组件的debug能力
- 能够通过日志知道集群的运作情况
- 能够快速解决集群问题
- 不仅仅关注技术,还要结合业务:
- 将业务需求通过架构实现
- 知道组件的优劣
- 能够选型并且设计方案
- 熟悉相关技能:
- 先从ant脚本 ,jekins脚本和linux脚本入手,熟悉系统的部署方式以及必备的linux调试技能
- 通过观察nginx或者dubbo或者zookeeper的配置文件,了解各个组件的运作方式,并能够通过这些了解高并发可用系统里负载均衡和失效转移的配置方式
- 观察线上相关日志,了解系统部署情况,以及从架构层面了解诸多组件之间的关联
- 多多解决实际问题,了解组件的关键配置和组件的底层代码
- 熟悉基本的部署和架构方面的技能
- 测试和上线阶段出现问题:
- kafka没有配置好,导致消息积压
- dubbo超时时间配置过长,导致调用链路超时失效
- redis超时时间过长,导致OOM异常
- 跟在资深人员之后查问题,找到问题后,手动复盘一下:
- 做到熟悉组件配置
- 并能了解组件的底层代码
- 熟悉配置各种框架组件的实施方案
- 架构师面试相关问题:
- 如何部署nginx或者其它组件,从而实现高可用?
- Redis集群里,容灾一般是怎么做的?
- Kafka消息队列里,如何实现消息重复?如何确保消息不被重复消费?
- 底层相关比如netty里的读写索引工作方式?
好程序员的思维模式
- 经常研究你不懂的代码
- 研究你未接触过的代码,熟悉不同的代码结构和设计模式,研究代码为什么这样写
- 精通代码调试
- 先猜测一下到底发生了什么
- 假设猜测是对的,想想猜测会导致程序有什么结果
- 试着观察这些结果有没有异常的地方:
- 如果没有发现异常,说明猜测的问题很可能就是对的
- 如果发现了异常,说明猜测是错的,进行调试
- 对于一名攻城狮来说,这个过程就是电光火石的一瞬间.只要解决的问题足够多,做出来的猜测就会越准确
- 重视节约时间的工具
- 优化迭代速度
- 系统性的思维方式:
- 自己的代码和其它代码在功能上是什么关系
- 有没有好好测试代码
- 为了部署代码,线上生产环境的代码需不需要变动
- 新的代码会不会影响已经运行的代码
- 在新的功能下,目标用户的行为是否是期望的
- 代码有没有产生商业上的影响
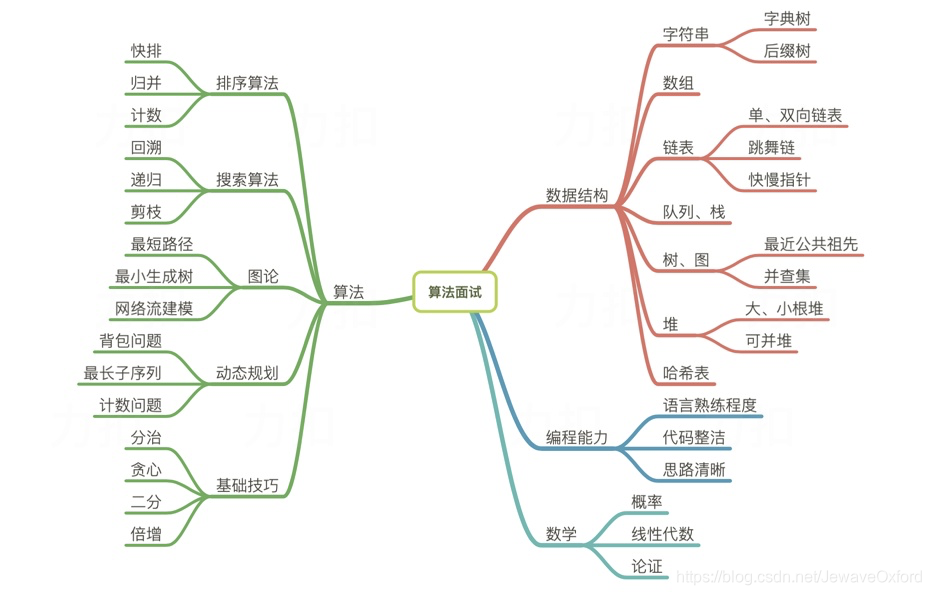
程序员算法
- 关键是理解算法背后的深层次理论,以及修炼出解决问题的思路
十大经典算法
- 快速排序算法
- 堆排序算法
- 归并排序算法
- 二分查找算法
- 线性查找算法(BFPRT)
- 深度优先搜索算法(DFS)
- 广度优先搜索算法(BFS)
- 最短路径算法(Dijkstra算法)
- 动态规划算法
- 朴素贝叶斯分类算法
![在这里插入图片描述]()
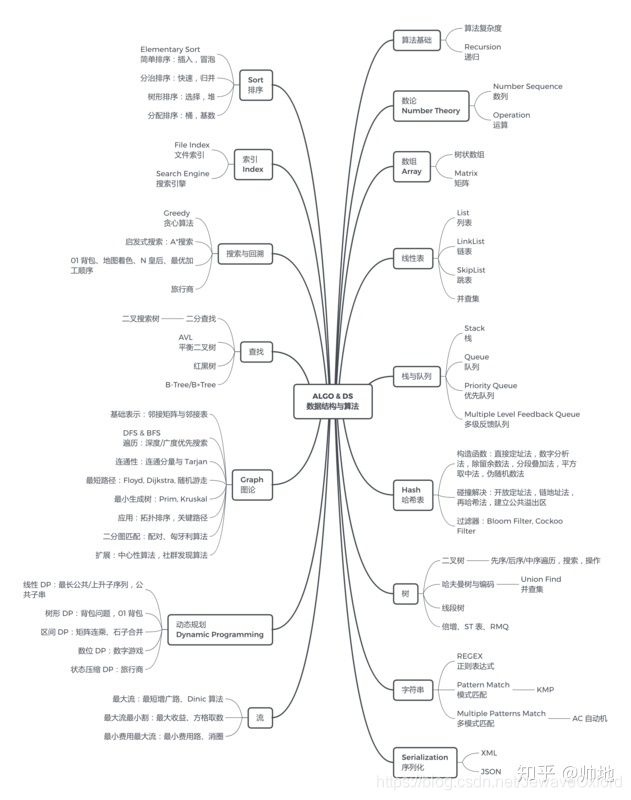
算法部分
- 二分搜索: Binary Search
- 分治: Divide Conquer
- 宽度优先搜索: Breadth First Search
- 深度优先搜索: Depth First Search
- 回溯法: Backtracking
- 双指针: Two Pointers
- 动态规划: Dynamic Programming
- 扫描线: Scan-line algorithm
- 快排: Qiuck Sort
![-]()
数据结构部分
- 栈: Stack
- 队列: Queue
- 链表: Linked List
- 数组: Array
- 哈希表: Hash Table
- 二叉树: Binary Tree
- 堆: Heap
- 并查集: Union Find
- 字典树: Trie
![在这里插入图片描述]()
LeetCode
- 刷题顺序:
- 如果时间紧迫,先刷热门推荐题
- 如果时间充裕:
- 按从低到高的难度分组刷题
- 按tag分类刷题
- 定期复习,重做之前刷过的题
- 刷题方法:
- 第一遍: 先思考,看参考答案刷,结合其他人的题解刷.思考,总结并掌握本题的类型,思考方式,最优题解
- 第二遍: 先思考,回忆最优解法,并与之前自己写过的解答作比对,总结问题和方法
- 第三遍: 提升刷题速度,拿出一个题,就能够知道其考察重点,解题方法,在短时间内写出解答
- 定期总结:
- 按照题目类型进行总结: 针对一类问题,总结有哪些解题方法,哪种方法是最优的,为什么?
- 总结重点: 有些题刷了好多遍还是不会,那就要重点关注,多思考解决方法,不断练习强化
技术学习路线
并发编程
Java内存模型(JMM)
- Java中的线程通信和消息传递
- 什么是重排序和顺序一致性,Happens-Before,As-If-Serial
Synchronized的概念和分析
- 同步,重量级锁以及Synchronized原理分析
- 自旋锁,偏向锁,轻量级锁和重量级锁概念,使用以及如何优化
Volatile和DCL知识
- Volatile使用场景和Volatile实现机制,内存语义,内存模型
- DCL单例模式,什么是DCL,如何解决DCL问题
并发基础之AQS深度分析
- AbstrasctAueuedSynchronizer同步器的概念,CLH同步队列是什么?
- 同步状态的获取和释放,线程的阻塞和唤醒
Lock和并常用工具类
- Java中的Lock:
- ReentrantLock
- ReentrantReadWriteLock
- Condition
- Java中的并发工具类:
- CyclicBarrier
- CountDownLatch
- Semphore
- Java中的并发集合类:
- ConcurrentHashMap
- ConcurrentLinkedQueue
原子操作常用知识详解
- 基本类型的原子操作:
- AtomicBoolean
- AtomicInteger
- AotomicLong
- 数组类型的原子操作:
- AtomicIntegerArray
- AtomicLongArray
- AtomicReferenceArray
- 引用类型的原子操作:
- AtomicReference
- AtomicReferenceFieldUpdater
- CAS的概念和知识点,以及缺陷
线程池和并行
- Executor
- ThreadPoolExecutor
- Callable &Future
- ScheduledExecutorService
- ThreadLocal
- Fork & Join
- 什么是并行
- 线程池如何保证核心进程不会被销毁
框架和源码应用
MyBatis应用和源码解析
- MyBatis的优缺点,Spring和MyBatis集成
- Cofig,Sql配置,mapper配置.有几种注册mapper的方法,优先级如何
- Mybatis的一级缓存,二级缓存.为什么说MyBatis的二级缓存是鸡肋
- 通过mapper的实现,MyBatis编写SQL语句的三种方式
- @MapperScan源码分析,mapperScan是如何生效的
- MyBatis如何扩展Spring的扫描器的,MyBatis扫描完之后如何使用FactoryBean
- MyBatis底层如何将对象放到Spring容器中的,运用到Spring的哪些知识
- Mybatis和Spring核心接口ImportBeanDefinitionRegistrar之间的联系
- MyBatis的以及缓存为什么会失效,Spring为何将MyBatis的一级缓存失效,有什么办法解决
- MyBatis的执行流程,MyBatis中的Sql如何缓存的,缓存在哪里
- MyBatis中的方法名为什么要和mapper当中的id一致,从源码来说明
Tomcat源码解析
- Tomcat总体概述和Tomcat启动流程,源码分析
- Tomcat中的web请求源码分析,一个http如何请求到Tomcat的,Tomcat如何处理的
- Tomcat的协议分析,从源码分析Tomcat中各种详细配置的意义
- Tomcat和Apache,Nginx等主流静态服务器的搭配使用
- Tomcat性能调优,生产环境如何让Tomcat容器性能达到最高
Spring源码分析
- Spring的基本应用和Spring源码编译
- Java中的日志系统,JUL,JCL,log4j,slf4j
- Spring4和Spring在日志方面的源码对比
- AspectJ和Spring AOP,AspectJ的静态织入
- JDK动态代理的源码分析,JDK是如何操作字节码的
- Spring通过CGLIB完成AOP,CGLIB如何完成方法拦截
- AnnotationAwareAspectJAutoProxyCreator如何完成代理织入的
- BeanDefinition是什么,Spring中各种BeanDefinition的作用
- BeanDefinition有什么作用,如何改变一个Bean的行为
- BeanDefinitionRegistry的作用,源码分析
- BeanNameGenerator如何改变beanName的生成策略
- BeanPostProcessor如何作用Bean的实例化过程,经典应用场景有哪些,Spring内部哪里用到了这个接口
- BeanFactoryPostProcessor和BeanPostProcessor的区别,经典应用场景,Spring内部是如何使用BeanFactoryPostProcessor的
- BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor的关系以及区别,Spring底层如何进行调用的
- ConfigurationClassPostProcessor这个类如何完成Bean的扫描,如何完成@Bean的扫描,如何完成@Import的解析
- @Import的三种类型:
- 如何利用ImportSelector完成对Spring的扩展
- @Configuration这个注解为什么可以不加,加与不加的区别,底层为什么使用CGLIB
- @Bean方法是如何保持单例的?如果不需要单例需要怎么配置?为什么需要这么配置
- SpringFactoryBean和BeanFactory的区别?有哪些经典应用场景?Spring的factoryMethod的经典应用场景
- ImportBeanDefinitionRegistrar这个接口的作用?主流框架是如何利用这个类来完成和Spring的结合的
- Spring是什么时候来执行后置处理器的?有哪些重要的后置处理器?比如CommonAnnonationBeanPostProcessor
- Spring和SpringBoot当中各种@EnableXxx的原理是什么?如何自定义实现一个?比如动态开启某些自定义功能
- Spring如何来完成Bean的循环依赖并且实例化的?什么是Spring的IOC容器?怎么通过源码来理解
- Bean的实例化过程?源码中两次getSingleleton的不同?SpringMVC的源码分析
Spring微服务
SpringCloud
- Eureka源码分析,服务注册和服务发现,心跳机制,保护机制?对比Eureka和Zookeeper,什么是CAP原则
- Ribbon源码分析和负载均衡?客户端负载均衡?服务端负载均衡?Ribbon核心组件IRule以及重写IRule
- Fegin源码分析和声明式服务调用?Fegin负载均衡?Fegin如何与Hystrix结合使用?有什么问题
- Hystrix如何实现服务限流,降级?大型分布式项目服务雪崩如何解决?服务熔断到底是什么?一线公司的企业级解决方案
- HystrixDashboard如何实现自定义接口降级?监控数据?数据聚合等等
- Zuul统一网关详解,服务路由,过滤器使用等?从源头拦截掉一些不良请求
- 分布式配置中心Config详解?如何与Github或是自定义的Git平台结合,比如Gitlab
- 分布式链路详解?串联调用链,让Bug无处可藏?如何理清微服务的依赖关系?如何跟清业务流的处理顺序
SpringBoot
- SpringBoot的源码分析和基本应用?利用SpringMVC知识模拟和手写一个SpringBoot
- SpringMVC零配置如何实现的?利用了Servlet 3.0的哪些新知识?在SpringMVC中如何内嵌一个Tomcat如何把web.xml去掉
- SpringBoot中的监听器和设计模式中的观察者模式的关系?模拟Java当中的事件驱动编程模型
- SpringBoot的启动流程分析?SpringBoot如何初始化Spring中的context?如何初始化DispatchServlet?如何启动Tomcat的
- SpringBoot中的配置文件类型,配置文件的语法,配置文件的加载顺序?模拟SpringBoot中的自动配置
- SpringBoot的日志系统?SpringBoot如何设计自身的日志系统的?有什么优势?如何做到统一日志的
Docker
- 什么是Docker?为什么要使用Docker,和开发有什么关系?能够带来便捷?Docker简介,入门?Docker的架构是怎样的
- Docker的三大核心概念:
- 镜像(Images)
- 容器(Cotainers)
- 仓库服务注册器(Registry)
- Docker的基础用法以及Docker镜像的基本操作
- 容器技术入门?Docker容器基本操作?容器虚拟化网络概述以及Docker的容器网络是怎样的
- 如何利用Dockerfile格式,Dockerfile命令以及docker builder构建镜像
- Compose和Dockerfile的区别是什么?Compose的配置文件以及使用Compose运行容器?Docker实战应用
性能调优
MySQL性能调优
- MySQL中为什么不使用其他数据结构而就用B+树作为索引的数据结构
- MySQL执行计划详解以及MySQL查询优化器详解
- MySQL索引优化实战?包括普通查询,group by,order by
Java数据结构算法
- Hash算法详解?Java中的HashMap源码分析?手写一个HashMap
- 从源码理解HashMap JDK 7和JDK 8的变化?为什么会有这样的变化?手写一个HashMap
- 顺序存储,双向链表,单向链表,Java当中LinkedList的源码分析
- Java当中线性结构,树形结构以及图形结构分析以及应用场景和经典使用
- 大数字运算和经典排序,二叉树红黑树排序,查找
JVM性能调优
- Java内存模型总体概述,类加载过程和ClassLoader,运行时数据区当中的总体内容,编译原理
- 内存区域和内存溢出异常,虚拟机对象,程序计数器,Java栈,本地方法栈,操作数,方法区,堆内存和元数据
- ClassLoader的知识详解,默认全盘负责机制,从JDK源码来理解双亲委派模式,如何打破双亲委派?为什么需要打破双亲委派
- 虚拟机性能监控与故障处理,JVM基本命令,jinfo命令的使用,jmap命令的使用,jstak命令的使用,使用jvisualvm分析
- 垃圾收集器与内存分配策略,垃圾回收算法与基础,串型收集器,并行收集器,内存分配与回收策略
- 程序编译与代码优化,运行期优化,编译期优化,JVM调优的本质是什么?什么是轻GC?什么是Full GC?如何进行调优
- JVM执行子系统,类文件结构,类加载机制,字节码执行引擎,字节码编译模式,如何改变字节码编译模式
互联网工程
Maven
- 整体认知Maven的体系结构
- Maven的核心命令
- Maven的pom配置体系
- 搭建Nexus私服
Git
- 动手搭建Git客户端与服务端
- Git核心命令
- Git企业应用
- Git的原理,Git底层指针介绍
Linux
- Linux启动,原理,目录介绍
- Linux运维常用命令,Linux用户与权限介绍
- shell脚本编写
分布式
分布式协调框架-Zookeeper
- 什么是分布式系统?分布式系统有何挑战?Zookeeper快速入门以及集群搭建基本使用
- Zookeeper有哪些常用命令以及注意事项,zkclient客户端与curator框架有什么功能以及如何使用
- 手写Zookeeper常见应用场景:
- Zookeeper核心概念zNode,watch机制,序列化,持久化机制详解以及源码解析
- Zookeeper如何解决分布式中的一致性问题?领导选举流程讲解及其源码解析
RPC服务框架-Dubbo
- 手写RPC框架以及为什么要使用Dubbo?传统应用系统如何演变成分布式应用系统详解
- Dubbo的六大特性是什么?对企业级开发有何好处?Dubbo作用的简要说明?快速演示Dubbo调用实例
- Dubbo中的协议,注册中心,动态代理机制是怎么达到可扩展的?Dubbo的扩展机制源码解析
- Dubbo从服务提供者到注册中心到服务消费者调用服务中间的流程源码解析
- Dubbo监控中心以及管理平台的使用,方便企业级开发与管理
分布式数据缓存-Redis
- 关系型数据库瓶颈与优化?Encache和Redis对比?NoSQL应用场景
- Redis的基本数据类型,比如Map的使用场景?有什么优缺点?什么时候用Map
- Redis高级特性?如何理解Redis单线程但是高性能?如何理解Redis与Epoll
- Redis持久化?什么情况下需要持久化?方案是什么?有什么优缺点?如何优雅地选择持久化方案
- Redis项目中的应用?Redis高级命令mget,scan?为什么有scan这条命令?如何理解Redis游标
- 单机版Redis安装以及Redis生产环境启用方案
- Redis持久化机对于生产环境灾难恢复的意义
- Redis主从框架下如何才能做到99.9% 的高可用性
- 在项目中重新搭建一套主从复制+高可用+多master的Redis Cluster集群
- Redis在实践中的一些常见问题以及优化思路,包括Linux内核参数优化
- Redis的RDB持久化配置以及数据恢复实验
- Redis的RDB和AOF两种持久化机制的优劣势对比
分布式数据存储-MyCAT
- 分库分表场景介绍
- MyCAT原理介绍
- 分库分表实战
分布式RabbitMQ
- RabbitMQ环境安装,RabbitMQ整体架构与消息流转,交换机详解
- 消息如何保障100%的投递成功方案?企业消息幂等性概念以及业界主流解决方案
- Confirm确认消息详解,Return返回消息详解,消费端的限流策略,消费端ACK与重回队列机制
- SpringAMQP用户管理组件:
- RabbitAdmin应用
- SpringAMQP消息模板组件
- RabbitTemplate实战
- SpringAMQP消息容器:
- SimpleMessageListenerContainer详解
- SpringAMQP消息适配器
- MessageListenerAdapter使用
- RabbbitMQ与SpringBoot 2.0整合实战以及RabbitMQ与SpringCloud Stream整合实战
- RabbitMQ集群架构模式,RabbitMQ集群镜像队列构建实现可靠性存储,RabbitMQ集群整合负载均衡基础组件HaProxy
posted @
2021-07-05 12:58
攻城狮Chova
阅读(
190)
评论()
收藏
举报



 浙公网安备 33010602011771号
浙公网安备 33010602011771号