
李宏毅机器学习课程笔记-14.1 Seq2Seq:Conditional Generation
基于RNN的Generation
可以用RNN生成一个word、sentence、图片等等。
一个word有多个character组成,因此RNN每次生成一个character。一个sentence由多个word组成,因此RNN每次生成一个word。一张图片由多个像素组成,因此RNN每次生成一个像素。
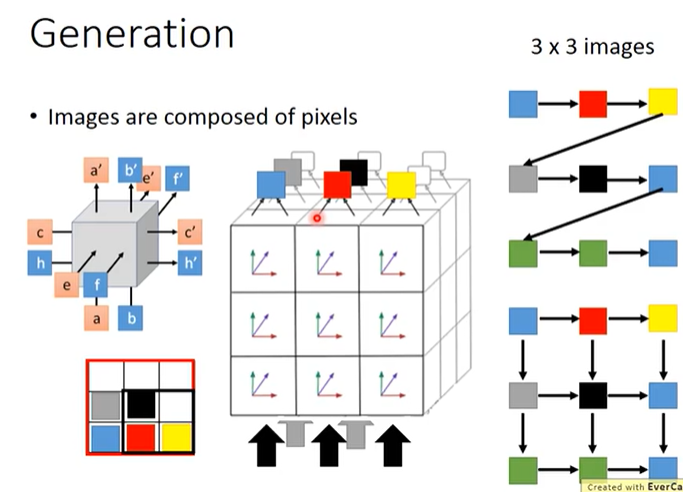
从上到下、从左到右逐个生成像素这种方法(上图右上角)并没有充分考虑pixel之间的位置关系,有一种更充分地考虑了pixel之间位置关系的方法(上图右下角)叫做PixelRNN,PixelRNN根据多个邻居生成一个像素,这可以通过3维LSTM单元(上图左上角)实现。如上图左上角所示,3维LSTM单元有3组输入和3组输出,将几层(每层9个)3维LSTM单元排列在一起,就可以生成一张3×3的图片。
以下为一些使用RNN进行Generation的论文。

Conditional Generation
只使用RNN进行Generation的话是不够的,因为我们希望生成的结果并不是随机的,比如我们希望机器生成的sentence是合乎情境的,假如我说了“Hello”,那机器就应该说“Nice to meet you”之类的内容,这就是Conditional Generation。
为了实现Conditional Generation,我们可以将condition转换成vector输入到RNN中。在Chat-bot和Machine Translation任务中,condition就是一个sentence;在Image Caption任务中,condition就是一张图片。
在实现Conditional Generation时通常使用Encoder-Decoder框架,其中Encoder负责将condition转换为一个vector、Decoder负责将condition vector转换成最后的输出。Encoder和Decoder通常是一起训练(jointly train)的,两者的参数可以相同也可以不同。
在Chat-bot和Machine Translation任务中,输入和输出都是sequence,所以这类任务都是一种Sequence-to-sequence Learning,简称Seq2Seq。
在Chat-bot任务中,机器应该要考虑聊天记录,比如机器说“Hello”然后我回复“Hi”,如果这时机器也回复“Hi”之类的就很智障了,所以机器需要考虑更长的context,如果用户说过了“我叫臭咸鱼”,机器就不应该再问“你的名字是什么/你叫什么”了。因此有一种做法可以是我们有一个双层的Encoder,首先用Encoder的第一层讲聊天记录作为condition表示为vector,然后输入到Encoder的第二层。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号