
李宏毅机器学习课程笔记-6.4学习率调整方法
RMSProp
2013年Hinton在Coursera提出。
-
背景
RMSProp是Adagrad的升级版。
在训练神经网络时,损失函数不一定是凸函数(局部最小值即为全局最小值),可能是各种各样的函数,有时需要较大的学习率,有时需要较小的学习率,而Adagrad并不能实现这种效果,因此产生了RMSProp。
-
定义
\(w^{t+1}=w^t-\frac{\eta}{\sigma^t}g^t,\ \ (\sigma^0=g^0,\sigma^t=\sqrt{\alpha(\sigma^{t-1})^2+(1-\alpha)(g^t)^2})\)
其中\(w\)是某个参数;\(\eta\)是学习率;\(g\)是梯度;\(\alpha\)代表旧的梯度的重要性,值越小则旧的梯度越不重要。 -
神经网络中很难找到最优的参数吗?
面临的问题有plateau、saddle point和local minima。
英文 中文 梯度 plateau 停滞期 \(\frac{\partial L}{\partial w}\approx0\) saddle point 鞍点 \(\frac{\partial L}{\partial w}=0\) local minima 局部最小值 \(\frac{\partial L}{\partial w}=0\) 2007年有人(名字读音好像是young la ken)指出神经网络的error surface是很平滑的,没有很多局部最优。
假设有1000个参数,一个参数处于局部最优的概率是\(p\),则整个神经网络处于局部最优的概率是\(p^{1000}\),这个值是很小的。
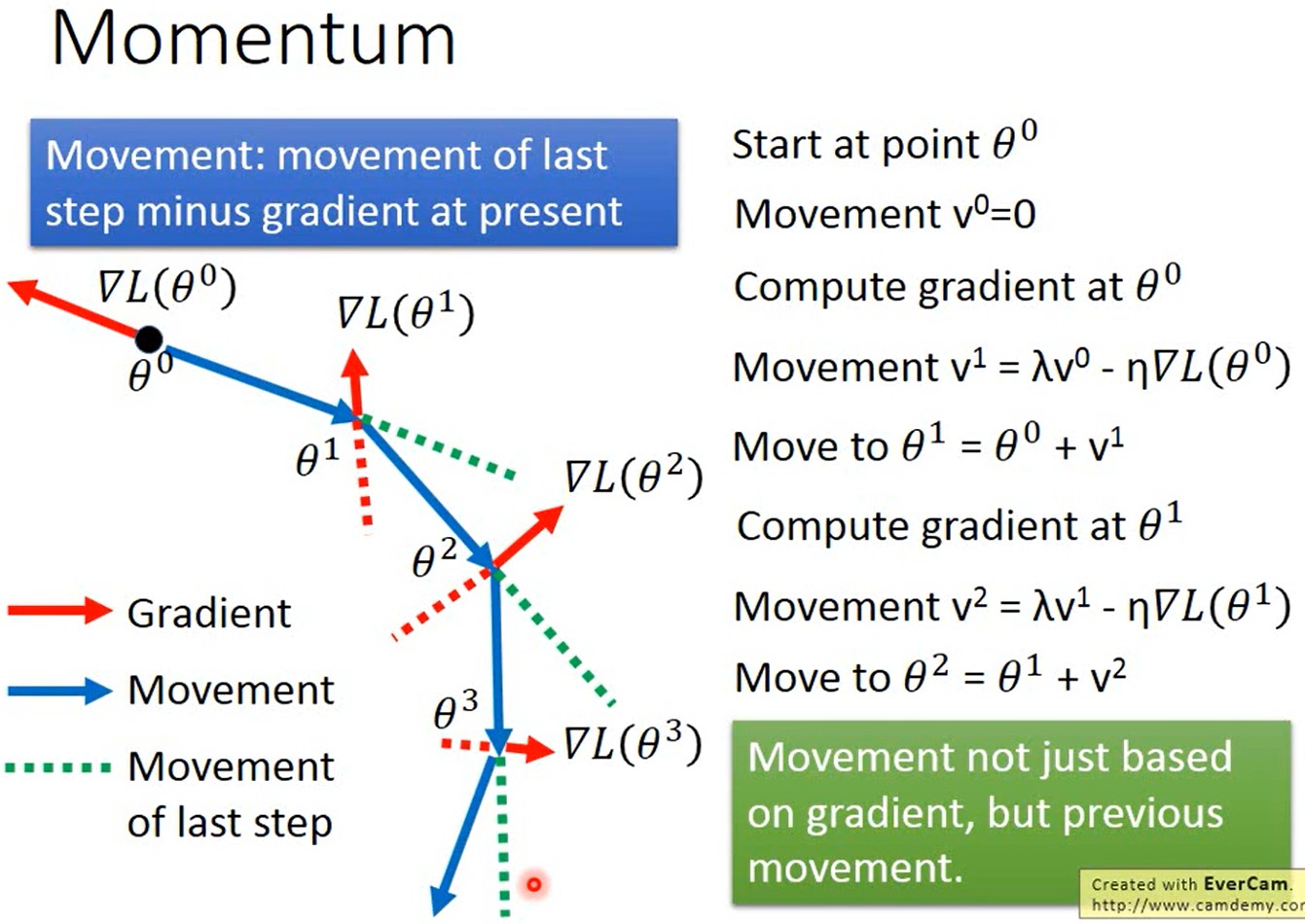
Momentum
1986年提出
-
如何处理停滞期、鞍点、局部最小值等问题?
考虑现实世界中物体具有惯性、动量(Momentum)的特点,尽可能避免“小球”陷入error surface上的这几种位置。
-
定义
如下图所示,不仅考虑当前的梯度,还考虑上一次的移动方向:\(v^t=\lambda v^{t-1}-\eta g^t,v^0=0\),
其中上标\(t\)是迭代次数;\(v\)指移动方向(movement),类似于物理中的速度;\(g\)是梯度(gradient);\(\lambda\)用来控制惯性的重要性,值越大代表惯性越重要;\(\eta\)是学习率。
Adam
RMSProp+Momentum+Bias Correction,2015年提出
Adam VS SGDM
目前常用的就是Adam和SGDM。
Adam训练速度快,large generalization gap(在训练集和验证集上的性能差异大),但不稳定;SGDM更稳定,little generalization gap,更加converge(收敛)。
| 领域 | 技术/模型 | 优化器 |
|---|---|---|
| Q&A、文意理解、文章生成 | BERT | Adam |
| BERT的Backbone、翻译 | Transformer | Adam |
| 语音生成 | Tacotron | Adam |
| 目标检测 | YOLO | SGDM |
| 目标检测 | Mask R-CNN | SGDM |
| 图片分类 | ResNet | SGDM |
| 图片生成 | Big-GAN | Adam |
| 元学习 | MAML | Adam |
SGDM适用于计算机视觉,Adam适用于NLP、Speech Synthesis、GAN、Reinforcement Learning。
SWATS
2017年提出,尝试把Adam和SGDM结合,其实就是前一段时间用Adam,后一段时间用SGDM,但在切换时需要解决一些问题。
尝试改进Adam
-
AMSGrad
-
Adam的问题
Non-informative gradients contribute more than informative gradients.
在Adam中,之前所有的梯度都会对第\(t\)步的movement产生影响。然而较早阶段(比如第1、2步)的梯度信息是相对无效的,较晚阶段(比如\(t-1\)、\(t-2\)步)的梯度信息是相对有效的。在Adam中,可能发生较早阶段梯度相对于较晚阶段梯度比重更大的问题。
-
提出AMSGrad
2018年提出
-
-
AdaBound
2019年提出,目的也是改进Adam。
-
Adam需要warm up吗?需要
warm up:开始时学习率小,后面学习率大。
因为实验结果说明在刚开始的几次(大概是10次)迭代中,参数值的分布比较散乱(distort),因此梯度值就比较散乱,导致梯度下降不稳定。
-
RAdam
2020年提出
-
Lookahead
2019年提出,像一个wrapper一样套在优化器外面,适用于Adam、SGDM等任何优化器。
迭代几次后会回头检查一下。
-
Nadam
2016年提出,把NAG的概念应用到Adam上。
-
AdamW
2017年提出,这个优化器还是有重要应用的(训练出了某个BERT模型)。
尝试改进SGDM
-
LR range test
2017年提出
-
Cyclical LR
2017年提出
-
SGDR
2017年提出,模拟Cosine但并不是Cosine
-
One-cycle LR
2017年提出,warm-up+annealing+fine-tuning
-
SGDW
2017年提出,
改进Momentum
-
背景
如果梯度指出要停下来,但动量说要继续走,这样可能导致坏的结果。
-
NAG(Nesterov accelerated gradient)
1983年提出,会预测下一步。
Early Stopping
如果学习率调整得较好,随着迭代次数增加,神经网络在训练集上的loss会越来越小,但因为验证集(Validation set)和训练集不完全一样,所以神经网络在验证集上的loss可能不降反升,所以我们应该在神经网络在验证集上loss最小时停止训练。
Keras文档中就有关于Early stopping的说明。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!

