
DStream-01 DStream的原理和源码
Demo
object KafkaDirectDstream {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("KafkaDirectDstream")
sparkConf.setMaster("local[*]")
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "1")
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val streamingContext = new StreamingContext(sparkConf, Seconds(2))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "s1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "p1",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("test_topic")
val dstream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
dstream.map(record => (record.key, record.value, record.partition(), record.offset()))
.foreachRDD(rdd => {
....
})
})
streamingContext.start()
streamingContext.awaitTermination()
}
}
Spark 源码分析
StreamingContext
整个Dstream 类似RDD "懒加载" ,出发点就是 streamingContext.start()。
为了方便查看,我去掉了一些其他代码,只保留关键逻辑代码
def start(): Unit = synchronized {
state match {
case INITIALIZED =>
StreamingContext.ACTIVATION_LOCK.synchronized {
try {
validate()
// 最关键的地方 new 了一个线程去启动 scheduler
ThreadUtils.runInNewThread("streaming-start") {
sparkContext.setCallSite(startSite.get)
sparkContext.clearJobGroup()
sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL, "false")
savedProperties.set(SerializationUtils.clone(sparkContext.localProperties.get()))
//
scheduler.start()
}
state = StreamingContextState.ACTIVE
scheduler.listenerBus.post(
StreamingListenerStreamingStarted(System.currentTimeMillis()))
} catch {
}
StreamingContext.setActiveContext(this)
}
}
}
JobScheduler
点开 scheduler.start() 就是 JobScheduler
def start(): Unit = synchronized {
if (eventLoop != null) return // scheduler has already been started
logDebug("Starting JobScheduler")
// EventLoop底层就是一个简单的 BlockQueue 实现的消息接受和通知调度器,
// 因为本身这些代码在Driver运行,所以不涉及到跨节点,所以也不涉及netty通信等
eventLoop = new EventLoop[JobSchedulerEvent]("JobScheduler") {
override protected def onReceive(event: JobSchedulerEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = reportError("Error in job scheduler", e)
}
// 关键 启动 事件调度,上面实现了 EventLoop 的抽象方法(有任务开始、任务完成、ERROR三个事件)
eventLoop.start()
// attach rate controllers of input streams to receive batch completion updates
for {
inputDStream <- ssc.graph.getInputStreams
rateController <- inputDStream.rateController
} ssc.addStreamingListener(rateController)
listenerBus.start()
receiverTracker = new ReceiverTracker(ssc)
inputInfoTracker = new InputInfoTracker(ssc)
val executorAllocClient: ExecutorAllocationClient = ssc.sparkContext.schedulerBackend match {
case b: ExecutorAllocationClient => b.asInstanceOf[ExecutorAllocationClient]
case _ => null
}
executorAllocationManager = ExecutorAllocationManager.createIfEnabled(
executorAllocClient,
receiverTracker,
ssc.conf,
ssc.graph.batchDuration.milliseconds,
clock)
executorAllocationManager.foreach(ssc.addStreamingListener)
receiverTracker.start()
// 关键 开启产生job 的调度
jobGenerator.start()
executorAllocationManager.foreach(_.start())
logInfo("Started JobScheduler")
}
private def processEvent(event: JobSchedulerEvent) {
try {
event match {
case JobStarted(job, startTime) => handleJobStart(job, startTime)
case JobCompleted(job, completedTime) => handleJobCompletion(job, completedTime)
case ErrorReported(m, e) => handleError(m, e)
}
} catch {
case e: Throwable =>
reportError("Error in job scheduler", e)
}
}
JobGenerator
def start(): Unit = synchronized {
if (eventLoop != null) return // generator has already been started
// Call checkpointWriter here to initialize it before eventLoop uses it to avoid a deadlock.
// See SPARK-10125
checkpointWriter
// 又是一个事件调度
eventLoop = new EventLoop[JobGeneratorEvent]("JobGenerator") {
override protected def onReceive(event: JobGeneratorEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = {
jobScheduler.reportError("Error in job generator", e)
}
}
eventLoop.start()
if (ssc.isCheckpointPresent) {
restart()
} else {
// 这边开启 产生批次的事件
startFirstTime()
}
}
//几个事件
private def processEvent(event: JobGeneratorEvent) {
logDebug("Got event " + event)
event match {
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time, clearCheckpointDataLater) =>
doCheckpoint(time, clearCheckpointDataLater)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}
// 我们关注主要流程 ,只需要关注产生 job
private def generateJobs(time: Time) {
// Checkpoint all RDDs marked for checkpointing to ensure their lineages are
// truncated periodically. Otherwise, we may run into stack overflows (SPARK-6847).
ssc.sparkContext.setLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS, "true")
Try {
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
// 这边是通过Graph产生
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
PythonDStream.stopStreamingContextIfPythonProcessIsDead(e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
此外什么时候发送产生批次的事件呢
ssc.graph.batchDuration.milliseconds 就是 new StreamContext的批次间隔时间 interval
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
RecurringTimer
开启线程
def start(startTime: Long): Long = synchronized {
nextTime = startTime
thread.start()
logInfo("Started timer for " + name + " at time " + nextTime)
nextTime
}
private val thread = new Thread("RecurringTimer - " + name) {
setDaemon(true)
override def run() { loop }
}
private def loop() {
try {
while (!stopped) {
triggerActionForNextInterval()
}
triggerActionForNextInterval()
} catch {
case e: InterruptedException =>
}
}
private def triggerActionForNextInterval(): Unit = {
//这边就是阻塞 有两中 clock,第一种是 SystemClock 是Thread.sleep
// 第二种是 ManualClock object.wait()
clock.waitTillTime(nextTime)
// 这个callback 就是 longTime => eventLoop.post(GenerateJobs(new Time(longTime)))
// 发送 GenerateJobs 事件
callback(nextTime)
prevTime = nextTime
nextTime += period
logDebug("Callback for " + name + " called at time " + prevTime)
}
DStreamGraph
//先找到 generateJobs 方法
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
outputStreams.flatMap { outputStream =>
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}
// 定位到 outputStreams
private val outputStreams = new ArrayBuffer[DStream[_]]()
// 定位向这个list 加DStream的方法
def addOutputStream(outputStream: DStream[_]) {
this.synchronized {
outputStream.setGraph(this)
outputStreams += outputStream
}
}
DStream
private[streaming] def register(): DStream[T] = {
ssc.graph.addOutputStream(this)
this
}
//最后是在调用ForeachRDD的时候加入进去
private def foreachRDD(
foreachFunc: (RDD[T], Time) => Unit,
displayInnerRDDOps: Boolean): Unit = {
new ForEachDStream(this,
context.sparkContext.clean(foreachFunc, false), displayInnerRDDOps).register()
}
官网上提供的几个输出方法也就是 Action 也就是间接触发DStream job 的方法

这些方法都是调用了 foreachRDD 方法,也就是间接触发Action
def print(num: Int): Unit = ssc.withScope {
def foreachFunc: (RDD[T], Time) => Unit = {
(rdd: RDD[T], time: Time) => {
val firstNum = rdd.take(num + 1)
// scalastyle:off println
println("-------------------------------------------")
println(s"Time: $time")
println("-------------------------------------------")
firstNum.take(num).foreach(println)
if (firstNum.length > num) println("...")
println()
// scalastyle:on println
}
}
foreachRDD(context.sparkContext.clean(foreachFunc), displayInnerRDDOps = false)
}
def saveAsObjectFiles(prefix: String, suffix: String = ""): Unit = ssc.withScope {
val saveFunc = (rdd: RDD[T], time: Time) => {
val file = rddToFileName(prefix, suffix, time)
rdd.saveAsObjectFile(file)
}
this.foreachRDD(saveFunc, displayInnerRDDOps = false)
}
DStreamGraph
再回到 generateJobs 方法,遍历所有通过ForeachRDD 加入的DStream,调用 generateJob 方法
def generateJobs(time: Time): Seq[Job] = {
logDebug("Generating jobs for time " + time)
val jobs = this.synchronized {
outputStreams.flatMap { outputStream =>
val jobOption = outputStream.generateJob(time)
jobOption.foreach(_.setCallSite(outputStream.creationSite))
jobOption
}
}
logDebug("Generated " + jobs.length + " jobs for time " + time)
jobs
}
DStream
这边的最后调用 getOrCompute 得到RDD,其实getOrCompute 继承的DStream 重写,例如调用map方法。第一个Dstream 是重写 compute 方法,getOrCompute 调用 compute
private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {
case Some(rdd) =>
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }
// 最最最最关键的地方 这边就提交了这个批次产生的RDD 也就是开始RDD的流程
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
case None => None
}
}
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// If RDD was already generated, then retrieve it from HashMap,
// or else compute the RDD
generatedRDDs.get(time).orElse {
// Compute the RDD if time is valid (e.g. correct time in a sliding window)
// of RDD generation, else generate nothing.
if (isTimeValid(time)) {
val rddOption = createRDDWithLocalProperties(time, displayInnerRDDOps = false) {
// Disable checks for existing output directories in jobs launched by the streaming
// scheduler, since we may need to write output to an existing directory during checkpoint
// recovery; see SPARK-4835 for more details. We need to have this call here because
// compute() might cause Spark jobs to be launched.
SparkHadoopWriterUtils.disableOutputSpecValidation.withValue(true) {
// 关键方法
compute(time)
}
}
rddOption.foreach { case newRDD =>
// Register the generated RDD for caching and checkpointing
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
generatedRDDs.put(time, newRDD)
}
rddOption
} else {
None
}
}
}
def map[U: ClassTag](mapFunc: T => U): DStream[U] = ssc.withScope {
new MappedDStream(this, context.sparkContext.clean(mapFunc))
}
MappedDStream
// 都是调用先调用 父DStream的 getOrCompute 方法。类似RDD,因为我是通过KafkaUtils创建的,所以第一个是DirectKafkaInputDStream。
private[streaming]
class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc) {
override def dependencies: List[DStream[_]] = List(parent)
override def slideDuration: Duration = parent.slideDuration
override def compute(validTime: Time): Option[RDD[U]] = {
// 这边的 .map(_.map[U](mapFunc)) 实际上是 rdd.map(mapFunc)
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
}
}
DirectKafkaInputDStream
这个方法没有重写 getOrCompute 而是重写 compute ,最返回 Some(RDD)
override def compute(validTime: Time): Option[KafkaRDD[K, V]] = {
val untilOffsets = clamp(latestOffsets())
val offsetRanges = untilOffsets.map { case (tp, uo) =>
val fo = currentOffsets(tp)
OffsetRange(tp.topic, tp.partition, fo, uo)
}
val useConsumerCache = context.conf.getBoolean("spark.streaming.kafka.consumer.cache.enabled",
true)
val rdd = new KafkaRDD[K, V](context.sparkContext, executorKafkaParams, offsetRanges.toArray,
getPreferredHosts, useConsumerCache)
// Report the record number and metadata of this batch interval to InputInfoTracker.
val description = offsetRanges.filter { offsetRange =>
// Don't display empty ranges.
offsetRange.fromOffset != offsetRange.untilOffset
}.map { offsetRange =>
s"topic: ${offsetRange.topic}\tpartition: ${offsetRange.partition}\t" +
s"offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}"
}.mkString("\n")
// Copy offsetRanges to immutable.List to prevent from being modified by the user
val metadata = Map(
"offsets" -> offsetRanges.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> description)
val inputInfo = StreamInputInfo(id, rdd.count, metadata)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
currentOffsets = untilOffsets
commitAll()
Some(rdd)
}
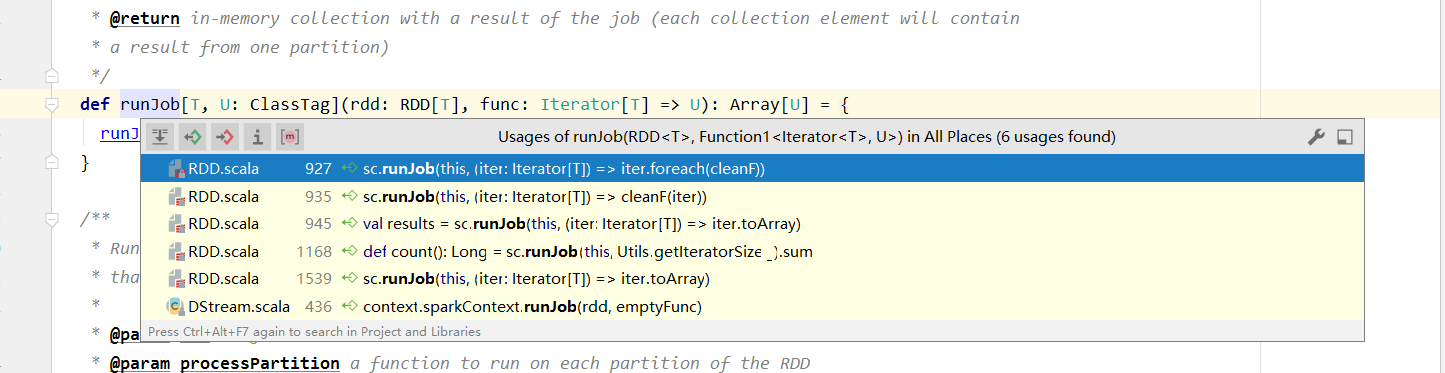
提交Job 地方


 浙公网安备 33010602011771号
浙公网安备 33010602011771号