

过滤条件之分组 group by、having、distinct、order by、limit、正则、多表查询和子查询、笛卡尔积
【一】过滤条件之分组 group by
【1】引入
-- 按照指定条件对所有数据进行分组
-- 对员工进行分组 按照年龄 / 部门
-- ...
select * from * where * group by *;
【2】按照部门分组
(1)查询数据
select * from emp group by post;
# 第一次使用部门分组会报错
mysql> select * from emp group by post;
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY...
(2)解决办法
-- 关闭严格模式
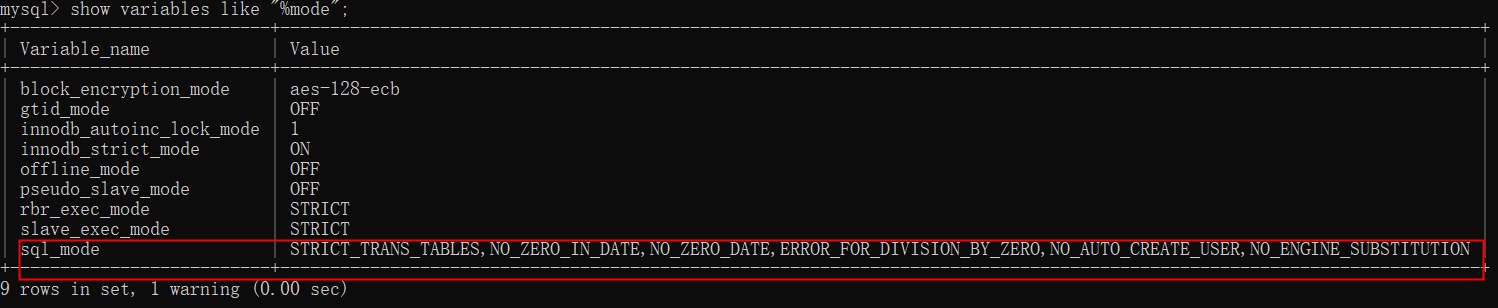
-- 首先模糊查询所有严格模式
show variables like "%mode";

-- 替换严格模式
-- 删除了 ONLY_FULL_GROUP_BY
set global sql_mode = 'STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
-- 重新进客户端,否则不生效
show variables like "%mode";
- 查询数据
select * from emp group by post;
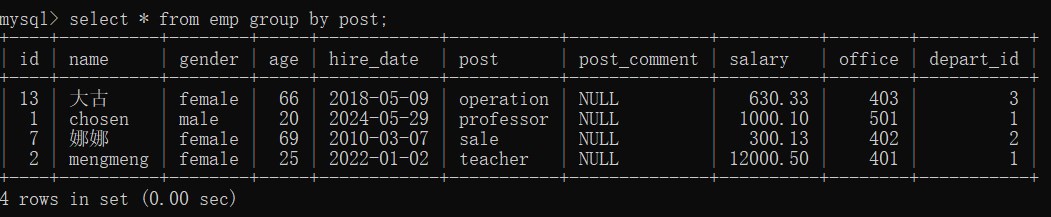
- 拿到每一个部门的第一行数据
【3】聚合函数
-- 聚合函数 ---》min / max / avg / count ...
-- 查询当前每个分组下的最高信息 max
select post,max(salary) from emp group by post;
# 输出结果
mysql> select post,max(salary) from emp group by post;
+-----------+-------------+
| post | max(salary) |
+-----------+-------------+
| operation | 630.33 |
| professor | 1000.10 |
| sale | 420.33 |
| teacher | 15000.99 |
+-----------+-------------+
【4】定制化字段显示内容
-- 有时候想自定制显示的信息
-- 定制化字段显示的内容
select post,max(salary) as "最高薪资" from emp group by post;
# 输出结果
mysql> select post,max(salary) as "最高薪资" from emp group by post;
+-----------+--------------+
| post | 最高薪资 |
+-----------+--------------+
| operation | 630.33 |
| professor | 1000.10 |
| sale | 420.33 |
| teacher | 15000.99 |
+-----------+--------------+
【5】查询每个部门下的最低薪资 min
select post,min(salary) as "最低薪资" from emp group by post;
# 输出结果
mysql> select post,min(salary) as "最低薪资" from emp group by post;
+-----------+--------------+
| post | 最低薪资 |
+-----------+--------------+
| operation | 330.62 |
| professor | 1000.10 |
| sale | 300.13 |
| teacher | 11000.80 |
+-----------+--------------+
【6】查询每个部门下的平均年龄avg
select post,avg(age) as "平均年龄" from emp group by post;
# 输出结果
mysql> select post,avg(age) as "平均年龄" from emp group by post;
+-----------+--------------+
| post | 平均年龄 |
+-----------+--------------+
| operation | 47.8000 |
| professor | 20.0000 |
| sale | 48.1667 |
| teacher | 29.8000 |
+-----------+--------------+
【7】查询每个部门下的总薪资sum
select post,sum(salary) as "总薪资" from emp group by post;
# 输出结果
mysql> select post,sum(salary) as "总薪资" from emp group by post;
+-----------+-----------+
| post | 总薪资 |
+-----------+-----------+
| operation | 2132.33 |
| professor | 1000.10 |
| sale | 2173.45 |
| teacher | 65003.61 |
+-----------+-----------+
【8】查询每个部门下的平均薪资avg
select post as "部门",avg(salary) as "平均薪资" from emp group by post;
# 输出结果
mysql> select post as "部门",avg(salary) as "平均薪资" from emp group by post;
+-----------+--------------+
| 部门 | 平均薪资 |
+-----------+--------------+
| operation | 426.466000 |
| professor | 1000.100000 |
| sale | 362.241667 |
| teacher | 13000.722000 |
+-----------+--------------+
【9】查询每个部门下的人数count
select post as '部门',count(id) as '总人数' from emp group by post;
# 输出结果
mysql> select post as '部门',count(id) as '总人数' from emp group by post;
+-----------+-----------+
| 部门 | 总人数 |
+-----------+-----------+
| operation | 5 |
| professor | 1 |
| sale | 6 |
| teacher | 5 |
+-----------+-----------+
- count 函数不能对 null 进行计数
-- count 函数不能对 null 进行计数 ,计数为 0
select post,count(post_comment) as "总人数" from emp group by post;
# 输出结果
mysql> select post,count(post_comment) as "总人数" from emp group by post;
+-----------+-----------+
| post | 总人数 |
+-----------+-----------+
| operation | 0 |
| professor | 0 |
| sale | 0 |
| teacher | 0 |
+-----------+-----------+
【10】查询分组之后的部门名称和每个部门下所有的员工姓名(group_concat)
-- 查询分组之后的部门名称以及每个部门下的所有成员的名字
-- group_concat : 获取到分组之后具体的字段的值
select post,group_concat(name) from emp group by post;
select post,group_concat(name) as "人员名单" from emp group by post;
# 输出结果
mysql> select post,group_concat(name) as "人员名单" from emp group by post;
+-----------+-------------------------------------------+
| post | 人员名单 |
+-----------+-------------------------------------------+
| operation | 大古,张三,李四,王五,赵六 |
| professor | chosen |
| sale | 娜娜,芳芳,小明,亚洲,华华,田七 |
| teacher | mengmeng,xiaomeng,xiaona,xiaoqi,suimeng |
+-----------+-------------------------------------------+
-- group_concat :不仅仅只是能获取当前分组下的所有数据还可以支持字符串拼接操作.
select post,group_concat(name,'_saler') as "人员名单" from emp group by post;
# 输出结果
mysql> select post,group_concat(name,'_saler') as "人员名单" from emp group by post;
+-----------+-------------------------------------------------------------------------------+
| post | 人员名单 |
+-----------+-------------------------------------------------------------------------------+
| operation | 大古_saler,张三_saler,李四_saler,王五_saler,赵六_saler |
| professor | chosen_saler |
| sale | 娜娜_saler,芳芳_saler,小明_saler,亚洲_saler,华华_saler,田七_saler |
| teacher | mengmeng_saler,xiaomeng_saler,xiaona_saler,xiaoqi_saler,suimeng_saler |
+-----------+-------------------------------------------------------------------------------+
-- 支持查询个人的多条数据
select post,group_concat(name,'_saler','|',salary) as "人员名单" from emp group by post;

【11】查询数据(不分组之前用 concat)
-- group_concat:必须分组之后才能使用,否则会乱掉
select group_concat("NAME:",name) as "姓名",age from emp;
-- concat :不分组的情况下对每一个字段进行定制
select concat("NAME:",name)as "姓名",age from emp;
-- 只能按照单个字段进行取值,不允许使用 * 代替后面的所有字段,否则会报错。
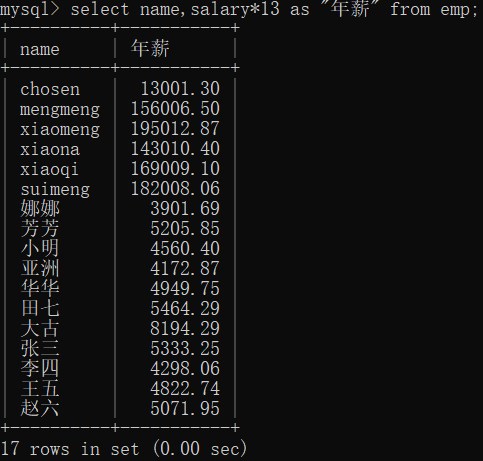
【12】每一个人一年 13薪的薪资
-- 如果想要查询每一个人一年 13薪的薪资
select name,salary*13 as "年薪" from emp;
【13】where 和 group by
(1)关键字 where 和 group by 同时出现
-
关键字 where 和 group by 同时出现的时候,group by 必须在 where 后面
-
- where 先对整体数据进行过滤
- group by 再对数据进行分组
(2)where 删选条件不能使用聚合函数
-
where 筛选条件不能使用聚合函数
-
- 不分组,默认整张表就是一组
-
聚合函数只能在分组之后使用
-
- 查询数据
select id,name,age from emp where max(salary)>3000;
# 报错
-- ERROR 1111 (HY000): Invalid use of group function
-- 查询数据
select max(salary) from emp;
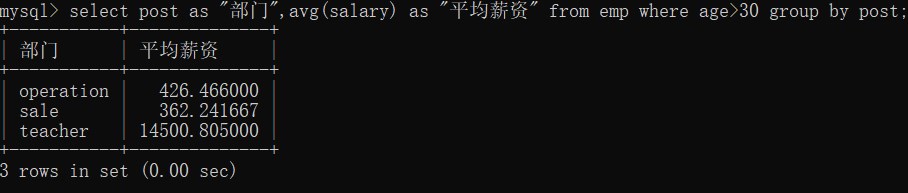
【14】统计各部门年龄在 30 岁以上的员工的平均薪资
-- 统计各部门年龄在 30 岁以上的员工的平均薪资
-- 统计各部门 分组
-- 年龄在 30 岁以上 过滤
-- 平均薪资 聚合函数 avg
-- 先过滤30岁以上的人
select * from emp where age>30;
-- 在对 30 岁以后的人进行分组
select * from emp where age>30 group by post;
-- 在对 30 岁以后的人进行分组 计算平均薪资
select post as "部门",avg(salary) as "平均薪资" from emp where age>30 group by post;
【二】过滤条件之having
-
having与where的功能是一模一样的 都是对数据进行筛选
-
- where用在分组之前的筛选
- havng用在分组之后的筛选
-
只不过having是在分组之后进行的过滤操作
-
即having是可以直接使用聚合函数的
-- 统计各部门年龄在30岁以上的员工的工资
-- 并且保留平均薪资大于1W的部门
-- 统计各部门 分组
-- 在 30 岁以上的员工 where 过滤
-- 平均薪资大于1w avg(salary)>10000
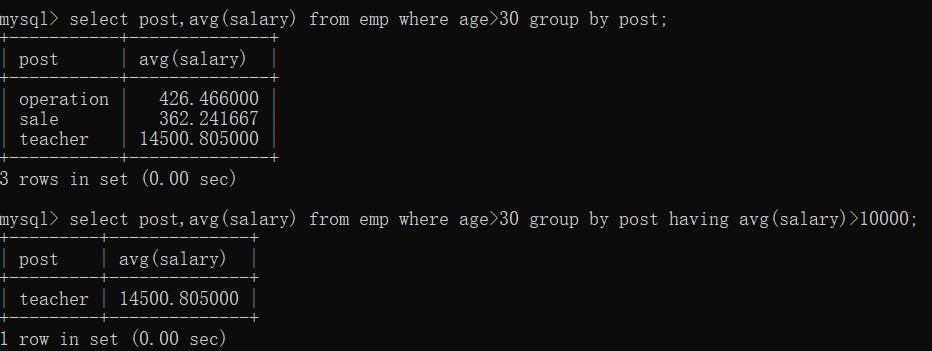
select post,avg(salary) from emp where age>30 group by post;
-- having:分组之后再进行筛选
select post,avg(salary) from emp where age>30 group by post having avg(salary)>10000;
【三】过滤条件之去重 distinct
- 必须是完全一样的数据才可以去重
- 一定要注意主键的问题
- 在主键存在的情况下是一定不可能去重的
-- 将该字段下的重复的数据进行去重 --- 集合
-- 我们的表中的主键ID 自增 唯一 不为空
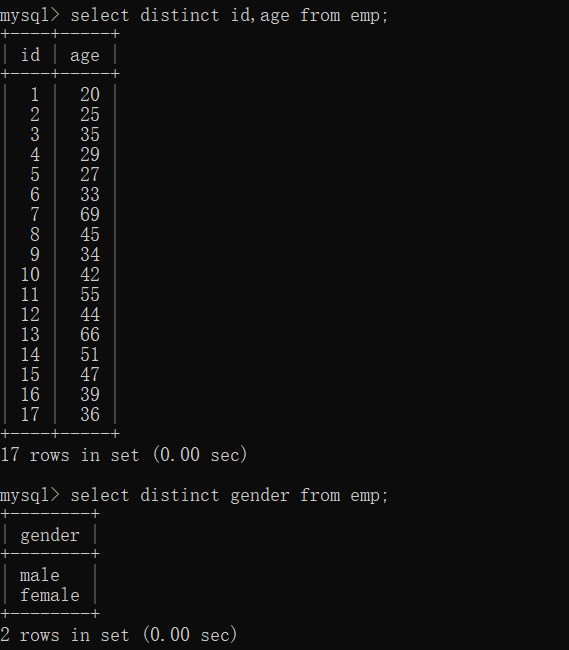
select distinct id,age from emp;
-- 去除一样的数据 ---> 去除除主键外的数据
select distinct gender from emp;
【四】过滤条件之排序 order by
- order by : 默认是升序
- asc 默认可以省略不写 ---> 修改降序
- desc : 降序
-- 将表中的薪资按照从小到大排序:升序
select * from emp order by salary;
-- 降序
select * from emp order by salary desc;

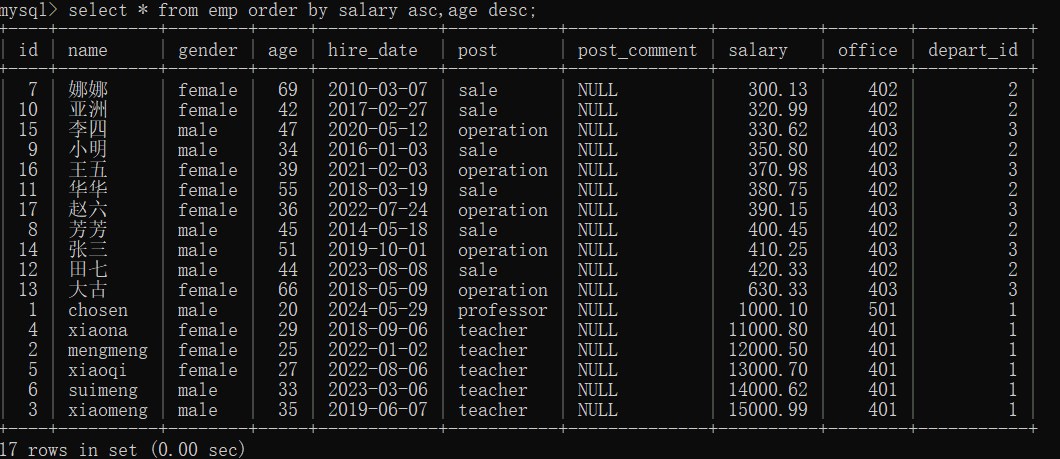
-- 按照薪资(升序)和年龄(降序)排序
select * from emp order by salary asc,age desc;
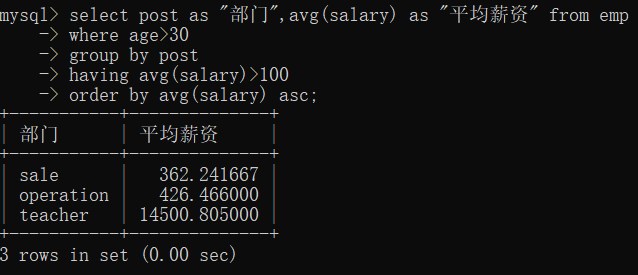
-- 统计各部门年龄在 30 岁以上的员工的工资
-- 并且保留平均薪资大于100的部门
-- 对平均工资进行排序
select post as "部门",avg(salary) as "平均薪资" from emp
where age>30
group by post
having avg(salary)>100
order by avg(salary) asc;
【五】过滤条件之限制数据量 limit
-- 限制获取到的数据的前10条
select * from emp limit 10;
-- 增加额外的参数进行限制,实现分页的效果
-- 索引位置是从0开始的
-- limit 索引位置,数据量
-- 从索引第6的位置开始获取数据,获取后5条数据(不顾头,顾尾)
select * from emp limit 5,5;
-- 从索引第7的位置开始获取数据,获取后10条数据;
select * from emp limit 6,10;
-- 查询工资最高的人的详细信息
select * from emp order by salary desc;
-- 只要最高的那个人的信息
select * from emp order by salary desc limit 1;

【六】过滤条件之正则表达式
DROP TABLE IF EXISTS person;
create table person(
name varchar(32) character set utf8 collate utf8_general_ci null default null,
age int(40) null default null,
heigh int(40) null default null,
sex varchar(255) character set utf8 collate utf8_general_ci null default null
) engine = InnoDB character set = utf8 collate = utf8_general_ci row_format = Dynamic;
INSERT INTO `person` VALUES ('Thomas ', 25, 168, '男');
INSERT INTO `person` VALUES ('Tom ', 20, 172, '男');
INSERT INTO `person` VALUES ('Dany', 29, 175, '男');
INSERT INTO `person` VALUES ('Jane', 27, 171, '男');
INSERT INTO `person` VALUES ('Susan', 24, 173, '女');
INSERT INTO `person` VALUES ('Green', 25, 168, '女');
INSERT INTO `person` VALUES ('Henry', 21, 160, '女');
INSERT INTO `person` VALUES ('Lily', 18, 190, '男');
INSERT INTO `person` VALUES ('LiMing', 19, 187, '男');
| 选项 | 说明 | 例子 | 匹配值示例 |
|---|---|---|---|
| ^ | 匹配文本的开始字符 | ‘^b’ 匹配以字母 b 开头的字符串 | book、big、banana、bike |
| $ | 匹配文本的结束字符 | ‘st$’ 匹配以 st 结尾的字符串 | test、resist、persist |
| . | 匹配任何单个字符 | ‘b.t’ 匹配任何 b 和 t 之间有一个字符 | bit、bat、but、bite |
| * | 匹配前面的字符 0 次或多次 | ‘f*n’ 匹配字符 n 前面有任意个字符 f | fn、fan、faan、abcn |
| + | 匹配前面的字符 1 次或多次 | ‘ba+’ 匹配以 b 开头,后面至少紧跟一个 a | ba、bay、bare、battle |
| ? | 匹配前面的字符 0 次或1次 | ‘sa?’ 匹配0个或1个a字符 | sa、s |
| 字符串 | 匹配包含指定字符的文本 | ‘fa’ 匹配包含‘fa’的文本 | fan、afa、faad |
| [字符集合] | 匹配字符集合中的任何一个字符 | ‘[xz]’ 匹配 x 或者 z | dizzy、zebra、x-ray、extra |
| [^] | 匹配不在括号中的任何字符 | ‘[^abc]’ 匹配任何不包含 a、b 或 c 的字符串 | desk、fox、f8ke |
| 字符串 | 匹配前面的字符串至少 n 次 | ‘b{2}’ 匹配 2 个或更多的 b | bbb、bbbb、bbbbbbb |
| 字符串 | 匹配前面的字符串至少 n 次, 至多 m 次 | ‘b{2,4}’ 匹配最少 2 个,最多 4 个 b | bbb、bbbb |
-- 查询 name 字段以j开头的记录
select * from person where name regexp '^j';
-- 查询 name 字段以“y”结尾的记
select * from person where name REGEXP 'y$';
-- 查询 name 字段值包含“a”和“y”,且两个字母之间只有一个字母的记录
select * from person where name REGEXP 'a.y';
-- 查询 name 字段值包含字母“T”,且“T”后面出现字母“h”的记录
select * from person where name REGEXP 'Th*';
-- 查询 name 字段值包含字母“T”,且“T”后面至少出现“h”一次的记录
select * from person where name REGEXP 'Th+';
-- 查询 name 字段值包含字母“S”,且“S”后面出现“a”一次或零次的记录
select * from person where name REGEXP 'sa?';
【七】多表查询和子查询
-- 多表查 又称为连表查询 多张表放到一起去查询数据
-- 员工表和部门表 : 把员工表和部门表合并成一张表 ---> 在合并后的表中查询数据
id name dep_id dep_name desc
1 chosen 1 cook 后勤
-- 子查询
-- 先查一条数据,将这条数据的结果作为下一条查询语句的起始
-- 先在员工表中查询数据 查询 dream 的dep_id
员工表
# id name dep_id
1 dream 1
-- 再拿着上面的dep_id 在部门表中查询到 name
# 部门表
id name desc
1 后勤 后勤
create table dep(
id int PRIMARY KEY AUTO_INCREMENT,
name varchar(20)
);
create table emp_two (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
sex enum("male","female") NOT NULL default "male",
age INT,
dep_id INT
);
insert into dep values
("200","技术部"),
("201","人力资源"),
("202","销售部"),
("203","运营部"),
("204","售后部");
insert into emp_two(name,sex,age,dep_id) values
("chosen","male",18,200),
("max","female",18,201),
("menmgneg","male",38,202),
("hope","male",18,203),
("own","male",28,204),
("thdream","male",18,205);
-- 获取员工chosen所在的部门名称
-- 先在员工表中获取到当前员工对应的部门ID
select dep_id from emp_two where name="chosen";
-- 再根据部门ID去部门表中查询部门名称
select name from dep where id =200;
-- 结合
select name from dep where id =(select dep_id from emp_two where name="chosen");
# 输出结果
mysql> select name from dep where id =(select dep_id from emp_two where name="chosen");
+-----------+
| name |
+-----------+
| 技术部 |
+-----------+
-- 根据部门ID去查当前这个人的详细信息
select id from dep where name="技术部";
select * from emp_two where dep_id in(select id from dep where name="技术部");
# 输出结果
mysql> select * from emp_two where dep_id in(select id from dep where name="技术部");
+----+--------+------+------+--------+
| id | name | sex | age | dep_id |
+----+--------+------+------+--------+
| 1 | chosen | male | 18 | 200 |
+----+--------+------+------+--------+
【八】笛卡尔积
- 在SQL中,当我们使用JOIN操作将两个或更多的表连接在一起时,结果集中的行数是所有连接表的行数的乘积。这就是所谓的笛卡尔积。
- 例如,假设我们有两个表A和B,其中A有5行,B有3行。
- 如果我们使用INNER JOIN将这两个表连接起来,那么结果集中将会有5 x 3 = 15行。
- 这是因为对于每一行A,我们可以从B中选择任意一行进行匹配。
- 因此,总共有5种不同的方式来组合A表中的每一行和B表中的每一行,这导致了最终结果集的大小为5 x 3 = 15。
- 这个过程就是笛卡尔积,它是数学中的一种运算,用于计算两个集合的所有可能的元素组合的数量。
- 在这个情况下,每个元素都是一个表格中的行。
- 所以,当我们在MySQL中使用JOIN操作时,结果集的大小实际上是所有连接表的行数的乘积,这就是为什么我们称其为笛卡尔积的原因。
-- 根据笛卡尔积进行品表 一共有 30 行数据
select * from dep,emp_two;
-- 基于笛卡尔积进行品表
-- 再对品表进行过滤
-- 员工表中的部门ID=部门表中ID 的数据
-- 拼接数据过滤的时候必须是二者ID相等才会被保留
select * from dep,emp_two where emp_two.dep_id = dep.id;
# 输出结果
mysql> select * from dep,emp_two where emp_two.dep_id = dep.id;
+-----+--------------+----+----------+--------+------+--------+
| id | name | id | name | sex | age | dep_id |
+-----+--------------+----+----------+--------+------+--------+
| 200 | 技术部 | 1 | chosen | male | 18 | 200 |
| 201 | 人力资源 | 2 | max | female | 18 | 201 |
| 202 | 销售部 | 3 | menmgneg | male | 38 | 202 |
| 203 | 运营部 | 4 | hope | male | 18 | 203 |
| 204 | 售后部 | 5 | own | male | 28 | 204 |
+-----+--------------+----+----------+--------+------+--------+
【九】多表查询和子查询(案例)
-- 内连接 inner join 并集
-- 只有两张表都有的数据才会被保留
-- 左连接 left join
-- 只有左面表都有的数据才会被保留
-- 右连接 right join
-- 只有右面表都有的数据才会被保留
-- 全连接 left join... union right join ...;
-- 两张表不管有没有全都拼上去
-- 内连接 inner join
select * from dep inner join emp_two on emp_two.dep_id = dep.id;
# 输出结果
mysql> select * from dep inner join emp_two on emp_two.dep_id = dep.id;
+-----+--------------+----+----------+--------+------+--------+
| id | name | id | name | sex | age | dep_id |
+-----+--------------+----+----------+--------+------+--------+
| 200 | 技术部 | 1 | chosen | male | 18 | 200 |
| 201 | 人力资源 | 2 | max | female | 18 | 201 |
| 202 | 销售部 | 3 | menmgneg | male | 38 | 202 |
| 203 | 运营部 | 4 | hope | male | 18 | 203 |
| 204 | 售后部 | 5 | own | male | 28 | 204 |
+-----+--------------+----+----------+--------+------+--------+
-- 左连接 left join
select * from dep left join emp_two on emp_two.dep_id = dep.id;
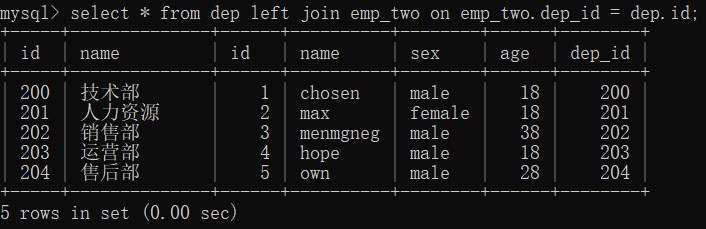
-- 右连接 right join
select * from dep right join emp_two on emp_two.dep_id = dep.id;
-- 全连接 left join... union right join ...;
select * from dep left join emp_two on emp_two.dep_id = dep.id union select * from dep right join emp_two on emp_two.dep_id = dep.id;
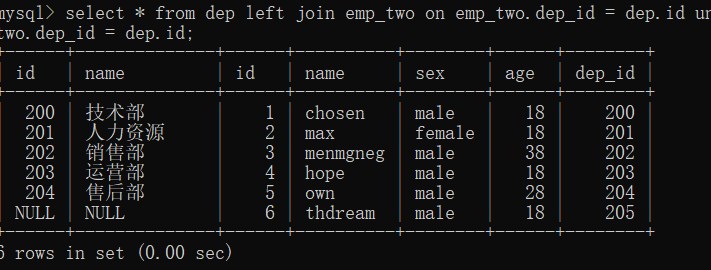
-- 查询平均年龄在25岁以上的部门名称
-- 方案一:
-- 先查员工表 分组 取均值 过滤 剩下部门ID
select dep_id from emp_two group by dep_id having avg(age)>25;
-- 再去部门表中根据部门ID查部门名称
select * from dep where id in (select dep_id from emp_two group by dep_id having avg(age)>25);
# 输出结果
+-----+-----------+
| id | name |
+-----+-----------+
| 202 | 销售部 |
| 204 | 售后部 |
+-----+-----------+
-- 方案二:联表查
-- 先拼表 ---> 过滤 在计算
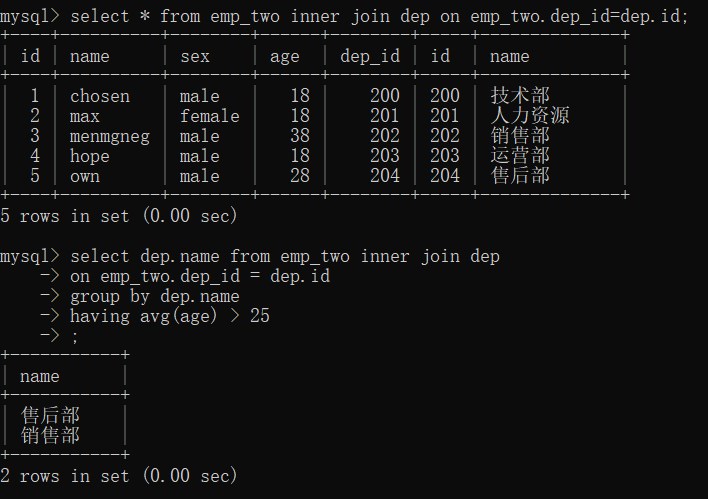
select * from emp_two inner join dep on emp_two.dep_id=dep.id;
select dep.name from emp_two inner join dep
on emp_two.dep_id = dep.id
group by dep.name
having avg(age) > 25
;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!