

约束条件补充、主键和外键约束、过滤条件(查询语法)
【一】约束条件补充
-- 【一】什么是约束条件
-- 约束条件就是为了限制表中的数据,保证数据的准确性和可靠性而存在的限制规则
-- 在创建表和字段的时候,约束条件是可有可无的,但是某些情况下为了约束数据的准确所以要必须加约束条件
-- 【二】约束条件概览
-- 【1】null 和 not null 空和不为空
-- 【2】unsigned 限制整数类型必须大于等于0
-- 【3】zerofill 默认用0填充至指定的数据长度
-- 【4】unique 唯一性,数据只能出现一次
-- 【5】primary key 主键 增加查询效率
-- 【6】foreign key 外键 一张表和另一张表的字段之间的关联关系
【1】not null + unique
-- not null + unique 不为空且唯一就构成了主键 primary key
# 创建表
create table user(
id int(4) primary key,
name varchar(32) not null,
gender enum('male','female'),
hobby set('read','play','study')
);
# 查看表的详细数据
desc user;
# 查看结果
+--------+----------------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+----------------------------+------+-----+---------+-------+
| id | int(4) | NO | PRI | NULL | |
| name | varchar(32) | NO | | NULL | |
| gender | enum('male','female') | YES | | NULL | |
| hobby | set('read','play','study') | YES | | NULL | |
+--------+----------------------------+------+-----+---------+-------+
【二】主键约束
【1】名词解释
- 主键约束
- 表中某个字段添加主键约束之后,该字段被称为主键字段。
- 主键值
- 主键字段中出现的每一个数据都被称为主键值。
- 主键字段
- 添加了主键规则的字段就叫主键字段
【2】主键的作用
-
添加主键 primary key的字段既不能重复也不能为空,效果与not null + unique相同,但本质是不同的。
-
添加主键约束之后,主键不仅会有 not null + unique 作用,而且主键字段还会自动添加 索引 —— index
-
myisam引擎 ---》表结构文件自带了一个索引文件
-
一张表应该有主键,若没有,表示这张表是无效的。
-
“主键值”是当前行 数据的唯一标识,“主键值”可以是当前行数据的身份证号;(即使表中两行数据完全相同,但是由于主键不同,我们也认为这是两行完全不同的数据)
【3】单一主键:列级约束
- 给一个字段添加一个主键约束,被称为单一主键
# 创建表
create table user(
id int(10) primary key,
name varchar(32)
);
【4】单一主键:表级约束
create table user(
id int(10),
name varchar(32),
primary key(id)
);
- 给主键重命名
# 给主键重命名
create table user(
id int(10),
name varchar(32),
constraint user_id_pk primary key(id)
);
【5】复合主键:给整张表添加约束
# 创建表
# 复合主键,表级约束,并且给其重命名
create table t_user(
id int(10),
name varchar(32),
address varchar(32),
constraint user_id_name_pk primary key(id,name)
);
【6】按照性质分类
- 自然主键:主键值若是一个自然数,并且这个自然数与业务没有任何关系,这种主键称为自然主键;
- 业务主键:主键值若和当前表中的业务紧密相关,那么这种主键值被业务主键;如果业务发生改变时,业务主键往往会受到影响,所以业务主键使用较少,大多情况使用自然主键。
【7】自动生成主键
- MySQL中自动生成主键值(使用自增字段auto_increment)
- MySQL数据库管理系统中提供了一个自增数字,专门用来自动生成主键值,主键值不需要用户去维护,也不需要用户生成,MySQL会自动生成。
- 自增数字默认从1开始,以1递增:1、2、3、
drop table if exists t_user;
# 创建表
create table t_user(
id int(10) primary key auto_increment,
name varchar(32)
);
# 插入表数据
insert into t_user(name) values('chosen'),('max'),('tom');
# 查看表数据
select * from t_user;
# 由于字段 id 设置自增字段(auto_increment),所以不用特意添加id
# 会在我们赋值 name 的时候自动增加id。
# 输出结果
+----+--------+
| id | name |
+----+--------+
| 1 | chosen |
| 2 | max |
| 3 | tom |
+----+--------+
- 自动生成后,一个主键自然数只能出现一次,若删除该行记录,重新递增记录时,主键自然数会跳过,直接+1.
# 删除一条数据
delete from t_user where id=2;
# 输出结果
mysql> select * from t_user;
+----+--------+
| id | name |
+----+--------+
| 1 | chosen |
| 3 | tom |
+----+--------+
# 插入数据
insert into t_user(name) values('opp');
# 查看表数据
select * from t_user;
# 输出结果
mysql> select * from t_user;
+----+--------+
| id | name |
+----+--------+
| 1 | chosen |
| 3 | tom |
| 4 | opp |
+----+--------+
(1)重置主键起始位置
# 方式一
-- truncate 表名
-- 会将表中的所有数据清空并重置
truncate t_user;
# 查看表数据会发现表数据已经被清空
select * from t_user;
mysql> select * from t_user;
Empty set (0.00 sec)
# 插入表数据
insert into t_user(name) values('chosen');
# 查看数据
mysql> select * from t_user;
+----+--------+
| id | name |
+----+--------+
| 1 | chosen |
+----+--------+
# 重置成功
# 方式二
-- 指定主键起始位置
-- alter table 表名 AUTO_INCREMENT = 指定主键起始位置;
-- 只能修改从当前已有最后的ID之后的起始ID 的位置,不能修改前面的其实ID
# 查看表数据
mysql> select * from t_user;
+----+--------+
| id | name |
+----+--------+
| 1 | chosen |
| 3 | tom |
| 4 | opp |
+----+--------+
# 重置起始位置
alter table t_user AUTO_INCREMENT=6;
# 插入数据
insert into t_user(name) values('damn');
# 查看表数据
mysql> select * from t_user;
+----+--------+
| id | name |
+----+--------+
| 1 | chosen |
| 3 | tom |
| 4 | opp |
| 6 | damn |
+----+--------+
# 重置成功
【三】外键约束
【1】引入
- 假设现在一张员工表,员工表内有下述字段
id name age dep_name dep_desc
- 但是从上面看有很大的缺陷
- 表中某些字段对应的数据一直在重复
- 表的扩展性极差,如果要改其中一个数据,就要全改。
- 解决方法
- 将一张表,一分为二
- 员工表,部门表
-- 分一个员工表
id name age dep_id
1 chosen 18 1
2 max 20 2
-- 分一个部门表
id dep_name
1 维修部
2 后勤部
-
拆表后,员工与部门之间没有了绑定关系
-
解决办法
- 在员工表中添加一个部门编号字段与部门表中的主键字段对应
-
一张表中的字段和另一张表中的字段建立联系后,这个字段就是外键字段
【2】外键 约束/字段/值
-- [1] 外键约束
-- 给字段增加的外键约束的规则就叫外键约束
-- [2] 外键字段
-- 给字段增加了外键约束的字段就叫外键字段
-- [3] 外键值
-- 外键字段对应的值就叫外键值
【3】外键关系
- 一对一
- 一对多
- 多对多
【4】外键约束创建的语法
-- 先创建表1
create table 表名1(
字段名1 字段类型1 约束条件1 comment 注释1,
字段名2 字段类型2 约束条件2 comment 注释2,
);
-- 再创建表2
-- 在表2中给指定外键关系
create table 表名2(
字段名1 字段类型1 约束条件1 comment 注释1,
字段名2 字段类型2 约束条件2 comment 注释2,
-- foreign key 自己的外键字段 references 被关联的表名 需要关联的外键字段 字段名1
foreign key(在表名2中显示的字段名,字段名2) references 表名1(表明1中需要建立外键关系的字段名)
);
【5】一对多外键关系
(1)理论分析
-- 员工表和部门表
-- 一个员工可以从事多个部门吗? 不可以
-- 一个部门可以有多个员工吗? 可以
-- 所以部门和员工的关系是 一对多
(2)建表思路
-- 分清谁和谁关联 ---》分清谁先被创建
-- 部门表先被创建
-- comment 给字段增加注解
create table dep(
id int primary key auto_increment comment '编号',
dep_name varchar(32) comment '部门名称',
dep_desc varchar(32) comment '部门简介'
);
mysql> desc dep;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| dep_name | varchar(32) | YES | | NULL | |
| dep_desc | varchar(32) | YES | | NULL | |
+----------+-------------+------+-----+---------+----------------+
-- 有了部门表以后才能创建员工表并且员工和部门绑定
-- 在创建表字段的时候也可以给每个字段添加中文注释
create table emp(
id int primary key auto_increment comment '编号',
name varchar(32) comment '姓名',
age int comment '年龄',
dep_id int comment '部门编号',
foreign key(dep_id) references dep(id)
);
mysql> desc emp;
+--------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| name | varchar(32) | YES | | NULL | |
| age | int(11) | YES | | NULL | |
| dep_id | int(11) | YES | MUL | NULL | |
+--------+-------------+------+-----+---------+----------------+
-- 插入数据
-- 向部门表中插入数据
insert into dep(dep_name,dep_desc) values("cook","后勤部门");
insert into dep(dep_name,dep_desc) values("test","测试部门");
-- 向员工表中插入数据,不带外键字段
insert into emp(name,age) values("chosen",18);
-- 向员工表中插入数据,携带部门表中存在的部门ID
insert into emp(name,age,dep_id) values("chosen",18,1);
-- 向员工表中插入数据,,携带部门表中不存在的部门ID则会报错
insert into emp(name,age,dep_id) values("opp",38,3);
【6】级联更新和级联删除
● 添加级联更新和级联删除时需要在外键约束后面添加
● 在删除父表中的数据时,级联删除子表中的数据 on delete cascade
● 在更新父表中的数据时,级联更新子表中的数据 on update cascade
● 以上的级联更新和级联删除谨慎使用,因为级联操作会将数据改变或删除【数据无价】
● 在修改约束条件时,建议可以将原先的约束删除再重新添加约束条件
-- 创建部门表
create table dep1(
id int primary key auto_increment comment '编号',
dep_name varchar(32) comment '部门名称',
dep_desc varchar(32) comment '部门描述'
);
-- 创建员工表
create table emp1(
id int primary key auto_increment comment '编号',
name varchar(32) comment '姓名',
age int comment '年龄',
dep_id int comment '部门编号',
foreign key(dep_id) references dep1(id)
on update cascade # 级联更新
on delete cascade # 级联删除
);
-- 向部门表中插入数据
insert into dep1(dep_name,dep_desc) values("cook","后勤部门");
insert into dep1(dep_name,dep_desc) values("test","测试部门");
-- 向员工表中插入数据,不带外键字段
insert into emp1(name,age) values("chosen",18);
-- 向员工表中插入数据,携带部门表中存在的部门ID
insert into emp1(name,age,dep_id) values("max",20,1);
-- 级联更新,如果更新被关联的数据表中的数据,关联表中的数据随之修改
update dep1 set id=10 where id=1;
# 输出结果
mysql> select * from dep1;
+----+----------+--------------+
| id | dep_name | dep_desc |
+----+----------+--------------+
| 2 | test | 测试部门 |
| 10 | cook | 后勤部门 |
+----+----------+--------------+
# 查 emp1关联的数据变化
mysql> select * from emp1;
+----+--------+------+--------+
| id | name | age | dep_id |
+----+--------+------+--------+
| 1 | chosen | 18 | NULL |
| 2 | max | 20 | 10 |
+----+--------+------+--------+
-- 如果删除被关联表中的数据,关联表中的数据也会随之删除
delete from dep1 where id=10;
# 查 emp1关联的数据变化
mysql> select * from emp1;
+----+--------+------+--------+
| id | name | age | dep_id |
+----+--------+------+--------+
| 1 | chosen | 18 | NULL |
+----+--------+------+--------+
【7】多对多外键关系
(1)理论分析
-- 【1】理论分析
-- 图书表和作者表
-- 一本书可以有多个作者? 能
-- 一个作者可以写多本书? 能
-- 所以图书和作者之间就是多对多关系
(2)建表思路
-- 创建表的时候按照一对多的思路是创建没有关联外键字段的那张表
-- 因为多对多关系两张表都各自需要被关联
-- 创建图书表
create table book(
id int primary key auto_increment,
title varchar(32),
price float(10,2)
);
-- 创建作者表
create table author(
id int primary key auto_increment,
name varchar(32),
gender enum('male','female','others')
);
-- 针对的是多对多关系 需要开设第三张表来存储响应的数据
create table book_author(
id int primary key auto_increment,
author_id int,
book_id int,
foreign key(author_id) references author(id),
on update cascade # 级联更新
on delete cascade # 级联删除
);
【8】一对一外键关系
-- 理论分析
-- 个人和个人详细信息
-- 一个人只能有一个详细信息
-- 一个详细信息只能对应一个人
-- 外键关系建立在谁身上?
-- 如果是一对一关系,建立在任何一方都没有问题
-- 但是建议建立在使用频次较高的一方
-- 个人表使用频率较高,建议建立在个人表中
-- 个人表
id name gender user_detail_id
-- 个人详情表
id phone age
create table userdetail(
id int primary key auto_increment,
phone bigint,
age int
);
create table user(
id int primary key auto_increment,
name varchar(32),
gender enum('male','female'),
user_detail_id int unique,
foreign key(user_detail_id) references userdetail(id)
on update cascade # 级联更新
on delete cascade # 级联删除
);
【补充】如何查看当前表中的字段限制
-- 查看所有数据库
show databases;
-- 切换到表结构数据库
use information_schema;
-- 查看当前数据下的所有表
show tables;
-- table_constraints 专门用来存储字段约束信息
desc table_constraints;
-- 查看指定表的约束信息
select constraint_name from table_constraints where table_name='表名';
【四】过滤条件
【1】标准的查询语句语法
select */字段名 from */表名 where */字段名=字段值;
# 例如
select * from user where id=1;
-- 执行顺序
from 起手 知道是那张表
where 根据过滤条件在表中过滤数据
select 再过滤出自己想要的数据
* 全部数据
【2】准备数据
-- 创建数据库
drop table if exists emp_data;
create database emp_data;
-- 切换数据库
use emp_data;
-- 创建表
create table emp(
id int primary key auto_increment,
name varchar(32) not null,
gender enum('male','female') default 'male',
age int(3) unsigned not null default 26,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int,
depart_id int
);
-- 插入数据
insert into emp(name,gender,age,hire_date,post,salary,office,depart_id) values
("chosen","male",20,'2024-05-29','professor',1000.10,501,1),
# 以下是教学部
("mengmeng", "female", 25, '20220102', "teacher", 12000.50, 401, 1),
("xiaomeng", "male", 35, '20190607', "teacher", 15000.99, 401, 1),
("xiaona", "female", 29, '20180906', "teacher", 11000.80, 401, 1),
("xiaoqi", "female", 27, '20220806', "teacher", 13000.70, 401, 1),
("suimeng", "male", 33, '20230306', "teacher", 14000.62, 401, 1),
# 以下是销售部
("娜娜", "female", 69, '20100307', "sale", 300.13, 402, 2),
("芳芳", "male", 45, '20140518', "sale", 400.45, 402, 2),
("小明", "male", 34, '20160103', "sale", 350.80, 402, 2),
("亚洲", "female", 42, '20170227', "sale", 320.99, 402, 2),
("华华", "female", 55, '20180319', "sale", 380.75, 402, 2),
("田七", "male", 44, '20230808', "sale", 420.33, 402, 2),
# 以下是运行部
("大古", "female", 66, '20180509', "operation", 630.33, 403, 3),
("张三", "male", 51, '20191001', "operation", 410.25, 403, 3),
("李四", "male", 47, '20200512', "operation", 330.62, 403, 3),
("王五", "female", 39, '20210203', "operation", 370.98, 403, 3),
("赵六", "female", 36, '20220724', "operation", 390.15, 403, 3);
【3】关键字 where
- 对整体的数据进行初步筛选
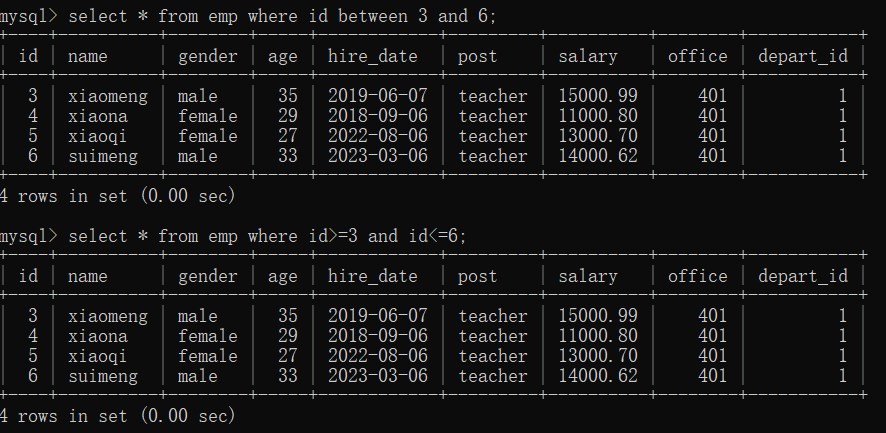
(1)查询 id >=3 并且 id <= 6的数据
# 方式一
select * from emp where id between 3 and 6;
# 方式二
select * from emp where id>=3 and id<=6;
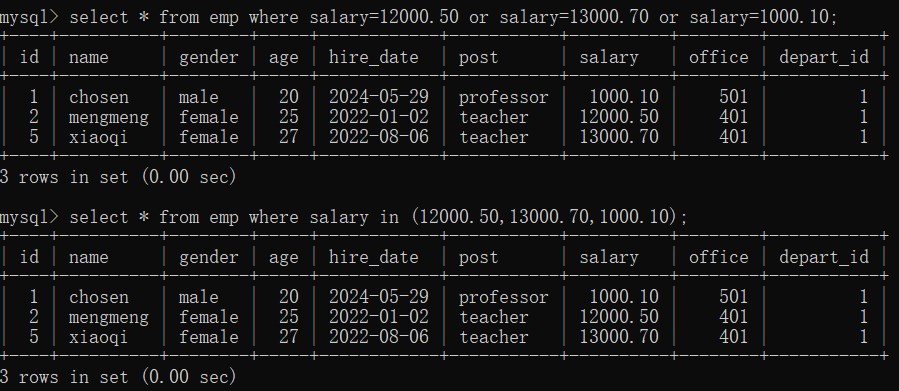
(2)查询 薪资是1w2或者1w3或者1000的数据
# 方式一
select * from emp where salary=12000.50 or salary=13000.70 or salary=1000.10;
# 方式二
select * from emp where salary in (12000.50,13000.70,1000.10);
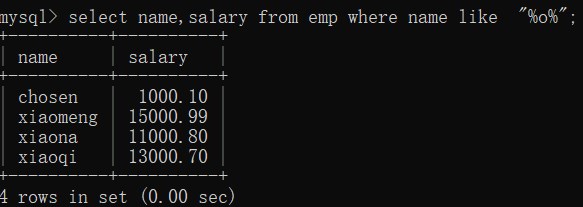
(3)查询 员工姓名中包含字母o的姓名和薪资
-- 模糊查询 like
-- % 代表任意字符
select name,salary from emp where name like "%o%";
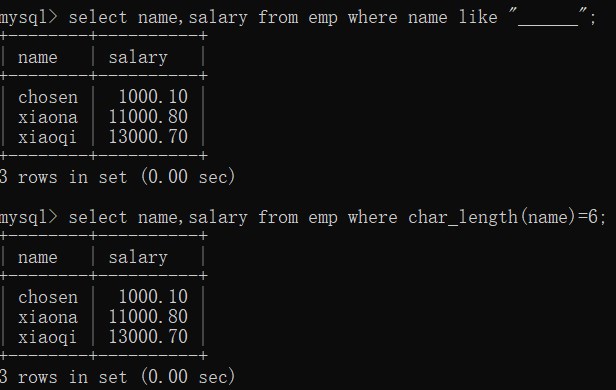
(4)查询员工姓名是由六个字符组成的姓名和薪资
# 方式一
-- 因为 _ 代表一个字符 6 个_ 代表6个字符
select name,salary from emp where name like "______";
# 方式二
-- 使用 char_length 内置函数对指定字段进行计数
select name,salary from emp where char_length(name)=6;
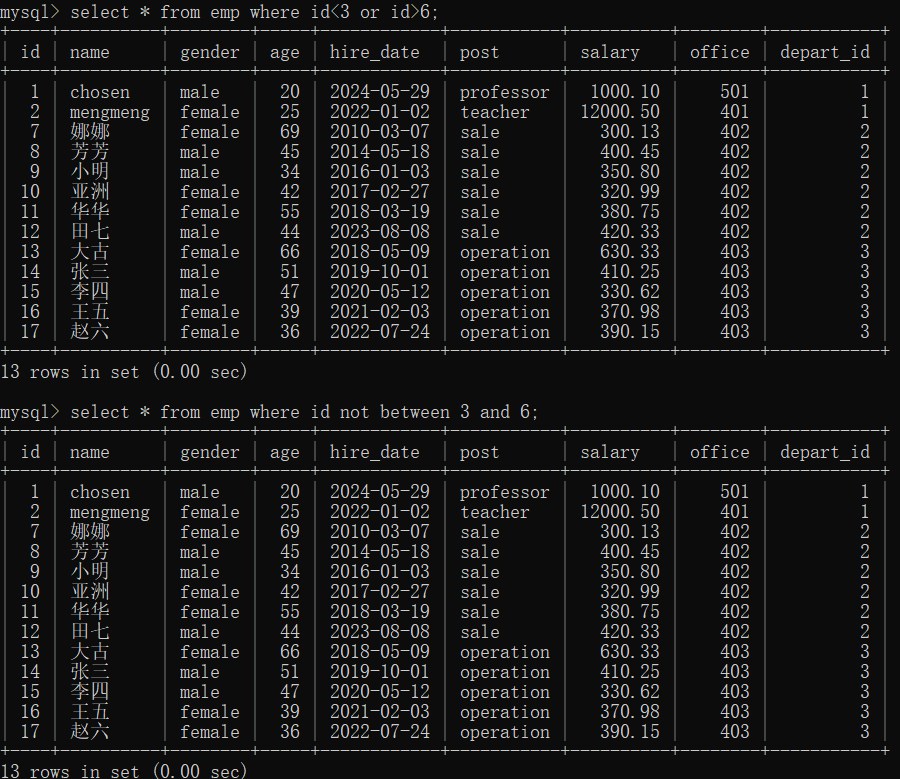
(5)查询 id<3 或者 id>6 的数据
# 方式一:
select * from emp where id<3 or id>6;
# 方式二
select * from emp where id not between 3 and 6;
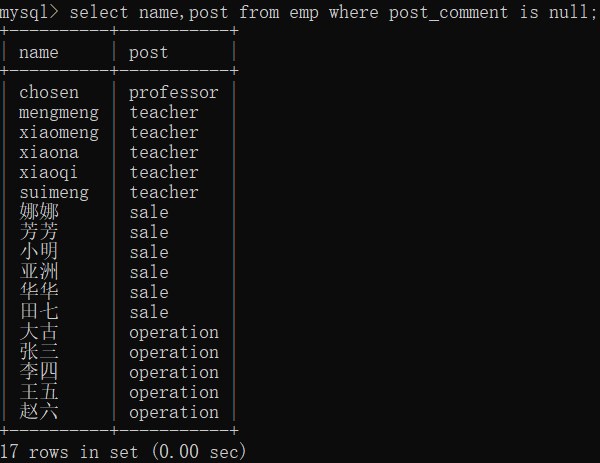
(6)查询岗位描述为空的员工姓名和岗位名
select name,post from emp where post_comment is null;
【作业】
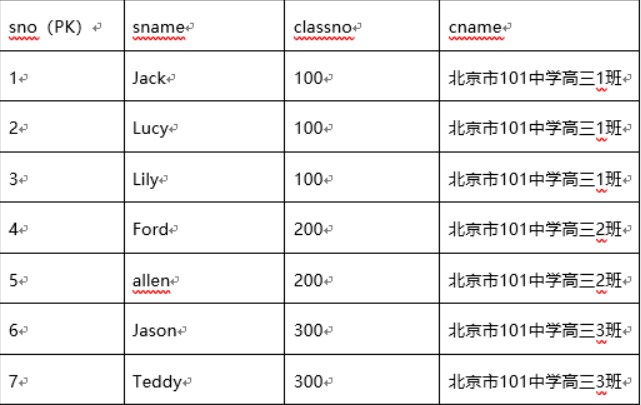
- 基于上面的信息做一个数据库下面的多张表
-- 按照你理想中的方式进行分表
-- 按照自己的想法和思路将上述所有信息进行分表
-- 在自己的表的基础上进行插入数据
-- 你的建表语句 ---> 字段及字段类型的创建
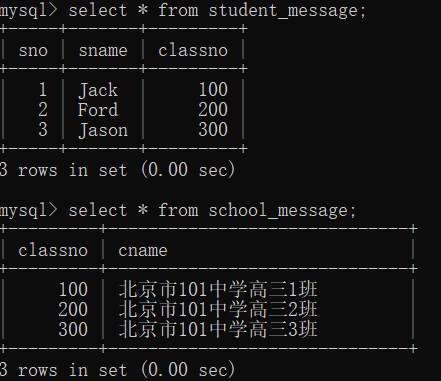
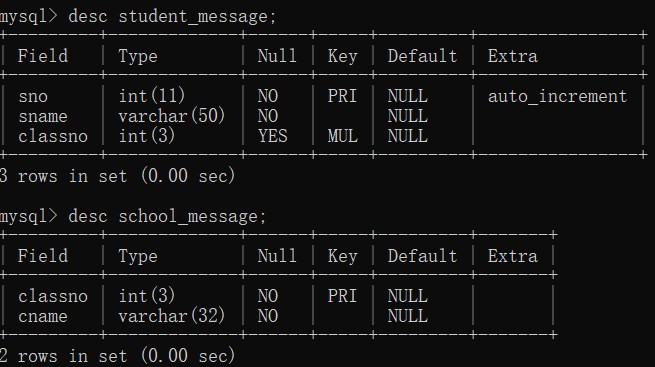
create table school_message(
classno int(3) primary key,
cname varchar(32) not null
);
create table student_message(
sno int primary key auto_increment,
sname varchar(50) not null,
classno int(3),
constraint stu_classno foreign key(classno) references school_message(classno)
);
-- 你的数据插入语句
insert into school_message(classno,cname) values(100,'北京市101中学高三1班'),(200,'北京市101中学高三2班'),(300,'北京市101中学高三3班');
insert into student_message(sname,classno) values('Jack',100),('Ford',200),('Jason',300);


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!