【一】模块与包介绍
【1】什么是模块
在Python中,一个py文件就是一个模块,文件名为 xxx.py,模块名则是xxx,导入模块可以引入模块中已经写好的功能。
如果把开发程序比喻成制造一台电脑
编写模块就像是在制造电脑的零部件
准备好零件后,剩下的工作就是按照逻辑把它们组装到一起。
将程序模块化会使得程序的组织结构清晰,维护起来更加方便。
模块保证了代码的重用性,又增强了程序的结构性和可维护性。
【2】模块的优点
极大地提高了程序员地开发效率
增强了程序地健壮性和可读性
【3】模块的来源
内置的:python解释器自带地,直接拿来使用的
第三方的:别人写的,如果想使用,就要先下载再使用
自定义的:自己写的
【4】模块的存在形式
单模块
包
将自己定义的功能所在的py文件,总结起来,放到一个文件夹下构成了一个包
必须有 __ init __.py 文件
【二】模块的使用
【0】准备
x = 1
def get ():
print (x)
def change ():
global x
x = 0
class Foo :
def func (self ):
print ('the func from the foo' )
【1】直接导入
import py文件名/模块名
(1)Import 导入模块会发生哪些事
要想在另外一个py文件中引用foo.py中的功能
需要使用 import foo
import foo
a = foo.x
foo.get()
foo.change()
obj = foo.Foo()
加上 foo. 作为前缀就相当于指名道姓地说明要引用foo名称空间中的名字
执行 foo.get() 或 foo.change() 操作的都是源文件中的全局变量 x
需要强调一点是,第一次导入模块已经将其加载到内存空间了,之后的重复导入会直接引用内存中已存在的模块,不会重复执行文件
通过 import sys
打印 sys.modules的值可以看到内存中已经加载的模块名
(2)import导入模块方式
import module1
import module2
...
import moduleN
import module1,module2,...,moduleN
(3)详细导入语法
(4)导入所有参数和方法
from foo import *
a = x
get()
change()
obj = Foo()
*的方式会带来一种副作用
即我们无法搞清楚究竟从源文件中导入了哪些名字到当前位置
这极有可能与当前位置的名字产生冲突。
模块的编写者可以在自己的文件中定义__all__变量用来控制 * 代表的意思
__all__=['x' ,'get' ]
x=1
def get ():
print (x)
def change ():
global x
x=0
class Foo :
def func (self ):
print ('from the func' )
这样我们在另外一个文件中使用* 导入时,就只能导入__all__定义的名字了
from foo import *
x
get()
change()
Foo()
(5)重命名模块
from ... import ... as ... 语句
from 模块位置 import 模块名 as 自定义名字
import foo as f
f.x
f.get()
【三】循环导入问题
在一个文件中导入调用了另一个文件
另一个文件在调用当前文件
【1】问题来源
print ('正在导入m1' )
from m2 import y
x='m1'
print ('正在导入m2' )
from m1 import x
y='m2'
import m1
【2】解决方法
(1)方法一
导入语句放到最后,保证在导入时,所有名字都已经加载过
m1.py
print ('正在导入m1' )
x='m1'
from m2 import y
print ('正在导入m2' )
y='m2'
from m1 import x
import m1
print (m1.x)
print (m1.y)
(2)方法二
导入语句放到函数中,只有在调用函数时才会执行其内部代码
m1.py
print ('正在导入m1' )
def f1 ():
from m2 import y
print (x,y)
x = 'm1'
print ('正在导入m2' )
def f2 ():
from m1 import x
print (x,y)
y = 'm2'
import m1
m1.f1()
【四】模块加载和搜索顺序
【1】模块的分类
模块分为四个通用类别,分别是:
1、使用纯Python代码编写的py文件
2、包含一系列模块的包
3、使用C编写并链接到Python解释器中的内置模块
4、使用C或C++编译的扩展模块
【2】加载顺序
先c 和 c++ 扩展出去的模块
使用c语言编写的底层代码
内置的一系列模块 (python解释器自带的和你安装 pip install )
纯python编写的自己定义的模块
【3】查找顺序
'''
def func():
import time
'''
'''
import time
'''
'''
python解释器自带的模块和你安装的模块中查,查出对应的模块再使用
'''
'''
有些功能ctrl进去看源码发现只要一个 pass
使用c语言写的,但是不想让你看到所有就省略掉了
'''
【五】绝对路径和相对路径
【1】相对路径
with open ('../user_data.text' , 'w' , encoding='utf-8' ) as fp:
fp.write('111' )
【2】绝对路径
import sys
print (sys.path)
【六】包
【1】什么是包
包是一个模块的集合,它可以将多个模块的功能组合到一起。
包可以按照其功能和作用进行分类,方便用户查找和使用。
包是在Python标准库中定义的一种特殊类型的模块,可以通过import语句来引入和使用。
Python的包分为标准库包和第三方库包。
标准库包是Python内置的包,包含了一些基本的模块和函数,如os、sys、random等;
第三方库包是第三方开发的包,通常提供了更加丰富和高级的功能。
【2】如何创建包
【3】使用包
(1)创建包
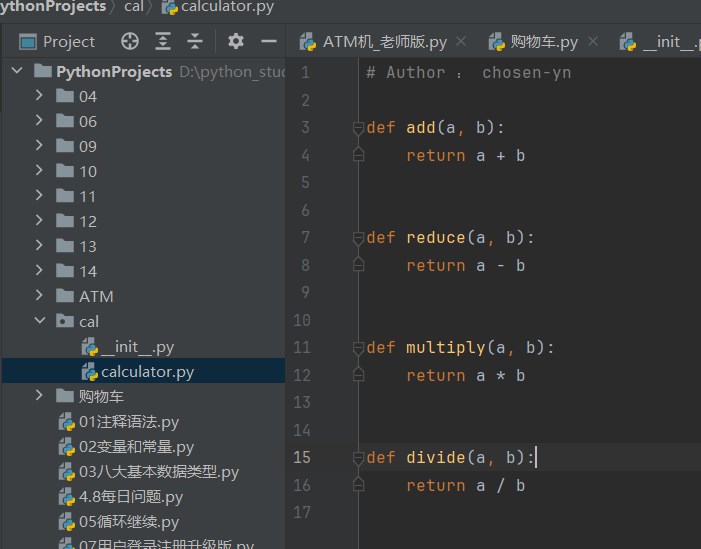
创建一个 cal 的包,包中有一个计算器的 model ,结构如下:
__ init __.py作用就是再导入当前 包的时候进行初始化操作 ---> 先检索 init文件
|-cal
|-__init__.py
|-calculator.py
def add (a, b ):
return a + b
def reduce (a, b ):
return a - b
def multiply (a, b ):
return a * b
def divide (a, b ):
return a / b
(2)直接使用包
Python 包的使用和模块的使用类似,下面是导入的语法:
import 包名.包名.模块名
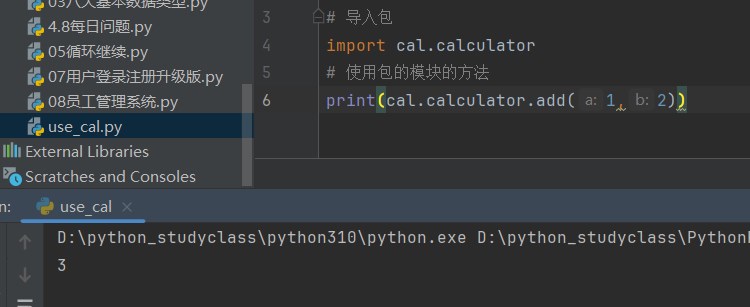
我们在 use_cal.py 中导入 calculator.py
import cal.calculator
print (cal.calculator.add(1 ,2 ))
(3)详细使用包
导入调用的时候报名比较长,这样就可以使用from ... import ...语句来简化一下。
from 包名.模块名 import 模块中的方法
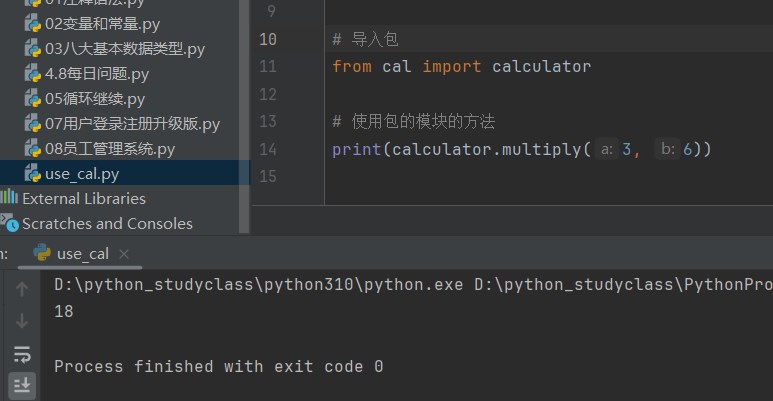
在 use_cal.py 中导入 calculator.py
from cal import calculator
print (calculator.multiply(3 , 6 ))
【4】制作包
from .calculator import add, reduce
from cal import add, reduce
print (add(3 , 6 ))
【七】导入语法总结
【八】json模块
【1】什么是序列化
【2】什么是反序列化
【3】json模块
(1)导入json模块
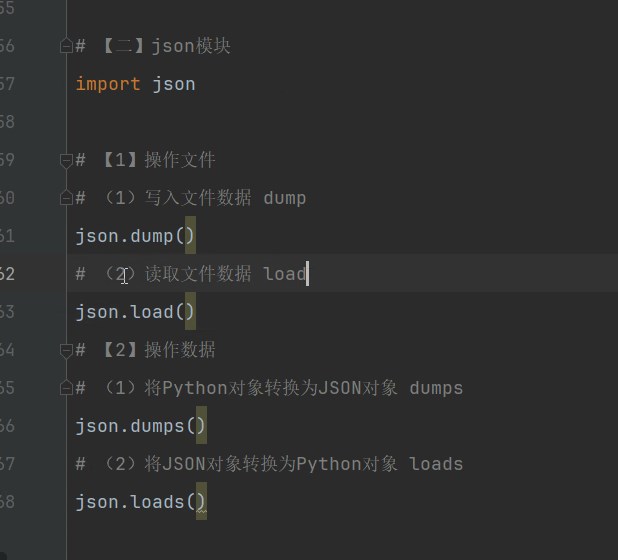
import json
(2)保存和读取
user_data_dict = {
'username' : "chosen" ,
"password" : "521"
}
'''
with open("user_data.text", 'w', encoding='utf-8') as fp:
fp.write(str(user_data_dict))
with open("user_data.text", 'r', encoding='utf-8') as fp:
data = fp.read()
print(data)
print(dict(data))
'''
with open ('user_data.json' , 'w' , encoding="utf-8" ) as fp:
json.dump(obj=user_data_dict, fp=fp)
with open ('user_data.json' , 'r' , encoding="utf-8" ) as fp:
data = json.load(fp=fp)
print (data, type (data))
(3)转换
data_json_str = json.dumps(obj=user_data_dict)
print (data_json_str, type (data_json_str))
data_json_dict = json.loads(data_json_str)
print (data_json_dict, type (data_json_dict))
(4)保存中文数据
user_data = {'name' : "蚩梦" , "age" : 18 }
with open ('data.json' , 'w' , encoding='utf-8' ) as fp:
json.dump(obj=user_data, fp=fp, ensure_ascii=False )




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!