container_of的使用及原理探究
2023-01-11
关键字:container_of、内存对齐
1、示例
container_of是定义在linux内核kernel.h中的一个宏,它的作用是根据结构体中某个成员的地址反推出该结构体的地址。
container_of之所以能做到这点,得归功于linux的内存管理方式在逻辑上是连续的这一特性。
先来看看container_of的用法:
1 struct S1{ 2 int a; 3 unsigned char b; 4 long c; 5 int d; 6 char e; 7 char f; 8 char* g; 9 }; 10 11 struct S1 s1; 12 13 s1.c = 1000; 14 15 long* pc = &s1.c; 16 17 struct S1* s1tmp = container_of(pc, struct S1, c); 18 printf("s1tmp->c:%d\n", s1tmp->c);
这段代码运行后将打印“s1tmp->:1000”,表示仅通过struct S1中的成员long c的地址就反推出了包含此成员的结构体的地址。
2、剖析
接下来看看container_of是如何实现反推功能的。
其定义原型如下:
1 ./include/linux/kernel.h 2 3 /** 4 * container_of - cast a member of a structure out to the containing structure 5 * @ptr: the pointer to the member. 6 * @type: the type of the container struct this is embedded in. 7 * @member: the name of the member within the struct. 8 * 9 */ 10 #define container_of(ptr, type, member) ({ \ 11 void *__mptr = (void *)(ptr); \ 12 BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \ 13 !__same_type(*(ptr), void), \ 14 "pointer type mismatch in container_of()"); \ 15 ((type *)(__mptr - offsetof(type, member))); })
第一个参数即我们已知的结构体内成员变量的地址。一定得注意,这个必须是成员变量本身的地址,某些成员可能是指针类型,必须使用这个指针变量本身的地址,而不能是它所指向的地址。举例如下:
以下写法是可行的:
struct S1{ int a; unsigned char b; long c; int d; char e; char f; char* g; }; struct S1 s1; char* ctmp1 = "hello world"; s1.g = ctmp1; char* pg = &s1.g; struct S1* s1tmp = container_of(pg, struct S1, g);
以下写法是不可行的:
struct S1{ int a; unsigned char b; long c; int d; char e; char f; char* g; }; struct S1 s1; char* ctmp1 = "hello world"; s1.g = ctmp1; char* pg = s1.g; struct S1* s1tmp = container_of(pg, struct S1, g);
container_of的第二个参数直接填要反推的结构体类型。
第三个参数填的是第一个参数在所求结构体中成员的名称。
查看container_of宏实现原型,就三行代码。第一行无须理会。第二行其实就是去判断所传的参数是否合法,其实也无须理会。实际上第二行代码在某些平台可能压根就不做任何事。真正起作用的是最后一行代码,它是用第一个参数中的地址减去该成员在结构体中的偏移量从而得到结构体第一个成员地址,而我们知道在结构体中第一个成员的地址其实就是这个结构体的根地址。所以我前面才会说container_of之所以能存在,完全得益于其逻辑连续的内存管理机制。
这里额外提一句,最后一行代码中计算成员在结构体中的偏移量offsetof最终是靠编译器来算出的。这种最底层的实现就没有必要去跟踪了。同时这也表明了我们无法通过纯代码来复刻一个container_of功能,对一个结构体来讲,我们可能很容易就能算出某成员的偏移量,但如果要我们用代码来实现,真的很难。
3、结构体的内存管理
上一节提到我们可以目测计算成员在结构体内的偏移量,这一节就通过一个小例子简单探究下。
先来看第一节示例代码中的结构体:
struct S1{ int a; unsigned char b; long c; int d; char e; char f; char* g; };
如果单纯地以“组合”心态来看待结构体与普通变量之间的关系,那么对struct S1求sizeof将会得到27个字节。但实际上,sizeof(struct S1)将会得到32个字节。
那我们稍微改一下struct S1,把f成员删掉:
struct S1{ int a; unsigned char b; long c; int d; char e; char* g; };
sizeof(struct S1)的值是多少?仍然是32个字节!
再改一下,在已经删掉f成员的基础上再删去c成员和g成员并增加一个char e2成员:
struct S1{ int a; unsigned char b; int d; char e; char e2; };
sizeof(struct S1)的值会是多少?答案是16个字节。
为什么会这样呢?为什么linux中结构体的大小不是简单地普通变量的组合呢?
linux的内存管理中有一个被称为“内存对齐”的机制。我对它的了解十分有限,查到的资料看的也是一知半解,只是大概知道内存对齐能提高内存访问效率,且内存对齐就是在结构体中将各类型变量会以相同的宽度来存储。
以上述第一个结构体来看,我们先给这些变量赋上值:
struct S1{ int a; unsigned char b; long c; int d; char e; char f; char* g; }; struct S1 s1; s1.a = 0x01; s1.b = 0x02; s1.c = 0x1000; s1.d = 0x10; s1.e = 0x04; s1.f = 0x08; s1.g = NULL;
s1在内存中的管理方式如下:
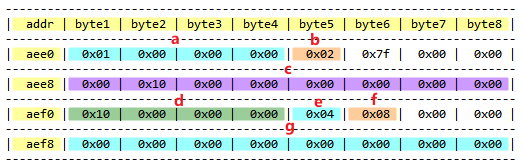
结构体成员a的地址为0xaee0 ~ 0xaee3,共占4个字节。
成员b的地址为0xaee4,共占1个字节。但紧随其后的3个字节是不可被使用的。
成员c的地址为0xaee8 ~ 0xaeef,共占8个字节。
成员d的地址为0xaf0 ~ 0xaf3,共占4个字节。
成员e的地址为0xaf4,占1个字节。
成员f的地址为0xaf5,占1个字节。但紧随其后的2个字节是不可使用的。
成员g的地址为0xaf8 ~ 0xaff,共占8个字节。
默认情况下的对齐方式是按结构体成员的类型中最长的那个作为基准。如在上述struct S1结构体中,最长的类型就是long和char*,占8个字节。因此其它所有成员都得按8个字节对齐。但它又不是强行将每一个成员都扩充至8个字节长度,而是扩充与压缩多措并举。首先将成员a扩充至8字节,但因int类型仅需4个字节即可,剩余的4个字节不应被浪费,而它后面的成员b所需要的字节数又少于多出的字节数,因此成员b就可以紧随a之后存储数据。如上图所示。在处理好成员a和成员b后仍有3个字节被空闲,但之后的成员c所需的字节数大于剩余的空间,无法合并,故而重新开僻一个8字节空间用于存储成员c。剩下的成员也依此类推。
所以,上述struct S1所占的空间会是32个字节。由此我们也可以推导出,在设计结构体时可以有意识地排版各成员类型以降低内存空间的闲置率从而减少程序对资源的占用。
在了解了上述struct S1的内存排布方式后,本节开头处的三个示例结构体剩余的两个的大小也就很容易理解了,就不再此赘述了。
最后,其实我们是可以动态修改其内存对齐字节数的。linux默认就是按最长类型作为对齐基准字节数,但我们可以通过关键字"#pragma param(*)"来修改。若我们将对齐字节数修改为1,则结构体在内存中就是普通类型变量的组合,该是多少字节就是多少字节。
具体的修改方式如下,可以在代码文件的任何地方声明:
#pragma pack() //动态调整,以成员类型最长的字节作为基准数 #pragma pack(1) //以1字节作为对齐基准数。即不对齐。 #pragma pack(4) //以4字节作为对齐基准数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号