Sqoop 快速入门
2019-05-12
关键字:Sqoop是什么、Sqoop安装
Sqoop 就是一个工具,对于工具,一般来说只要会用就够了。本篇文章旨在指导初次接触者快速了解并掌握 Sqoop ,具备将 Sqoop 应用到学习或生产环境中的能力。
1、概述
Sqoop 是一个在大数据领域里使用比较广泛的工具。它用于在 Hadoop 和关系型数据库中传送数据。
Sqoop 的核心功能就两个
1、数据导入
2、数据导出
数据导入是指将外部数据库中的数据迁到 Hadoop 中存储。而数据导出则相反。
Sqoop 实现数据导入导出功能的本质是将 Sqoop 的命令自动转换成 MapReduce 程序,在转换过程中主要是针对 InputFormat 和 OutputFormat 来进行定制。
正是因此,Sqoop 的运行依赖于 Hadoop ,换句话说,Sqoop 是 “站在 Hadoop” 这边的,这也解释了前面为什么将数据从外部迁到 Hadoop 会被称为 “导入” 了。
好,以上是 Sqoop 的初体验。
2、下载与安装
1、概述
前面说过,Sqoop 就是一个工具,因此它的使用必须建立在其它应用环境之上。Sqoop 支持的应用场景有
1、Hadoop
2、Hive
3、HBase
4、MySQL
5、Zookeeper
您想要将 Sqoop 应用到以上哪一个场景,那么以上场景的应用环境就必须在您的机器上部署好。
2、下载与安装
直接最官网下载: Sqoop 官方下载站 。选择一个最适合于您的版本下载即可,如果您不知道该如何选择,尽量不要选择最高版本的。笔者写这篇博客时,比较流行的版本是 1.4.7 。并且要选择一个名称上带了 bin__hadoop 字样的,这个字样表示当前 Sqoop 对 Hadoop 的最佳兼容版本。
下载完毕后直接解压即可,Apache 的软件安装方式就是让人省心。Sqoop 的目录结构如下图所示
3、配置
Sqoop 的配置文件都放在 conf 目录内。如下图所示
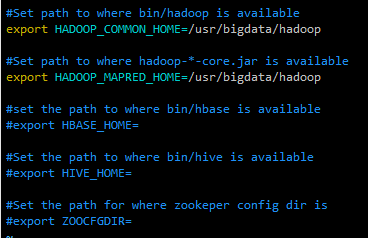
首先来配置环境变量。
cp sqoop-env-template.sh sqoop-env.sh
在这里,我们以 Hadoop 作为示例,因此,我们只配置一下 Hadoop 变量即可。
然后是将 MySQL 的驱动 jar 包拷贝到 lib 目录下。文末有驱动包的下载路径。
cp ~/mysql-connector-java-5.1.38-bin.jar lib/
最后不要忘记确保 MySQL 环境的构建。
然后,我们的 Sqoop 就能使用的了。
4、验证安装
接下来可以通过以下命令来查询 Sqoop 的版本信息以验证我们的安装结果
./bin/sqoop version
顺利的话可以看到如下结果信息
Warning: /usr/bigdata/sqoop/../hbase does not exist! HBase imports will fail. Please set $HBASE_HOME to the root of your HBase installation. Warning: /usr/bigdata/sqoop/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /usr/bigdata/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. Warning: /usr/bigdata/sqoop/../zookeeper does not exist! Accumulo imports will fail. Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation. 19/04/19 13:55:44 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7 Sqoop 1.4.7 git commit id 2328971411f57f0cb683dfb79d19d4d19d185dd8 Compiled by maugli on Thu Dec 21 15:59:58 STD 2017
前面提示了有一堆组件找不到的警告信息,但这些都不重要,本来我们上面就只配了一个 Hadoop 而已。关键是我们能看到如上加粗标红的 Sqoop 版本信息就可以了。
5、其它
通常我们还会将 Sqoop 的工作路径加入到系统环境变量中,但这并不是必要步骤,因此本篇文章就不提了。
3、基本命令
Sqoop 的命令不多,就几条。可以通过以下命令来查看所有 Sqoop 支持的命令
./bin/sqoop help
顺利的话可以得到如下信息
Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information See 'sqoop help COMMAND' for information on a specific command.
这里就不对这些命令一一展开解释了,对于初学者来说也没有这个必要,初学者不应该要太多的 “鱼” ,掌握 “渔” 反而会更重要一些。
如果我们需要查询某条命令的释义以及示例,可以通过上述信息中加粗标红的命令格式来查询。假设我们想知道 "list-databases" 命令如何使用,则可以使用如下形式的命令
./bin/sqoop help list-databases
执行以后会出来非常多的帮助信息,笔者在这里就不贴出来了。
更多关于命令的使用方式,大家有需要的自行去使用 help 查看就好了。
4、导入导出
在做演示之前,我们得确保自己的机器上 Hadoop 和 MySQL 都在正常运行着。
1、数据导入
与数据导入相关的命令与参数主要有以下几个
sqoop import --connect <jdbc-uri> jdbc 连接地址 --password <password> 密码 --username <username> 账号 --target-dir <dir> 目标目录
导入数据使用 sqoop import 命令。常用的参数及释义如上所示。
下面我们来测试一下从 MySQL 中导入数据到 Hadoop 中。
现 MySQL 中有一个 sqoopp 库以及一个 employee 表,表中内容如下
+------+----------+---------+--------+------+ | id | name | deg | salary | dept | +------+----------+---------+--------+------+ | 4 | prasanth | php dev | 30000 | AC | | 102 | manisha | preader | 50000 | TP | | 121 | gopal | manager | 50000 | TP | | 203 | kalil | php dev | 30000 | AC | | 405 | kranthi | admin | 20000 | TP | | 1201 | gopal | manager | 50000 | TP | | 1202 | manisha | preader | 50000 | TP | | 1203 | kalil | php dev | 30000 | AC | | 1204 | prasanth | php dev | 30000 | AC | | 1205 | kranthi | admin | 20000 | TP | | 1206 | satish p | grp des | 20000 | GR | | 1886 | satish p | grp des | 20000 | GR | +------+----------+---------+--------+------+ 12 rows in set (0.01 sec)
此时便可通过以下 Sqoop 命令来将 MySQL 中的该表数据导入到 Hadoop 中
./bin/sqoop import \ --connect jdbc:mysql://192.168.77.254:3306/sqoopp \ --username sqoop \ --password 123456 \ --table employee \ --target-dir /bigdata/sqoop/mysql/
执行以后可以看到一个 MapReduce 作业的运行过程。这里提一下,--target-dir 后面接的目录必须是不存在的目录,因为 MapReduce 的作业本来就要求输出目录不能存在的。作业执行完毕后查看 HDFS 的目录可以看到生成了几个文件,如下图所示
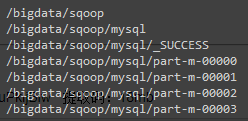
这里得提一下,part-m-***** 文件的数量是不确定的,不能对号入座!
这个时候我们可以直接 hdfs dfs -cat 一下这几个文件,可以发现里面的数据是和在 MySQL 中的一样的。

以上是一个简单的全量导入数据的例子。我们也可以指定一些导入条件限制。比如自定义字段分隔符、添加查询条件甚至是执行自定义 SQL 等。如
sqoop import \ --connect jdbc:mysql://192.168.77.254:3306/sqoopp \ --username sqoop \ --password 123456 \ --table employee \ --target-dir /bigdata/sqoop/mysql1/ \ --fields-terminated-by '='
sqoop import \ --connect jdbc:mysql://192.168.77.254:3306/sqoopp \ --username sqoop \ --password 123456 \ --table employee \ --target-dir /bigdata/sqoop/mysql2/ \ --where "dept='TP'"
2、数据导出
假设我们在 HDFS 上有一个文本,其内容如下所示
01 01 80 01 02 90 01 03 61 02 01 70 02 02 60 02 03 80 03 01 80 03 02 80 03 03 80 04 01 50 04 02 30 04 03 20 05 01 76 05 02 87 06 01 31 06 03 34 07 02 89 07 03 98 07 04 66 11 02 59
我们想将这组数据导出到 MySQL 中去。首先要在 MySQL 中创建一个表,这个表包含 3 个整型字段,建表语句如下所示
create table demo(a int, b int, c int);
然后再执行以下 Sqoop 命令
./bin/sqoop export \ --connect jdbc:mysql://192.168.77.254:3306/sqoopp \ --username sqoop \ --password 123456 \ --table demo \ --export-dir hive/warehouse/myhivedb1.db/score/score.txt \ --input-fields-terminated-by ' '
这里一定要注意最后一个参数 --input-fields-terminated-by 不能少,否则的话 Sqoop 很可能无法正确分隔字段。因为 MapReduce 默认的字段分隔字符好像是 ^M 好像,记不太清,总之不是常用字符,所以必须要指定。
顺利执行完毕的话,去 MySQL 中就可以查到这这组数据了。
当然,其实导出操作也像导入操作那样,可以添加很多的条件限制,但是这些内容,笔者就不在此赘述了,只要我们掌握了 “渔” ,有任何需求都可以自行查到答案。
MySQL 驱动包 : 链接:https://pan.baidu.com/s/1vh85R6MzYRBhXEuPkljBiw 提取码:18mb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号