

设计了一个自动归档工具
 分享一个我年初设计的自动归档功能,如何将一些思考融入到简单的CRUD中
分享一个我年初设计的自动归档功能,如何将一些思考融入到简单的CRUD中
背景
随着业务的发展,一些事务类表(源源不断产生业务数据)会越来越大,最终演变成我们说的大表,普通的查询可能毫秒级、秒级返回,但是稍微复杂的就会超时,甚至占满数据库cpu,进而导致大面积请求超时、堆积,jvm fullgc,触发熔断等连锁反应。
前几天业务高峰期的时候收到客户反馈,说系统访问卡顿,已经严重影响业务,需要立即处理,根据以往的经验我第一时间查看了数据库监控,果不其然cpu 100%。
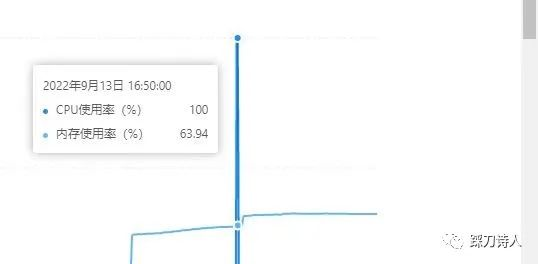
为了快速恢复业务,我将运行时间较长的会话kill掉。
事后分析了事发前的慢查语句,其中有一条查询操作日志的sql引起了我的注意,类似于select * from op_log where create_time between xxx and yyy and log like '%keyword%',我一看op_log这个表已经超过2000w行数据,这么查肯定会查死啊,往群里一发老大立马回复到“这个表是有归档的,一般只保留几个月的,不应该有这么大,需要跟踪一下”。
我查了代码,的确是有一个归档功能,简单来说就是定时(每月一次)执行以下三行逻辑:
1.List<OpLog> opLogs = select * from op_log where create_time<当前时间-3个月
2.for each insert into op_log_history values xxx,yyy,zzz
3.delete from op_log where create_time<当前时间-3个月
那为什么还会有这么多的数据呢,访问人数并没有明显增加,带着疑问我搜索了9月1号的执行日志,原来是执行的时候发生了OOM,所以当次也就失败了,由于8月份的日志已经删除,所以不知道8月1号的执行情况,猜测应该也失败了,因为这个归档功能做的实在是太过于简陋,初看就有以下两个明显缺点:
1.select * from op_log where create_time<当前时间-3个月 一次性查询所有满足归档条件的数据,很容易占满jvm内存;
2.使用Spring的Schedule实现,没有加任何重试、报警机制,不满足系统可观测性原则。
期望
第一时间调研了一些现成的解决方案,比如pt-archiver,优点是功能完善而且运行时间较久稳定性高,缺点是只局限于一些主流的数据库,而有些客户采购了一些较为小众的数据库,pt-archiver这类工具并不能覆盖所有场景,鉴于此我们希望自己造轮子,针对不同的数据库做简单的适配改造即可,不至于被第三方工具牵绊,查阅了一些资料,常规的数据归档方式如下:
-
开发:写个转储逻辑、写个清理逻辑,部署在某个应用服务器,周期调度这段代码。
-
DBA/运维:写个转储SQL、写个清理SQL,提交crontab部署在数据库服务器,周期调度这个脚本。
常规的归档方式存在以下不足:
-
每个业务表都需要重复一次这样的开发与配置。
-
无法有效全局管控,如遇到重大活动、变更等重要窗口无法有效的暂停任务的调度。
-
任务未有效调度时无法及时、有效的通知介入,容易造成在线表数据量过大的问题降级服务性能。
-
执行日志无法统一管理,有效溯源查看。
工作流程
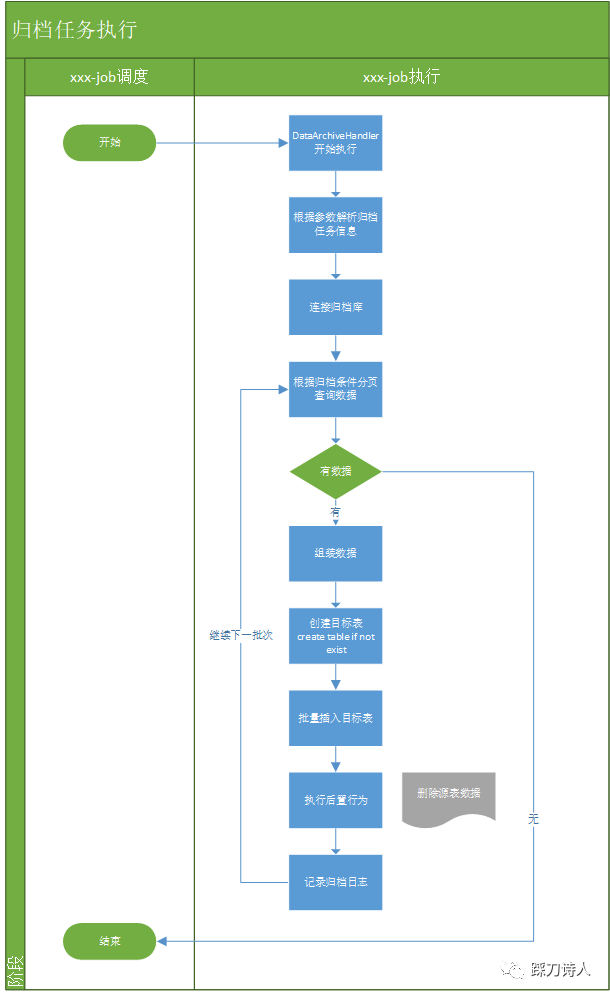
针对上面提到的常规的归档方式做了一些改进,将归档这个动作做了相应的抽象,不需要每个业务表都重复开发一套归档逻辑,只需要简单的配置即可形成一个归档任务,最终将归档任务同步给xxl-job,这样就可以复用xxl-job的调度、故障重试、报警、查看执行日志等功能。
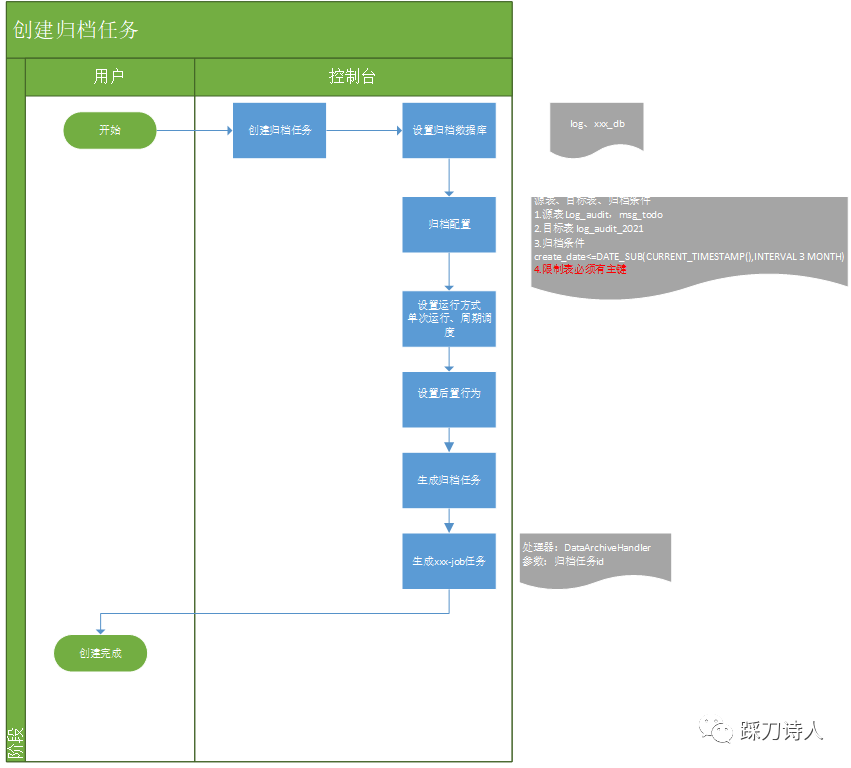
组件设计
控制端
功能列表如下:
1.归档任务创建、查看、删除;
2.归档历史查看、手动执行;
3.归档任务导出、导入。
任务列表

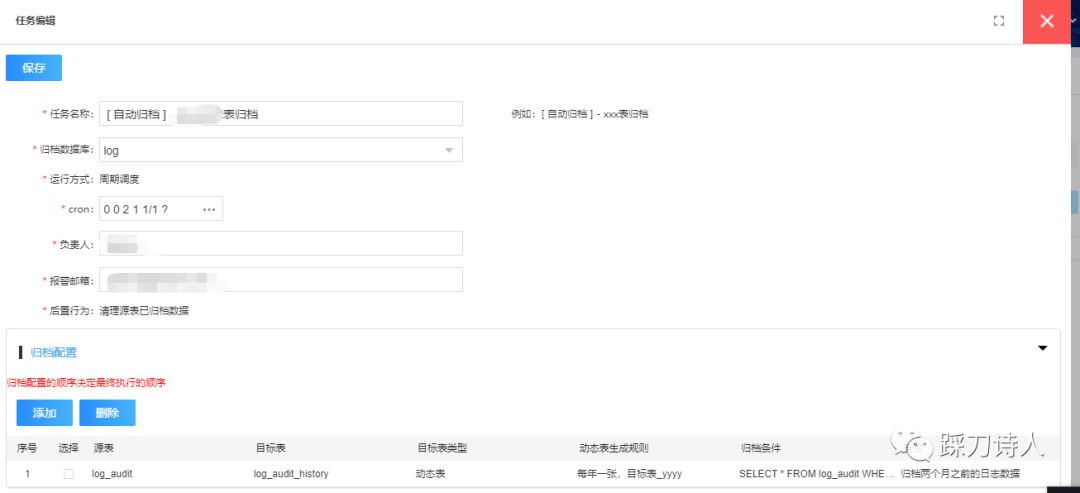
创建&编辑任务
查看任务执行历史(复用xxx-job)
表关系e-r图
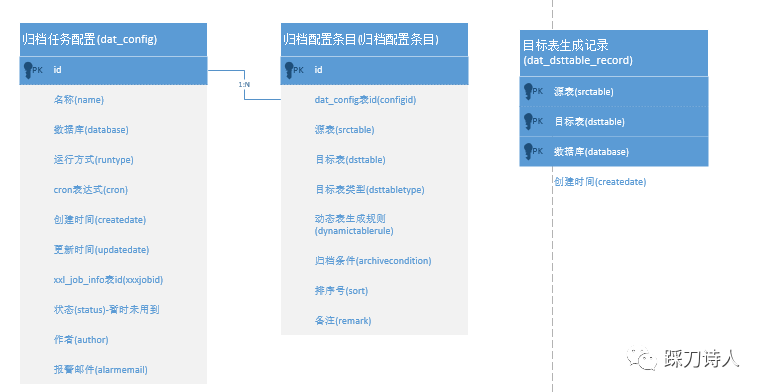
目标表支持固定表和动态表两种类型,当类型为动态表时,需要指定动态表生成规则,目前支持“每月一张”和“每年一张”两种生成规则,假设目标表名为dst_table,下面表格列出不同组合下的目标表。
|
目标表名 |
目标表类型 |
动态表生成规则 |
最终目标表 |
|
dst_table |
固定表 |
NA |
dst_table |
|
dst_table |
动态表 |
每月一张 |
dst_table_yyyyMM,比如dst_table_202201 |
|
dst_table |
动态表 |
每年一张 |
dst_table_yyyy如dst_table_2022 |
归档任务处理器
功能列表如下:
1.根据表达式创建归档表;
2.根据归档条件拉取归档数据并插入目标表;
3.执行后置行为,如删除原表数据等;
4.记录归档日志。
涉及到的一些实现细节
1.源表必须要有主键
这个主要是考虑异常情况下的重试功能,我们的归档逻辑是先插入目标表然后删除源表,中间如果出现异常情况,可能会出现已经插入到目标表但是没有从源表删除的情况,下一次执行就会出现目标表中数据重复的情况,有了主键就可以利用数据库的一些特性来规避,比如mysql中的insert ingore into,也许有人会问为什么不引入事务机制保证插入和删除的ACID特性呢,主要是怕麻烦,因为代码运行在spring+mybatis框架之下,开启事务就要引入事务管理器那一套东西,倒不如用一些巧方法规避过去。
1 2 | 通过DatabaseMetaData可以获取到表的主键信息DatabaseMetaData.getPrimaryKeys |
2.归档条件的校验
归档条件是开发手动录入的sql,难免有手抖的情况,最大的风险在于漏加where条件,所以归档条件必须是要校验的,这里借助了jsqlparser框架解析sql,判断是否包含where。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | String archivecondition = "select * from test_table";Statements statements = CCJSqlParserUtil.parseStatements(archivecondition);List<Statement> statementList = statements.getStatements();for(Statement statement : statementList) { if (!(statement instanceof Select)) { throw new Exception("归档条件只支持select"); } Select select = (Select) statement; PlainSelect plainSelect = (PlainSelect) select.getSelectBody(); Expression expression = plainSelect.getWhere(); Assert.isNull(expression,"归档条件不包含where");} |
3.运行一段时间后源表和目标表字段不一致导致保存失败
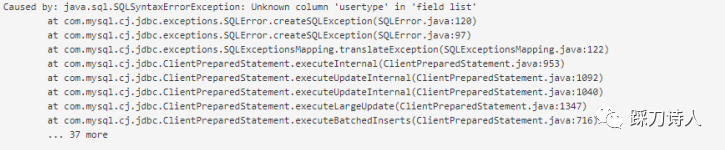
由于业务发展过程中源表中增加了新字段,但是目标表由于是归档处理器自动创建,开发人员一般不会同步增加字段,这就导致归档失败,也有开发跟我提过需求:“归档处理器能不能识别到这类异常自动补全缺失的字段”,我的回答是这类问题由人工处理,主要考虑到目标表经过长时间的运行可能已经变得异常庞大,贸然的加字段必然引起数据库的不稳定,线上大表的变更一定要谨慎,多和dba沟通,尽量选择夜深人静的时候。
总结
看似一个小功能也要多方面考虑,性能、兼容性、普适性、易用性、可观测性等等都值得我们深入推敲,想清楚了再干,当你抱怨CRUD没有技术含量的时候,就应该考虑怎么把CRUD做出一朵花出来,这个归档功能就是一个再明显不过的CRUD了。





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 单线程的Redis速度为什么快?
· SQL Server 2025 AI相关能力初探
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 展开说说关于C#中ORM框架的用法!