《构建之法》--第四次作业--结对编程
| 这个作业属于哪个课程 | 课程的链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求的链接 |
| GIT项目地址 | WordCount |
| 结对伙伴作业地址 | linls |
| 个人博客主页 | Vchopin |
我们这一次的github项目是从作业指导中Fork下来到自己的项目中的,用的git地址,是我的项目地址。这次结对编程我的结对伙伴是linls,技术牛逼,python机器学习大佬一枚,以下简称为俊老板
系统分析
本来还想进行需求需求了解的,结果仔细一看作业指导中,北航老师已经清清楚楚写的明明白白了,所以和俊老板就决定直接开始分析
分析
第一步
作业中需要在第一步完成wordCount的基本功能,也就是在命令行中统计一个txt文本中的全部字符数以及其他要求。
1.命令行参数。对于命令行参数的处理,C#可以直接从Main函数中的args中直接获取
2.汉字的处理。要实现只处理ascii而不处理汉字,其实可以通过汉字的unicode对其进行过滤。但是这个时候俊老板提出,一段文本里面可能不只是有汉字和英文,也可能有日语或者其他什么语言,所以光去除汉字不行,应该是保留所有的ascii去除不是ascii的文字。当然可以用正则表达式,也可以直接用.Net自带的Encoding类过滤。
3.空格、制表符和换行符的处理。刚开始一看很懵...这咋知道\t是不是四个space啊。后来俊老板提醒,这些都是电脑判断,我们只需要判断他这个字符是\t还是space就可以了。是四个space那也不用当成\t。
4.对于file123和123file的判断处理。其实这个要点我和俊老板发生了意见冲突,我认为通过C#的字符串方法string.StartWith()这个方法就可以进行判断求解的。但是俊老板坚持认为,使用正则表达式能够更加快速以及效果显著的完成统计。因为具体两种方法都是可以实现的,所以我们都还是各自保留了自己的想法,到编码的时候在具体选择。
5.单词的统计。我和俊老板一看题,这个单词是按照分割符进行统计的,可是分隔符是包括了所有的非字母数字符号,我们一致用正则表达式的硬编码匹配那就很难受。后来我想可不可以直接用while遍历全部的字符,将那些ascii码值大于等于97小于等于122的那些当做分隔符,出现就将其两边的字母作为前一个单词结尾和后一个单词开始。
6.统计频率最高出现的10个单词。俊老板在看到的时候认为,这个可以新增一个类,将单词的内容和频次作为这个类的属性。但是后来,我觉得不行,要是统计的文章有个一万多个字,那就要构造一万多个对象,先不说内存花费,构造对象的时间都有够呛。我们考虑了用数组,泛型等等。发现数组浪费的空间很大,泛型在执行效率方面比较低下。最后想到用Dictionary或者HashSet可以完美解决效率和空间的问题。
7.按照字典序输出。我想的是,在统计完成之后,如果发现有几个统计频率是一样的单词,就让他们在按照升序排一次序就行。但是我初步估算的话,这样的时间复杂度会比较大,如果按照冒泡排序来说,就可能是O(n^4)的时间复杂度...我和俊老板在这里对于具体怎么实现都还不清楚,我们也还是决定到时候具体编程的时候在具体解决。
第二步
这个部分主要是将第一步中的统计字符数、统计单词数、统计最多的10个单词及其词频这三个功能进行剥离,形成dll,以便于在命令行、图形界面、网页程序和手机App上面使用。并且这个dll能够提供相应的api供其他辅助调用。首先要保证这三个功能的完全正确性,所以对其进行单元测试保证可用性。
那么这个问题我和俊老板都是决定通过重新写一个类,里面的public方法就是分别是上面三个功能的入口,其余的辅助函数都写成private防止暴露。最后利用VS工具生成动态链接库(DLL)就可以完成封装。当我们在其他地方进行调用的时候,将该dll添加到引用,并引入命名空间,即可开始调用里面的方法完成计算。当然,第二步是需要我们写单元测试保证该dll稳定,所以,最主要的还是在单元测试中引入相关代码并完成测试。如果有时间,俊老板打算在移动应用或者ASP.Net上面试试。
第三步
这一步主要是在原有基础上的功能的拓展。对多参数处理,词组统计,自定义输出的实现。
- 对于多参数处理的实现。俊老板认为直接对获取到的每一个参数进行处理,如果他是以
-符号开头的,可以认为是一个标识符。然后获取到-后面的字母,在对其进行判断类型,同时,还得保证标识符的空格后面必须有合法的值。比如对于-i,后面就必须是一个存在的文件名,否则提示错误。 - 使用参数设定统计的词组长度。我认为这个是可以直接从处理过后的单词词组中进行选择,按照序号依次通过for循环输出,循环次数由输入的
-m后面的参数决定。当然也需要完成对后面的数字的处理。 - 设定单词数量。和上面的思路基本一样,在第一步中是实现的前10个词频最高的单词,可以直接输出10个Console。但是现在通过变量运算来控制显示单词的个数,就需要有一个count单词来计数。当达到相应的数量之后就
break。
其实最重要的我认为还是最后一个多参数的混合使用,比如某个参数可能不出现,不出现就得有默认参数。并且参数之间的顺序也不固定,不能按照顺序对其进行取值。俊老板的想法是将所有输入参数组成一个字符串,最后通过判定特定字符是否在字符串中进行参数存在判定。
第四步
这一步其实没有什么好说的,利用winform或者wpf直接拖控件按照对应的功能和所需要求完成界面设计,计算单词的算法还是用第一步中基本核心算法功能,加上第四步中的增强功能改成GUI的方式完成设计。
第五步
这一步是进行单元测试。是对前面所有的部分进行单元测试,包括核心算法功能,额外增强功能和GUI的附加功能。我们认为对于核心算法功能和额外增强功能都比较好记性测试,可是对于图形化界面如何进行测试呢?查询资料后发现网络上面基本没用对GUI进行测试的...不是因为很难,因为没有必要...但是还是发现有这样的工具,比如Nunit可以对winform和wpf这种C#写的代码进行图形化测试。俊老板查询的简单粗暴,直接用Rebot类自动测试。其实我觉得都可以。最重要的还是对于单词的计算的功能的测试。我们决定对以下几个地方进行测试:
- 输出格式测试
- 字母、单词、行数统计的测试
- 前10个频次最高按照字典排序的单词测试
- 对于非ascii码的处理测试
- 多参数读入测试
- 读入文件输出文件非法文件名测试
- 词组长度测试
- 输出单词数量的测试
- 意外情况处理测试
- 输入错误的处理
第六步
效能分析我们决定在代码写出来之后再利用vs的效能分析软件查看他的性能,对严重拖慢程序运行进度的进行修改和优化。
代码规范
我们认为,要做就要做好。所以,我们的代码规范都是按照互联网上通用规则进行编写:
注释
1> 如果处理某一个功能需要很多行代码实现,并且有很多逻辑结构块,类似此种代码应该在代码开始前添加注释,说明此块代码的处理思路及注意事项等
2> 注释从新行增加,与代码开始处左对齐
3> 双斜线与注释之间以空格分开
命名规则
部分参考https://blog.csdn.net/tieshuxianrezhang/article/details/51960039
4> 类和接口命名
l 类的名字要用名词;
l 避免使用单词的缩写,除非它的缩写已经广为人知,如HTTP。
l 接口的名字要以字母I开头。保证对接口的标准实现名字只相差一个“I”前缀,例如对IComponent接口的标准实现为Component;
l 泛型类型参数的命名:命名要为T或者以T开头的描述性名字,例如:
public class List
public class MyClass
l 对同一项目的不同命名空间中的类,命名避免重复。避免引用时的冲突和混淆;
5> 方法命名
l 第一个单词一般是动词;
l 如果方法返回一个成员变量的值,方法名一般为Get+成员变量名,如若返回的值 是bool变量,一般以Is作为前缀。另外,如果必要,考虑用属性来替代方法;
l 如果方法修改一个成员变量的值,方法名一般为:Set + 成员变量名。同上,考虑 用属性来替代方法。
6> 变量命名
l 按照使用范围来分,我们代码中的变量的基本上有以下几种类型,类的公有变量;类的私有变量(受保护同公有);方法的参数变量;方法内部使用的局部变量。 这些变量的命名规则基本相同,见标识符大小写对照表。区别如下:
a) 类的公有变量按通常的方式命名,无特殊要求;
b) 类的私有变量采用两种方式均可:采用加“m”前缀,例如mWorkerName;
c) 方法的参数变量采用camalString,例如workerName;
l 方法内部的局部变量采用camalString,例如workerName。
l 不要用_或&作为第一个字母;
l 尽量要使用短而且具有意义的单词;
l 单字符的变量名一般只用于生命期非常短暂的变量:i,j,k,m,n一般用于integer;c,d,e 一般用于characters;s用于string
l 如果变量是集合,则变量名要用复数。例如表格的行数,命名应为:RowsCount;
l 命名组件要采用匈牙利命名法,所有前缀均应遵循同一个组件名称缩写列表
代码编写
思路分析
我和俊老板仔细研究题目后,认为我们俩的水平还是不太行,整体来写的话很有难度,于是我们决定按照题目要求一个点一个点来编写,逐个击破。由于作业指导中已经将具体代码优化步骤已经给出,所以,我们在第一步的基本功能的实现方面就将全部方法糅杂在一个Main函数中。然后在第二步中根据题目要求和我们代码具体实现进行拆分解耦。在第三步在根据第二步拆分的进行拓展。后面的步骤基本就按照作业指导走就行了。附上一起讨论编程的合作照片

编码
第一步
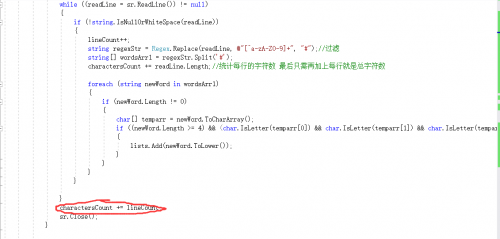
首先实现的是最最基本的利用正则表达式将全部的非字母数字的全部替换成为#,然后在用字符串的Split('#')方法将一个字符串拆分到数组中,就形成一个一个的单词。在根据单词前四个必须是字母完成对不符合的要求的筛选。代码如下
string regexStr = Regex.Replace(readLine, @"[^a-zA-Z0-9]+", "#");//过滤
string[] wordsArr1 = regexStr.Split('#');
charactersCount += readLine.Length;//统计每行的字符数 最后只需再加上每行的字符数就是总字符数
foreach (string newWord in wordsArr1)
{
if (newWord.Length != 0)
{
char[] temparr = newWord.ToCharArray();
if ((newWord.Length >= 4) && (char.IsLetter(temparr[0]) && char.IsLetter(temparr[1]) && char.IsLetter(temparr[2]) && char.IsLetter(temparr[3])))
{
lists.Add(newWord.ToLower());
}
}
}
代码流程图如下
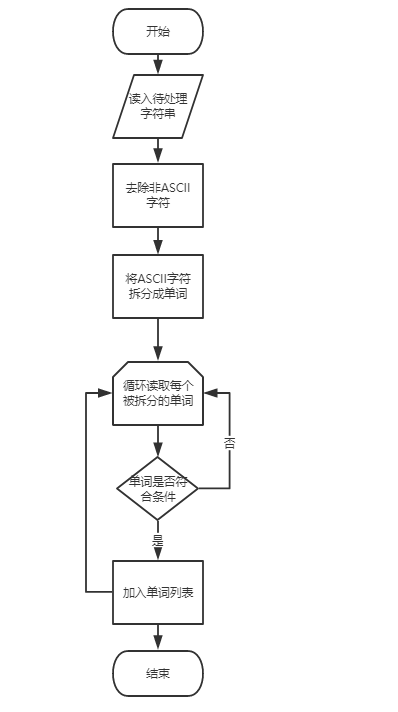
完成对单词的提取之后,接下来是对单词的频率统计和排序。在需求分析里面我们讨论了如何是实现单词内容和频率的关联,考虑到最后输出的每个单词都是不可能一样的(唯一性),但是频率有可能是一样的,这个属性完全符合字典的key-value模型,因此我们决定是使用具有KeyValuePair的Dictionary类来对其绑定实现。循环迭代上面的lists中的单词,没有出现在字典中的,就直接按照频率为1加入到字典集合中,出现在字典中的,对该个key的value加一操作,这样就可以完成单词的统计。字典的统计单词频率代码如下:
Dictionary<string, int> wordsCount = new Dictionary<string, int>();
//单词出现频率统计
foreach (string li in lists)
{
if (wordsCount.ContainsKey(li))
{
wordsCount[li] ++;
}
else
{
wordsCount.Add(li, 1);
}
}
统计频次完成之后,就需要对其进行排序,按照频次从大到小,如果频次相同,就要按照字典序对单词排序。这里其实涉及到两种排序,一开始俊老板是想将其挨个取出放在List中,排序之后在放回Dictionary里面。这是可以实现的,但是空间复杂度和时间复杂度都是相当的高。我们后面继续查阅资料(参看博客https://www.cnblogs.com/5696-an/p/5625142.html)发现C#的Dictionary类是自带排序的,属于链式编程正好完美解决降序排一次在升序排一次。代码如下:
Dictionary<string, int> sortedWord = wordsCount.OrderByDescending(p => p.Value).ThenBy(p => p.Key).ToDictionary(p => p.Key, o => o.Value);
foreach (KeyValuePair<string, int> item in sortedWord)
{
Console.WriteLine("word:{0} ; count:{1}",item.Key, item.Value);
}
这样就基本完成第一步的代码编写了。那么是骡子是马,上图溜溜:
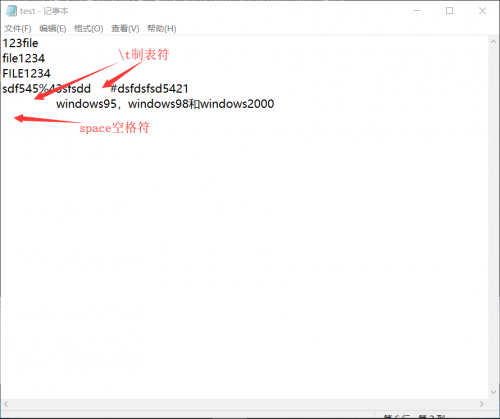
首先是我们的测试文件图片
然后是代码操作运行截图
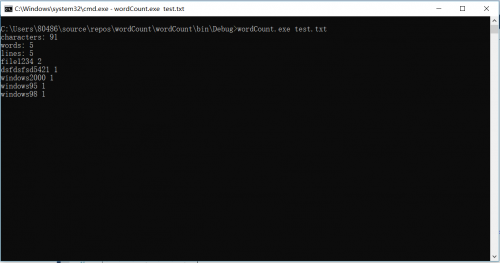
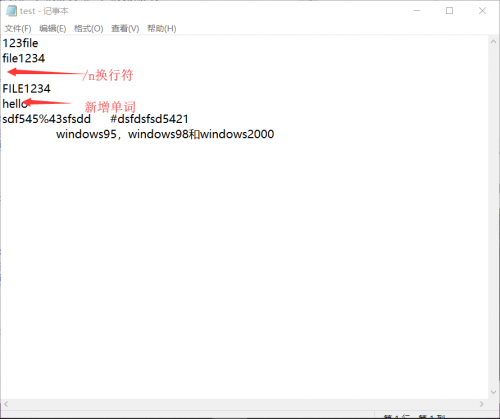
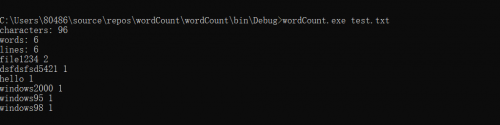

不看倒是没什么,仔细一看,这个代码问题大得很。ReadToEnd()的这个方法,直接就全部读完,之前一行一行的判断直接到了末尾。现在在用这个方法等于没有读到任何字符。如果一定要用这个方法,只能用两个StreamReader分别读取测试文件。最后我们决定采取一个折中的办法,浪费空间,换取对重新读取文件的时间。新增一个lines代表全部行数,每读一次就自增1.最后就可以得出全部行数。试验效果:

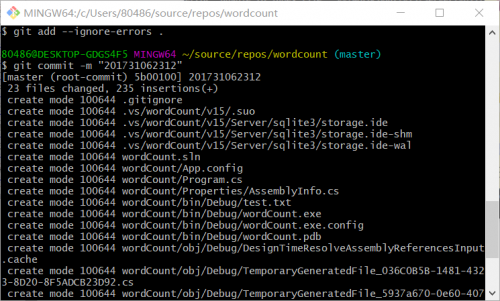
第一个版本做出来,就准备开始上传Git了。还是按照作业2的步骤上传Git,放到这里出现问题了...不能够将要上传的VS目录添加到暂存空间。

多次查阅资料(参考博客https://www.cnblogs.com/Fred1987/p/10934705.html)之后发现VS目录中的隐藏文件夹.VS是无法读取上传的。通过输入git add --ignore-errors .就可以忽略不能读取的进行上传。
使用git commit上传
在使用git remote add origin https://github.com/vchopin/WordCount.git然后使用git push又出现错误了
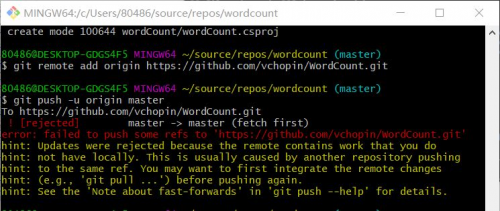
根据英文意思,我猜测是没有和远端仓库合并代码,所以接下来先执行git pull拉去仓库到本地合并。
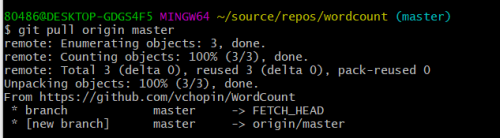
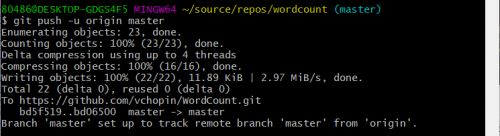
完成合并之后,在继续git push推送到仓库中
第二步
第二步是对原有代码进行差分解耦。我和俊老板决定按照不同功能分别用抽象实现顶部封装,便于日后的升级和代码规范。最最重要的还是要将统计字符数、统计单词数、统计最多的10个单词及其词频这三个功能进行独立出来,我和俊老板想的是如果给每一个功能都新增抽象类,那么类就会很庞大。所以最后采取维护基本功能、抽象核心计算功能。
首先是对文件输入和输出的剥离,将读取字符功能和打印前十个单词的功能抽象为一个接口中的两个方法如下:
interface IDataIO
{
/// <summary>
/// 从文件中读取全部字符
/// </summary>
/// <param name="path"></param>
/// <returns></returns>
string ReadFromFile(string path);
/// <summary>
/// 打印前maxline个排序后的单词。为0则全部打印
/// </summary>
/// <param name="sortedWord"></param>
/// <param name="maxline"></param>
void Print(Dictionary<string,int> sortedWord, int maxline=0);
}
然后在实现这个接口
class DataIO:IDataIO
{
public static string ReadFromLittleFile(string path)
{
return File.ReadAllText(path, Encoding.ASCII);
}
public static string ReadFromLargeFile(string path)
{
return File.ReadAllText(path, Encoding.ASCII);
}
/// <summary>
/// 将文件全部读成string类型进行传递
/// </summary>
/// <param name="path"></param>
/// <returns></returns>
public string ReadFromFile(string path)
{
return File.ReadAllText(path, Encoding.ASCII);
}
/// <summary>
/// 打印前maxline个排序后的单词。为0则全部打印
/// </summary>
/// <param name="sortedWord"></param>
/// <param name="maxline"></param>
public void Print(Dictionary<string, int> sortedWord, int maxline = 0)
{
if (maxline != 0)
{
int i = 0;
foreach (KeyValuePair<string, int> item in sortedWord)
{
Console.WriteLine(item.Key + " " + item.Value);
if (i == maxline)
break;
i++;
}
}
else
{
foreach (KeyValuePair<string, int> item in sortedWord)
{
Console.WriteLine(item.Key + " " + item.Value);
}
}
}
}
这样就将命令行的输入输出剥离开来。
接下来就是对核心计算功能的剥离了。为了保证代码后续的升级,所以通过接口定义三个功能函数:
interface ICore
{
/// <summary>
/// 获得全部字母数量
/// </summary>
/// <returns></returns>
int GetCharNum();
/// <summary>
/// 获得全部单词数量
/// </summary>
/// <param name="wordsCount"></param>
/// <returns></returns>
int GetWordNum(Dictionary<string, int> wordsCount);
/// <summary>
/// 获取排序后的单词集
/// </summary>
/// <param name="wordsCount"></param>
/// <returns></returns>
Dictionary<string, int> SortAndGetWord(Dictionary<string, int> wordsCount);
}
这三个方法就是对需要剥离的三个功能的规范抽象。在这三个方法下面对三个功能进行详细实现。代码和第一步完全一样,只是重新拆分开了,所以就不在赘述。
俊老板比我细心,基本都是我敲错了他一眼就发现了,所以代码编写起来比较快速。
然后是对核心功能进行测试,一共三个功能。所以分别写了三条测试语句来对核心计算进行测试。首先是生成动态链接库。在VS中的项目属性修改输出类型为类库,
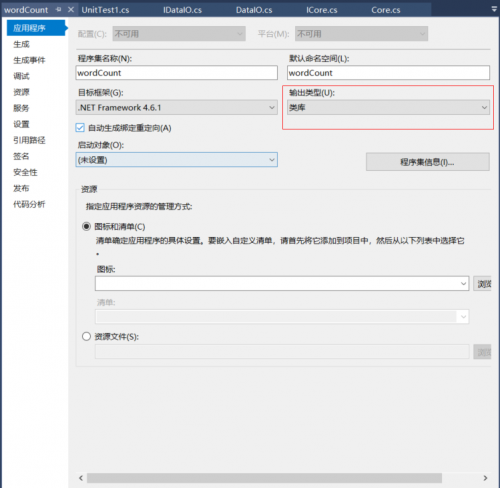
在重新生成一次,到Debug文件夹中进行查看,就已经生成DLL了。
在单元测试中添加对这个DLL的引用,在添加using wordCount使用命名空间之后,就可以调用方法验证算法是否正确。但是...尽管我对其添加了引用,最后无法使用命名空间。
查阅资料无果后,俊老板和我分开尝试怎么样才能使用dll。最后我发现当新建的项目是动态链接库项目的时候,就能够正常引用dll。最后没有办法,只好新建一个动态链接库项目,然后将类拷贝过去。
最后在wordCounter里面完成单元测试
- 统计字符数。这个是真的深有体会,不做不知道,一做吓一跳,原来代码有这么多错误的地方之前没观察到。主要出现的错误有如果只有一行会多算一个字符、中文字符也被计算在内。一一改正之后进行测试,测试字符数所用代码如下:
[TestClass]
public class UnitTest1
{
[TestMethod]
public void TestMethod1()
{
string content = File.ReadAllText("test.txt");
ICore core = new Core(content);
Assert.AreEqual(93, core.GetCharNum());
}
}

2.统计单词数。类似于第一个测试,测试代码如下:
[TestMethod]
public void TestMethod2()
{
string content = File.ReadAllText("test.txt");
Dictionary<string, int> words = new Dictionary<string, int>();
ICore core = new Core(content);
core.GetCharNum();
Assert.AreEqual(6, core.GetWordNum(words));
}
本以为也会完美通过,结果出现错误。

3.统计前10个单词的输出。字符串匹配我门还真不知道怎么测试,所以对一开始打算直接输出,俊老板说那根本就不是测试...最后,我和俊老板得出一个折中的方案,用StringAssert测试字符串,输出的字符串使用foreach拼接
[TestMethod]
public void TestMethod3()
{
string content = File.ReadAllText("test.txt");
Dictionary<string, int> words = new Dictionary<string, int>();
ICore core = new Core(content);
core.GetCharNum();
core.GetWordNum(words);
string test="file1234 2\ndsfdsfsd5421 1\nhello 1\nwindows2000 1\nwindows95 1\nwindows98 1\n";
words = core.SortAndGetWord(words);
string actual = "";
foreach (KeyValuePair<string, int> pair in words)
{
actual += pair.Key + " " + pair.Value + "\n";
}
StringAssert.Equals(test, actual);
}

测试完成之后,基本的计算功能就有了保障。赶紧提交到Git进行保存。

接着开始对其进行功能上面的拓展。
新增的-i、-m、-n、-o这四个参数匹配就只有设定单词词组和输出到文件是新的需要实现的功能,首先是对单词词组的实现,因为涉及到词组的频次,故还是使用Dictionary<string,int>来保存数据,而对于词组的构造,就是根据设定的长度,利用双重for循环进行词组拼接。代码如下
/// <summary>
/// 获得指定长度的词组
/// </summary>
/// <param name="words"></param>
/// <param name="len"></param>
/// <returns></returns>
public static Dictionary<string, int> GetWordGroup(List<string> words, int len = 3)
{
Dictionary<string, int> wordsGroup = new Dictionary<string, int>();
for (int j = 0; j<words.Count;j++)
{
string wordsRelation = "";
if (j <= words.Count - len )
{
for (int i = j; i < j+len; i++)
{
wordsRelation += words[i] + " ";
}
if (wordsGroup.ContainsKey(wordsRelation))
{
wordsGroup[wordsRelation]++;
}
else
{
wordsGroup.Add(wordsRelation, 1);
}
}
}
return wordsGroup;
}
对于-o的写出倒没有什么问题,读入在之前就已经实现了,现在写出到文件和其原理基本相似。写出的代码如下:
public void WriteToFile(string path,string content)
{
using (System.IO.StreamWriter file = new System.IO.StreamWriter(path))
{
string line = "";
using (StringReader sr = new StringReader(content))
{
while ((line = sr.ReadLine()) != null)
{
file.WriteLine(line);
}
}
}
}
传入写出到文件的content就需要自己构造了。利用字符串拼接,按照作业指导中的格式,构造出符合规范的词组,构造方法如下:
int charNum = core.GetCharNum();
int wordNum = core.GetWordNum(words);
words = core.SortAndGetWord(words);
wordsGroup=GetWordGroup(((Core)core).Lists,m);
string wordsGroupContent = "";
foreach (KeyValuePair<string, int> wordsPair in wordsGroup)
{
wordsGroupContent += wordsPair.Key + ": " + wordsPair.Value + "\n";
}
string wordsCountContent = io.Print(words, n);
string fullContent = "characters: " + charNum + "\n" +
"words: " + wordNum + "\n" +
"lines: " + ((Core)core).LineCount + "\n\n" +
wordsGroupContent + "\n"+
wordsCountContent;
再次提交到Git完成保存,就准备完成图形化界面绘制。

接下来进入到第四步,是对图形化界面的实现。我们采用WinForm的形式完成对图形化界面的绘制,这部分主要是由俊老板实现,我对他代码进行审核。
下面是俊老板绘制的图形界面
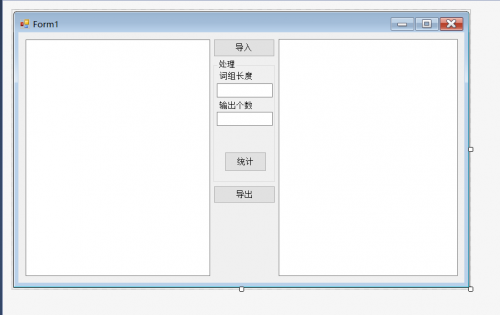
关于事件的基本就是一个输入输出OpenFileDialog和SaveFileDialog进行保存,其余的统计都是在前面第三步的wordCount项目中做好了的,直接调用就好了。所以,图形化界面制作整体比较简单。但是调试的时候遇到一个有趣的问题。如图:
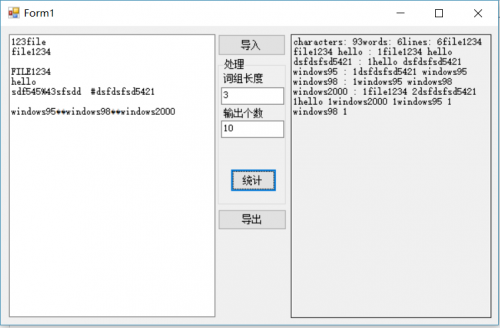
右边的统计结果很明显没有了换行,可是刚刚第三步的代码中我明明添加了\n换行符,并且在命令行中也能够正常显示。查阅资料后得知(参考博客https://www.cnblogs.com/shouhouxiaomuwu/p/3424637.html),Windows的界面换行符是\r\n,而命令行中是任意的,就是\n和\r\n都是可以的。因此,修改原有代码,成功解决问题。
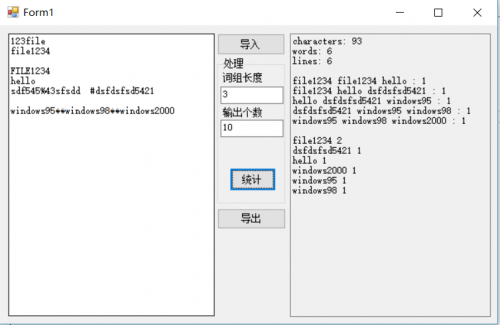
最后上传Git完成编写工作。
单元测试
按照需求分析,我们在单元测试这里准备了10个测试用例来保证程序健壮性
- 输出格式测试
测试用例:
测试代码:
string content = File.ReadAllText("test.txt");
Dictionary<string, int> words = new Dictionary<string, int>();
ICore core = new Core(content);
core.GetCharNum();
core.GetWordNum(words);
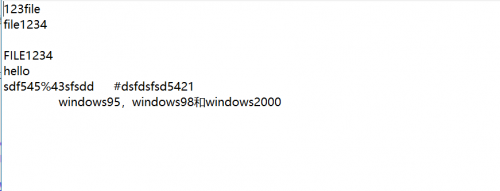
string test="file1234 2\ndsfdsfsd5421 1\nhello 1\nwindows2000 1\nwindows95 1\nwindows98 1\n";
words = core.SortAndGetWord(words);
string actual = "";
foreach (KeyValuePair<string, int> pair in words)
{
actual += pair.Key + " " + pair.Value + "\n";
}
StringAssert.Equals(test, actual);
测试结果:
- 字母、单词、行数统计的测试
测试用例:
测试代码:
[TestMethod]
public void TestMethod1()
{
string content = File.ReadAllText("test.txt");
ICore core = new Core(content);
Assert.AreEqual(93, core.GetCharNum());
}
[TestMethod]
public void TestMethod2()
{
string content = File.ReadAllText("test.txt");
Dictionary<string, int> words = new Dictionary<string, int>();
ICore core = new Core(content);
core.GetCharNum();
Assert.AreEqual(6, core.GetWordNum(words));
}
测试结果:
- 前10个频次最高按照字典排序的单词测试
测试用例:

测试代码:
[TestMethod]
public void TestMethod4()
{
string test = "confidence 3\nyourself 3\nadmiration 1\nahead 1\narrogant 1\nchallenges 1\ndizzy 1\nenergy 1\nextremely 1\nfarewell 1\n";
string content = File.ReadAllText("test1.txt");
Dictionary<string, int> words = new Dictionary<string, int>();
ICore core = new Core(content);
core.GetCharNum();
core.GetWordNum(words);
words = core.SortAndGetWord(words);
string actual = "";
foreach (KeyValuePair<string, int> pair in words)
{
actual += pair.Key + " " + pair.Value + "\n";
}
StringAssert.Equals(test, actual);
}
测试结果:
- 对于非ascii码的处理测试
测试用例:

测试代码:
[TestMethod]
public void TestMethod5()
{
string test = "sdfs 2\ndfdsf 1\ndffs 1\nsdfsf 1";
string content = File.ReadAllText("test2.txt");
Dictionary<string, int> words = new Dictionary<string, int>();
ICore core = new Core(content);
core.GetCharNum();
core.GetWordNum(words);
words = core.SortAndGetWord(words);
string actual = "";
foreach (KeyValuePair<string, int> pair in words)
{
actual += pair.Key + " " + pair.Value + "\n";
}
StringAssert.Equals(test, actual);
}
测试结果:
- 读入文件非法文件名测试
测试用例:
测试代码:
[TestMethod]
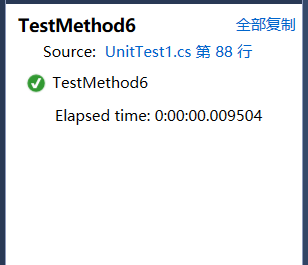
public void TestMethod6()
{
string content = "";
if (File.Exists("test10.txt"))
{
content = File.ReadAllText("test10.txt");
}
else
{
content = "文件名不正确请检查...";
}
StringAssert.Equals("文件名不正确请检查...", content);
}
测试结果:
- 输出文件非法文件名测试
测试用例:
测试代码:
[TestMethod]
public void TestMethod7()
{
IDataIO data = new DataIO();
string path = "??T>>Txsd>test.txt";
data.WriteToFile(path, "hello");
bool exist = File.Exists(path);
Assert.AreEqual(false, exist);
}
测试结果:

- 词组长度测试
测试用例:
测试代码:
[TestMethod]
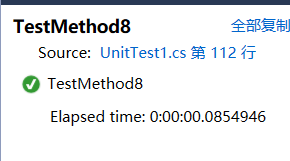
public void TestMethod8()
{
string test = "dffs sdfs sdfsf : 1\nsdfs sdfsf dfdsf: 1\nsdfsf dfdsf sdfs: 1\n";
string content = File.ReadAllText("test1.txt");
Dictionary<string, int> words = new Dictionary<string, int>();
Dictionary<string, int> wordsGroup = new Dictionary<string, int>();
ICore core = new Core(content);
IDataIO io = new DataIO();
int charNum = core.GetCharNum();
int wordNum = core.GetWordNum(words);
words = core.SortAndGetWord(words);
wordsGroup = Program.GetWordGroup(((Core)core).Lists, 3);
string wordsGroupContent = "";
foreach (KeyValuePair<string, int> wordsPair in wordsGroup)
{
wordsGroupContent += wordsPair.Key + ": " + wordsPair.Value + "\n";
}
StringAssert.Equals(test, wordsGroupContent);
}
测试结果:
- -m -n 后不是数字的处理

测试代码:
wordCount.exe -i test2.txt -m heelo -n fdsfsf -o output.txt
测试结果:

- 意外情况处理测试

测试代码:
[TestMethod]
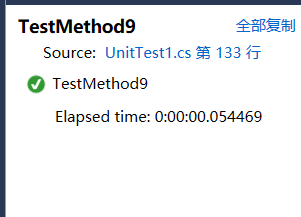
public void TestMethod9()
{
string content = File.ReadAllText("test3.txt");
ICore core = new Core(content);
Assert.AreEqual(46, core.GetCharNum());
}
测试结果:
- 输入错误的处理
由于无法对命令行进行单元测试,这里使用人工测试
测试用例:
测试代码:
wordCount.exe -i test2.txt -x -xdsdsfd -o output.txt
测试结果:

效能分析
由于命令行工具在效能分析中无法使用,所以为了方便查看效率,就将输出目录和输入目录直接硬编码在程序中,本次效能分析使用小说《苏菲的世界》英中对照版进行测试

在性能查看器中选择查看CPU效率,分析结果如下图:
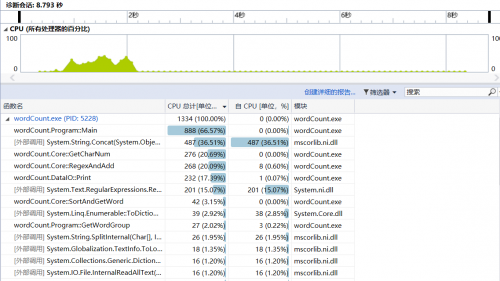
从图中可以看到,CPU开销最大的就是Main()函数,当然这是因为Main()函数中包括了全部的调用方法。双击进入Main()函数:
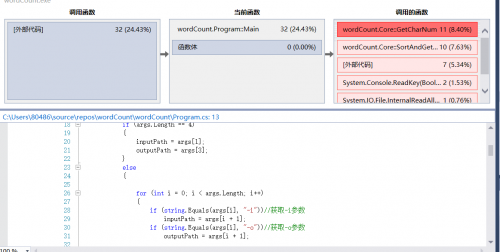
生成详细报告之后,查看执行单个工作最多的函数:
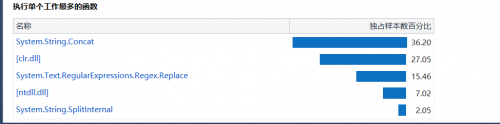
从上图我们可以看到,调用最多的是字符串拼接函数Concat(),应该是我在输出到output.txt中的时候,为了使格式统一,用了大量的字符串拼接。但是虽然调用次数多,效率不一定低。所以继续查看
点击查看消耗最大的Main()函数,查看代码占用效率:

从图中可以看出来,消耗主要是在GetCharNum()、wordsGroupContent += wordsPair.Key + ": " + wordsPair.Value + "\n";、string wordsCountContent = io.Print(words, n);这三句。我们挨个进行分析。
首先进入GetCharNum()函数查看:

这里消耗最大的代码就是正则表达式...这可咋优化啊。正则表达式的主要消耗在于它的“回溯”匹配,只要减少“回溯”次数,就能够提高效率。但是匹配Ascii以外得字符除了string regexStr1 = Regex.Replace(line, @"[^\u0000-\u007F]+", string.Empty);这一句,也没有其他更好的方法了。只能转而优化其他。
查看另外两个消耗比较大的代码,得出一个惊人的发现。消耗最大的都是字符拼接处理:


我和俊老板想了一下,修改C#的字符串拼接方式应该可以改进性能。因此,参考博客https://blog.csdn.net/yeshennet/article/details/51435409后决定,将两个“重灾区”代码改用StringBuilder.Append()函数进行优化。

重新探查性能之后之后查看分析报告:
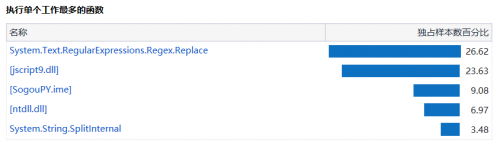
性能大大提升,提高了程序效率。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 15 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | 4320 | 6182 |
| · Analysis | · 需求分析 (包括学习新技术) | 720 | 720 |
| · Design Spec | · 生成设计文档 | 240 | 120 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 240 | 120 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 240 | 120 |
| · Design | · 具体设计 | 1080 | 2880 |
| · Coding | · 具体编码 | 360 | 1440 |
| · Code Review | · 代码复审 | 720 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 720 | 720 |
| Reporting | 报告 | 720 | 660 |
| · Test Report | · 测试报告 | 360 | 360 |
| · Size Measurement | · 计算工作量 | 180 | 180 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 180 | 120 |
| 合计 | 5060 | 6917 |
总结
结对编程从编程效率上来说,确实不容易出现错误和低质量代码。可是在做需求分析的时候,两个人做分析容易导致意见分歧,如果没有第三个人,就很容易互相僵持,走入死胡同。老师上课讲的,两个人互相监督的效果我们也没有达到,应该说不是体制问题,是我们自身要求没有达到。导致后面快做完的时候,效率非常低下,都一起打游戏了,正好双排上分。所以,我认为,在编程环节,是1+1>2的,但是项目需求分析和项目收尾的时候,往往会出现1+1<1的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号