【研发过程质量分析可视化】剩余需求实现(数据处理、数据可视化)
需求描述

需求实现:
一、数据预处理,接收不同项目的缺陷清单(pandas)——dataInput.py
1、考虑到后续要分析多个项目,即有可能会导出多个项目的缺陷清单,因此专门写一个dataInput.py用于接收不同的excel,并转换成pandas的dataFrame数据。
#-*-coding:utf-8 -*- import pandas as pd import os def getDataFromChandaoForALL(): ''' 从禅道获取excel数据,注意要手动把文件改成excel的xlsx格式,这里返回整个excel数据 :return:经pandas转换的待处理excel ''' dflist=[] proname=[] path = 'DataFromChandao' for excel in os.listdir(path): name,ext=os.path.splitext(excel) #将文件夹下的每个excel的名称和扩展名拆分出来,后面生成html时用到这里的文件名 df=pd.read_excel(os.path.join(path,excel)) # 读取本次要操作的原始数据,即从禅道导出的遗留问题清单 dflist.append(df) proname.append(name) pass result={ 'dflist':dflist, 'proname':proname } # print(result) return result
2、考虑到后续每个项目要生成单独的html,这些html的命名要以项目的名称来命名,因此约定待分析的excel是已项目名称命名后,程序直接取到这些文件名作为项目名称。
二、数据精处理,得出项目不同质量维度指标(pandas)——dataProcessing.py
1、定义数据处理类,用于分析某个项目不同的质量维度数据。由于可能存在多个待分析的项目,因此在类中要传入参数:项目的dataFrame;
2、将每个项目的 缺陷解决率、 严重缺陷率等等计算出来,也已dataFrame形式返回;如果有新的待计算指标,就在dataProcessing.py中维护。
3、这里用到的一些分析字段为导出excel中的列名称,目前程序中写的是符合禅道导出excel的列名称的。如果后面换成jira等系统,这些字段要重新维护,或者重新写个新的类。
#-*-coding:GBK -*- # 导入pandas用于处理excel工具 import pandas as pd # 导入柱形图 import dataInput class DataProcessingInChandao: ''' 该类,仅给禅道导出的缺陷使用.代码中的汉字为导出禅道清单中的关键列标题。 ''' def __init__(self,dataframe): ''' :param df: 传入的pandas待处理excel,从dataInput而来。可以传入整体的缺陷列表,页可以传入按月拆分后的缺陷列表,均可进行分析。 ''' self.df=dataframe self.bugStatusCounts = self.getnumCounts('Bug状态') #缺陷关闭情况分析 self.bugResolutionRate = self.getRate(self.bugStatusCounts, '缺陷解决率') # 缺陷解决率 self.unresolvedBugList= self.getbuglist('未关闭缺陷') # 未关闭缺陷列表 self.severityCounts = self.getnumCounts('严重程度') #严重缺陷分析 self.severityBugProportion = self.getRate(self.severityCounts, '严重缺陷率') # 严重缺陷率 self.severityBugList = self.getbuglist('严重缺陷') # 严重缺陷列表 self.checkNoPassCounts = self.getcheckNoPassCounts() #验证不通过缺陷分析 self.checkNoPassBugProportion = self.getRate(self.checkNoPassCounts, '验证不通过率') # 验证不通过率 self.checkNoPassBugList = self.getbuglist( '验证不通过缺陷') # 验证不通过缺陷列表 self.lowLevelBugCounts = self.getlowLevelBugCounts() #低级缺陷分析 self.lowLevelBugProportion = self.getRate(self.lowLevelBugCounts, '低级缺陷率') # 低级缺陷率 self.lowLevelBugList = self.getbuglist('低级缺陷') # 低级缺陷列表 self.creatimeCounts = self.gettrendCounts( '创建日期') #每日新增缺陷数 self.closetimeCounts = self.gettrendCounts('关闭日期') #每日解决缺陷数 self.moduleCounts = self.getnumCounts('所属模块') #缺陷按模块分析 self.bugTypeCounts = self.getnumCounts('Bug类型') #缺陷按类型分析 self.bugFixerCounts = self.getnumCounts('解决者') #缺陷创建/解决者分析 self.bugFinderCounts = self.getnumCounts('由谁创建') #缺陷发现者分析 def getRate(self,dataFrame,type): x = dataFrame['数量'].sum() if type=='缺陷解决率': y = dataFrame.loc[dataFrame['Bug状态'].isin(['已关闭']), '数量'].sum() elif type=='严重缺陷率': y = dataFrame.loc[dataFrame['严重程度'].isin(['严重','重要']), '数量'].sum() elif type=='验证不通过率': y = dataFrame.loc[dataFrame['验证情况'].isin(['验证不通过']), '数量'].sum() elif type=='低级缺陷率': y = dataFrame.loc[dataFrame['低级缺陷情况'].isin(['低级缺陷']), '数量'].sum() result=round(y/x,3) #保留小数点后4位 return result def getbuglist(self, listType): ''' 适用于筛选出关键维度的缺陷列表,如验证不通过的缺陷列表 :param self.df: 传入原始的dataFrame数据,如禅道导出的遗留缺陷清单 :param listType: 需要给出的缺陷列表维度,如给出严重缺陷列表 :return: 返回清洗后的dataFrame数据 ''' if listType == '严重缺陷': Counts = self.df.loc[self.df['严重程度'].isin(['严重','重要']), ['Bug编号','Bug标题','严重程度','Bug状态']] elif listType == '低级缺陷': Counts = self.df.loc[self.df['Bug标题'].str.contains('【低级缺陷】'), ['Bug编号','Bug标题','解决者','Bug状态']] # 统计低级缺陷个数,即BUG标题中含有【低级缺陷】的个数,先过滤一遍 elif listType == '验证不通过缺陷': Counts = self.df.loc[self.df['激活次数']>0,['Bug编号','Bug标题','指派给','Bug状态']] elif listType == '未关闭缺陷': # Counts = self.df.loc[(self.df['Bug状态'].isin(['已解决', '激活']))&(self.df['严重程度'].isin(['严重','重要'])), ['Bug编号', 'Bug标题', '严重程度', 'Bug状态']] #这统计严重以上缺陷 Counts = self.df.loc[self.df['Bug状态'].isin(['已解决', '激活']), ['Bug编号', 'Bug标题', '严重程度','Bug状态']] #这个统计全部遗留缺陷 return Counts def getnumCounts(self,columnsName): """ 适用于筛选后按统计数量倒序排序,比如缺陷按照模块分布、缺陷按类型分布等 :param self.df: 传入原始的dataFrame数据,如禅道导出的遗留缺陷清单 :param columnsName: 列名称,如统计每个模块的缺陷数,则这里填入'所属模块' :param unresolvedBugCounts:本次是否统计遗留缺陷中按等级分布的情况 :return:返回清洗后的dataFrame数据 """ df_tmp=self.df.groupby(columnsName,as_index=False).apply(len) # 按模块分类后,获取每个模块的数量(即长度) df_tmp.columns=[columnsName,'数量'] #上述步骤获取的结果,数量一列列名为NaN,这里重新命名 Counts=df_tmp.sort_values(by='数量',ascending=False) #按照数量进行倒序排序 return Counts def gettrendCounts(self,columnsName): """ 适用于筛选后按时间顺序排序,比如缺陷创建、关闭趋势 :param self.df: 传入原始的dataFrame数据,如禅道导出的遗留缺陷清单 :param columnsName: 列名称,如统计每个模块的缺陷数,则这里填入'所属模块' :return:返回清洗后的dataFrame数据 """ df_tmp=self.df.loc[~self.df[columnsName].isin(['0000-00-00']),:] #先清洗掉数据中时间为0000-00-00的无效数据 df_tmp=df_tmp.groupby(columnsName,as_index=False).apply(len) # 按模块分类后,获取每个模块的数量(即长度) df_tmp.columns=[columnsName,'数量'] #上述步骤获取的结果,数量一列列名为NaN,这里重新命名 Counts=df_tmp.sort_index(ascending=True) #倒序排序 return Counts def getcheckNoPassCounts(self): """ 适用于验证不通过缺陷的统计 :param self.df: 传入原始的dataFrame数据,如禅道导出的遗留缺陷清单 :return:返回清洗后的dataFrame数据 """ checkNoPass=len(self.df.loc[self.df['激活次数']>0,:]) #激活次数大于0,表示问题验证不通过 # checkPass=len(self.df)-checkNoPass #验证通过次数=总缺陷数-验证不通过次。此逻辑和禅道统计激活次数保持一致,但是不符合实际的逻辑。 checkPassCondition=(self.df['Bug状态'].isin(['已关闭'])) | ((~self.df['Bug状态'].isin(['已关闭'])) & (self.df['激活次数'] > 0)) #实际,验证的缺陷次数=关闭状态的缺陷+激活/已解决状态下激活次数大于0的缺陷数 checkPass = len(self.df.loc[checkPassCondition,:]) Counts=pd.DataFrame({'验证情况':['验证不通过','验证通过'],'数量':[checkNoPass,checkPass]}) return Counts def getlowLevelBugCounts(self): """ 适用于低级缺陷的统计 :param self.df: 传入原始的dataFrame数据,如禅道导出的遗留缺陷清单 :return:返回清洗后的dataFrame数据 """ lowLevelBugCount = len(self.df.loc[self.df['Bug标题'].str.contains('【低级缺陷】'), :]) #统计低级缺陷个数,即BUG标题中含有【低级缺陷】的个数,先过滤一遍 highLevelBugCount = len(self.df) - lowLevelBugCount # 非低级缺陷=总缺陷数-低级缺陷数 Counts = pd.DataFrame({'低级缺陷情况': ['低级缺陷', '非低级缺陷'], '数量': [lowLevelBugCount, highLevelBugCount]}) return Counts
三、数据可视化,定义不同图形的能力(pyecharas)——dataVisualization.py
1、定义数据可视化类,接收要画图的dataFrame(某个项目中已处理过的某质量维度数据,如严重缺陷率)+图形的标题(如严重缺陷分析),调用指定函数画出相应的图形(如饼图、水球图等);
2、由于不同的指标可能画出不同的图形,需根据使用者的思考来组合。因此这里不会将传入的数据初始化画出所有的图形,而是后续用户自行调用;
3、目前定义了表格、日历图、饼图、柱状图等等,后续可根据需要逐步添加,另外表格的一些参数也是在这里定义的(dataProcessing.py)。
#-*-coding:GBK -*- # 导入pandas用于处理excel工具 import pandas as pd # 导入柱形图 from pyecharts.charts import Bar,Pie,Line,WordCloud,Liquid,Gauge,Calendar,Funnel from pyecharts.components import Table from pyecharts.options import ComponentTitleOpts from pyecharts.commons.utils import JsCode # 导入page图 from pyecharts.charts import Page # 导入全局变量 from pyecharts import options as opts # 导入输出图片工具 from pyecharts.render import make_snapshot # 使用snapshot-selenium 渲染图片 from snapshot_selenium import snapshot import datetime import random class DataVisualization: def __init__(self,dataframe,titlename): self.df=dataframe self.title=titlename #表格 def table(self): """ 根据传入的dataFrame和titlename,生成条形图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ table=Table() # print(self.df) headers =self.df.columns.tolist() #表格列名称 # print(headers) rows = [] #获取表格每行数据,已字符串存储在列表中 for i in range(self.df.shape[0]): rowstmp = [] for j in range(self.df.shape[1]): rowstmp.append(str(self.df.iloc[i, j])) rows.append(rowstmp) pass # print(rows) table.add(headers, rows) table.set_global_opts( title_opts=ComponentTitleOpts(title=self.title), # 定义图表主标题 ) table.add_js_funcs("""function(params) {window.open(www.baidu.com);}""") return table #日历图 def calendar(self): """ 根据传入的dataFrame和titlename,生成条形图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ data = [ [str(self.df.iloc[i, 0]), int(self.df.iloc[i, 1])] # 从传入的dataFrame中获取第二列的所有数据,注意第一个参数一定要是str(括号内的是时间类型),第二个参数一定要是int for i in range(len(self.df)) ] nowYear=str(datetime.datetime.now().year) #注意一定要传入和dataFrame数据中相同的年份,默认使用当年,否则画出的图会不显示数据 calendar=Calendar() calendar.add( series_name="", yaxis_data=data, calendar_opts=opts.CalendarOpts( range_=nowYear, daylabel_opts=opts.CalendarDayLabelOpts(name_map="cn"), monthlabel_opts=opts.CalendarMonthLabelOpts(name_map="cn"), ), ) # 定义图标全局变量,定义图标主标题和副标题 calendar.set_global_opts( title_opts=opts.TitleOpts(title=self.title), visualmap_opts=opts.VisualMapOpts( max_=20, min_=0, orient="horizontal", is_piecewise=True, pos_top="230px", pos_left="100px", ), ) return calendar #仪表图 def gauge(self,rate): """ 根据传入的dataFrame和titlename,生成条形图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ gauge=Gauge() gauge.add( # series_name=self.title, #如果要设置仪表盘上方的title,可以设置此属性 series_name='', data_pair=[(self.title,round(rate*100,1))], min_ = 0, max_ = 25, #仪表盘最大显示的数字大小,根据业务情况自己设置 split_number=5, #分割次数,即max除去split_number得到仪表盘拆分成几等份 radius="60%", #仪表盘的大小显示,太大了比较丑 axisline_opts=opts.AxisLineOpts( linestyle_opts=opts.LineStyleOpts( color=[(1 / 5, "#91C7AE"), (2 / 5, "#63869E"), (1, "#C23531")], width=30 #设置仪表盘中不同颜色及颜色显示的占比 )), title_label_opts=opts.LabelOpts( font_size=20, #设置仪表盘内文字的大小 ), detail_label_opts=opts.LabelOpts( font_size=25, #设置百分比数字的大小,必须设置大一点,否则显示上和标题重合 formatter="{value}%" #上面设置了百分比数字的大小,这里必须设置这参数,否则数值不显示百分号 ), ) # 定义图标全局变量,定义图标主标题和副标题 gauge.set_global_opts( title_opts=opts.TitleOpts(title=self.title), #定义图表主标题 legend_opts=opts.LegendOpts(is_show=False), tooltip_opts=opts.TooltipOpts(is_show=True, formatter="{a} <br/>{b} : {c}%"), ) return gauge #水球图 def liquid(self,rate): """ 根据传入的dataFrame和titlename,生成条形图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ # 定义柱状图变量 liquid=Liquid() liquid.add( self.title, [rate], # is_outline_show=False, label_opts=opts.LabelOpts( font_size=50, formatter=JsCode( """function (param) { return (Math.floor(param.value * 10000) / 100) + '%'; }""" ), position="inside", ), ) # 定义图标全局变量,定义图标主标题和副标题 liquid.set_global_opts( title_opts=opts.TitleOpts(title=self.title), #定义图表主标题 ) return liquid #柱状图 def bar(self): """ 根据传入的dataFrame和titlename,生成条形图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ # 定义柱状图变量 bar=Bar() # 定义柱状图X轴 bar.add_xaxis(self.df.iloc[:,0].tolist()) # 定义柱状图Y轴 bar.add_yaxis('缺陷量',self.df.iloc[:,1].tolist(),category_gap="60%") # 定义图标全局变量,定义图标主标题和副标题 bar.set_global_opts( title_opts=opts.TitleOpts(title=self.title), #定义图表主标题 xaxis_opts=opts.AxisOpts(axislabel_opts={"interval": "0",'rotate':-45}), #定义图表X轴标签显示的个数,显示的角度 legend_opts = opts.LegendOpts(type_="scroll", pos_left="right", orient="vertical") #定义图表的图例位置 ) bar.set_series_opts( # label_opts=opts.LabelOpts(is_show=False), #这个用于取消柱状图上方的数字标签 markline_opts=opts.MarkLineOpts( data=[ opts.MarkLineItem(type_="min", name="最小值"), opts.MarkLineItem(type_="max", name="最大值"), opts.MarkLineItem(type_="average", name="平均值"), ] ), ) return bar #折线图 def line(self,color): """ 根据传入的dataFrame和titlename,生成折线图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ # 定义折现图变量 line=Line() # 定义折线图X轴 line.add_xaxis(self.df.iloc[:,0].tolist()) # 定义柱状图Y轴 line.add_yaxis('缺陷量',self.df.iloc[:,1].tolist(),color=color,is_smooth=True,markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average")])) # 定义图标全局变量 line.set_global_opts( title_opts=opts.TitleOpts(title=self.title), #定义图表主标题 xaxis_opts=opts.AxisOpts(axislabel_opts={"interval": "0",'rotate':-45}), #定义图表X轴标签显示的个数,显示的角度 legend_opts = opts.LegendOpts(type_="scroll", pos_left="right", orient="vertical") #定义图表的图例位置 ) return line #饼图 def pie(self): """ 根据传入的dataFrame和titlename,生成饼图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ # 定义饼图 pie=Pie() # 生成饼图所需列表数据 data_pair = [list(z) for z in zip(self.df.iloc[:,0].tolist(), self.df.iloc[:,1].tolist())] # 给饼图增加数据 pie.add( '', data_pair, radius="60%", ) # 定义图标全局变量,定义图标主标题和副标题 pie.set_global_opts( title_opts=opts.TitleOpts(title=self.title), #定义图表主标题 legend_opts = opts.LegendOpts(type_="scroll", pos_left="right", orient="vertical") #定义图表的图例位置 ) # 定义系列数据显示格式,自定义显示格式(b:name, c:value, d:百分比) pie.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c} ({d}%)",is_show=True)) return pie #词云图 def cloud(self): """ 根据传入的dataFrame和titlename,生成词云图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ # 定义词云图变量 cloud=WordCloud() # 生成词云图所需列表数据 data_pair = [list(z) for z in zip(self.df.iloc[:,0].tolist(), self.df.iloc[:,1].tolist())] # 定义词云参数 cloud.add('',data_pair,is_draw_out_of_bound=True) # 定义图标全局变量,定义图标主标题和副标题 cloud.set_global_opts( title_opts=opts.TitleOpts(title=self.title), #定义图表主标题 ) return cloud #漏斗图 def funnel(self): """ 根据传入的dataFrame和titlename,生成词云图,并保存指定名称的图片 :param dataframe: 传入清洗后的dataFrame数据,如清洗后按照模块统计出的各模块缺陷数量 :param titlename: 传入生成图片的名称 :return:返回图形实例,供后续调用 """ funnel=Funnel() # 生成词云图所需列表数据 data_pair = [list(z) for z in zip(self.df.iloc[:,0].tolist(), self.df.iloc[:,1].tolist())] # 定义词云参数 funnel.add('缺陷量',data_pair,label_opts=opts.LabelOpts(position="inside"),) # 定义图标全局变量,定义图标主标题和副标题 funnel.set_global_opts( title_opts=opts.TitleOpts(title=self.title), #定义图表主标题 ) return funnel
四、数据可视化,组合不同的业务数据生成html(pyecharas)——dataRenderHtml.py
1、定义生成业务html的类,接收待分析项目的dataFrame,项目名称(这两个参数在dataInput.py的结果中生成),用于生成最终的html;
2、业务的html按月度、年度等组合在dataRenderHtml.py中定义,目前只生成了个基础的月度数据;
#-*-coding:GBK -*- # 导入page图 from pyecharts.charts import Page,Tab,Grid from pyecharts import options as opts import dataProcessing import dataVisualization class DataRenderHtml: def __init__(self,dataframe,proname): self.df=dataProcessing.DataProcessingInChandao(dataframe) #实例化DataProcessingInChandao,获取待分析缺陷清单各个维度的dataFrame self.proname=proname self.creatHtml() def creatHtml(self): # self.creatThisYearInTab() #单项目维护-年度数据分析,由于暂时没想好年度怎么分析,暂时注释 self.creatThisMonthInTab() #单项目维护-月度数据分析 def creatThisMonthInTab(self): # 待绘制的图 char = [ dataVisualization.DataVisualization(self.df.bugResolutionRate, '缺陷解决率').liquid(self.df.bugResolutionRate), dataVisualization.DataVisualization(self.df.bugStatusCounts, '缺陷关闭情况分析').pie(), # dataVisualization.DataVisualization(self.df.unresolvedBugList, '未关闭缺陷列表').table(), dataVisualization.DataVisualization(self.df.severityBugProportion, '严重缺陷率').gauge(self.df.severityBugProportion), dataVisualization.DataVisualization(self.df.severityCounts, '严重缺陷分析').pie(), # dataVisualization.DataVisualization(self.df.severityBugList, '严重缺陷列表').table(), dataVisualization.DataVisualization(self.df.checkNoPassBugProportion, '验证不通过率').gauge(self.df.checkNoPassBugProportion), dataVisualization.DataVisualization(self.df.checkNoPassCounts, '验证不通过缺陷分析').pie(), # dataVisualization.DataVisualization(self.df.checkNoPassBugList, '验证不通过缺陷列表').table(), dataVisualization.DataVisualization(self.df.lowLevelBugProportion, '低级缺陷率').gauge(self.df.lowLevelBugProportion), dataVisualization.DataVisualization(self.df.lowLevelBugCounts, '低级缺陷分析').pie(), # dataVisualization.DataVisualization(self.df.lowLevelBugList, '低级缺陷列表').table(), dataVisualization.DataVisualization(self.df.bugTypeCounts, '缺陷类型分析').funnel(), dataVisualization.DataVisualization(self.df.moduleCounts, '缺陷模块分析').bar(), dataVisualization.DataVisualization(self.df.creatimeCounts, '缺陷创建趋势分析').line('#C23531'), dataVisualization.DataVisualization(self.df.closetimeCounts, '缺陷关闭趋势分析').line('#008B45'), dataVisualization.DataVisualization(self.df.bugFixerCounts, '缺陷产生/解决者分析').cloud(), dataVisualization.DataVisualization(self.df.bugFinderCounts, '缺陷发现者分析').cloud(), dataVisualization.DataVisualization(self.df.unresolvedBugList, '未关闭缺陷列表').table(), dataVisualization.DataVisualization(self.df.severityBugList, '严重缺陷列表').table(), dataVisualization.DataVisualization(self.df.checkNoPassBugList, '验证不通过缺陷列表').table(), dataVisualization.DataVisualization(self.df.lowLevelBugList, '低级缺陷列表').table(), ] # page = Page(layout=Page.SimplePageLayout,page_title="【月度分析】"+self.proname) page = Page(layout=Page.SimplePageLayout, page_title="【月度分析】" + self.proname) for i in char: page.add(i) page.render(path="【月度质量数据分析】"+self.proname+".html",) return page
五、主函数框架——MAIN.py
1、接收dataInput.py中生成的多个项目dataFrame即项目名称,循环调用dataRenderHtml.py,生成每个项目的html分析报告。
#-*-coding:GBK -*- import dataRenderHtml import dataInput def main(): result=dataInput.getDataFromChandaoForALL() dflist=result['dflist'] proname = result['proname'] # print(dflist) # print(proname) for df,name in zip(dflist,proname): dataRenderHtml.DataRenderHtml(df,name) pass if __name__ == '__main__': main() pass
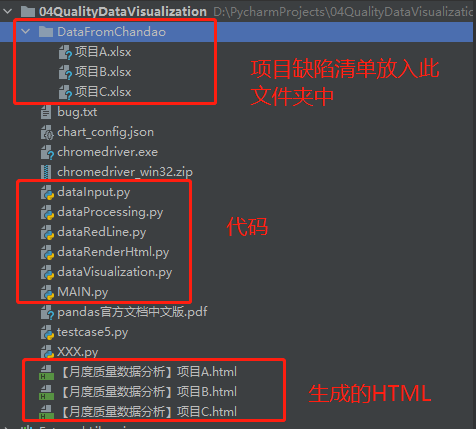
代码框架
最终效果
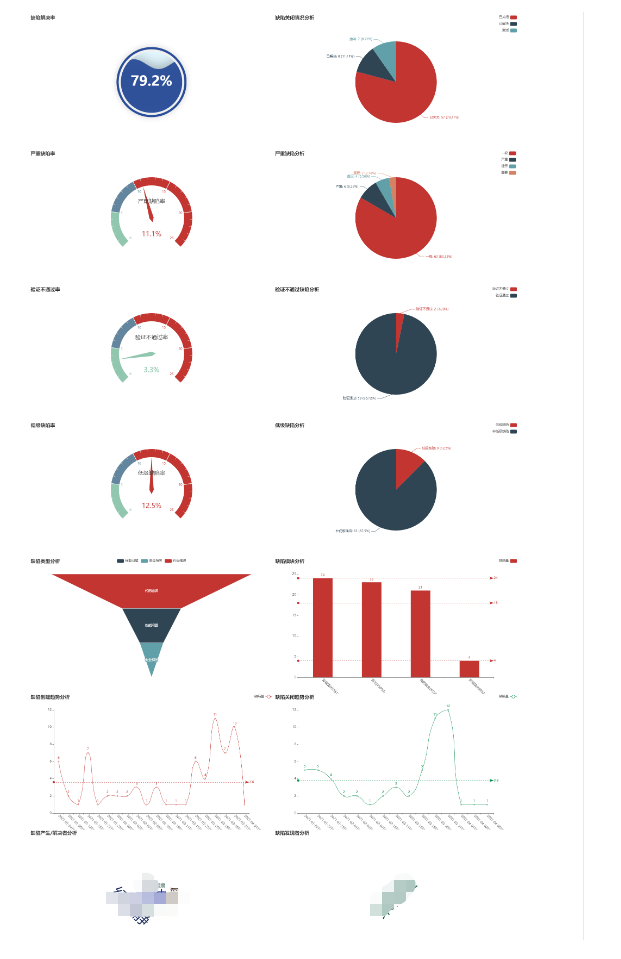
涉及项目数据,就不放完整的图了。
另外,这个图只是简单的图表组合,样式很丑,另外也不太符合不同视角人员的数据获取需求。目前仅算帮助项目的测试人员能较快分析出项目的月度缺陷数据从而写一些报告把。
使用流程

下一步展望
由于本次只是实现了基本的功能,后续仍有很多需完善的地方,目前有如下的思路
1、展示单个项目历史累计的数据,部分展示一些总览数据,部分按照月度展示关键数据变化趋势。
2、展示上美化处理,尽量搞的像可视化大屏;
3、思考不同项目直接横向对比的展示,考虑对比的数据,展示的形式。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号