去除 \ufeff
语言:python
编程工具:pycharm
硬件环境:win10 64位
读取文件过程中发现一个问题:已有记事本文件(非空),转码 UTF-8,复制到pycharm中,在开始位置打印结果会出现 \ufeff, 打印代码如下
f = open('new2.txt', encoding='UTF-8') # 打开文件,以 UTF-8 编码 l = [] for line in f: l.append(line.strip()) print(l)
打印结果为:

只需改一下编码就行,把 UTF-8 编码 改成 UTF-8-sig
f = open('new2.txt', encoding='UTF-8-sig') l = [] for line in f: l.append(line.strip()) print(l)
打印结果为:

utf-8与utf-8-sig两种编码格式的区别:
As UTF-8 is an 8-bit encoding no BOM is required and anyU+FEFF character in the decoded Unicode string (even if it’s the firstcharacter) is treated as a ZERO WIDTH NO-BREAK SPACE.
UTF-8以字节为编码单元,它的字节顺序在所有系统中都是一様的,没有字节序的问题,也因此它实际上并不需要BOM(“ByteOrder Mark”)。但是UTF-8 with BOM即utf-8-sig需要提供BOM。
关于 \ufeff 的一些资料(引自维基百科):
字节顺序标记(英语:byte-order mark,BOM)是位于码点U+FEFF的统一码字符的名称。当以UTF-16或UTF-32来将UCS/统一码字符所组成的字符串编码时,这个字符被用来标示其字节序。它常被用来当做标示文件是以UTF-8、UTF-16或UTF-32编码的记号。
字符U+FEFF如果出现在字节流的开头,则用来标识该字节流的字节序,是高位在前还是低位在前。如果它出现在字节流的中间,则表达零宽度非换行空格的意义,用户看起来就是一个空格。从Unicode3.2开始,U+FEFF只能出现在字节流的开头,只能用于标识字节序,就如它的名称——字节序标记——所表示的一样;除此以外的用法已被舍弃。取而代之的是,使用U+2060来表达零宽度无断空白。
在UTF-16中,字节顺序标记被放置为文件或字符串流的第一个字符,以标示在此文件或字符串流中,以所有十六比特为单位的字码的尾序(字节顺序)。
- 如果十六比特单位被表示成大尾序,这字节顺序标记字符在序列中将呈现
0xFE,其后跟着0xFF(其中的0x用来标示十六进制)。 - 如果十六比特单位使用小尾序,这个字节序列为
0xFF,其后接着0xFE。
而统一码中,值为U+FFFE的码位被保证将不会被指定成一个统一码字符。这意味着0xFF、0xFE将只能被解释成小尾序中的U+FEFF(因为不可能是大尾序中的U+FFFE)。
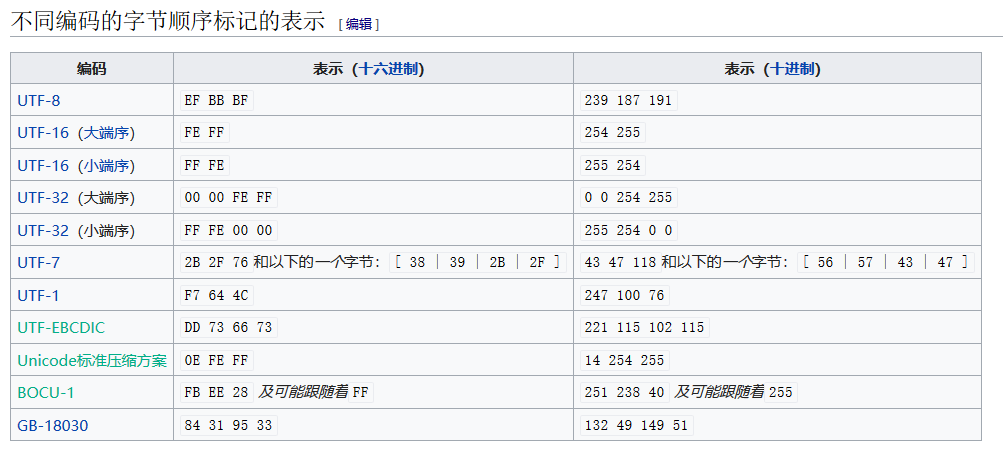
UTF-8则没有字节顺序的议题。UTF-8编码过的字节顺序标记则被用来标示它是UTF-8的文件。它只用来标示一个UTF-8的文件,而不用来说明字节顺序。[1]许多视窗程序(包含记事本)会添加字节顺序标记到UTF-8文件。然而,在类Unix系统(大量使用文本文件,用于文件格式,用于进程间通信)中,这种做法则不被建议采用。因为它会妨碍到如解译器脚本开头的Shebang等的一些重要的码的正确处理。它亦会影响到无法识别它的编程语言。如gcc会报告源码档开头有无法识别的字符。而在PHP中,如果没有激活输出缓冲(output buffering),它会使得页面内容开始被送往浏览器(即:用户头文件已被提交),这使PHP脚本无法指定用户头文件(HTTP Header)。字节顺序标记在UTF-8中被表示为序列EF BB BF,对大部分未准备好处理UTF-8的文本编辑器及网页浏览器而言,在ISO-8859-1的环境中则会显示。
虽然字节顺序标记亦可以用于UTF-32,但这个编码很少用于传输,其规则如同UTF-16。对于已于IANA注册的字符集UTF-16BE、UTF-16LE、UTF-32BE和UTF-32LE等来说,不可使用字节顺序标记。文档开头的U+FEFF会被解释成一个(已舍弃的)"零宽度无断空白",因为这些字符集的名字已决定了其字节顺序。对于已注册字符集UTF-16和UTF-32来说,一个开头的U+FEFF则用来表示字节顺序。