

经典bug之--文件格式不同,带有bom占用了多个字节
背景:
有一个需求,要求上传的文件不能大于某个长度(长度可配置),然后就发现相同的文件内容,但是针对不同编码格式(utf-8、ansi、unicode、unicode big endian),程序中计算的长度会不同。
原因:
由于不同的编码格式,造成了相同文件,会带有bom,占多个字节
解决:
判断头部文件是否带有bom("\uFEFF"),如果有,去掉bom文件,重新计算长度,解决此需求的问题
判断
1.什么是BOM?
BOM是用来判断文本文件是哪一种Unicode编码的标记,其本身是一个Unicode字符("\uFEFF"),位于文本文件头部。
想深入了解的可以查看这篇文章
http://www.fmddlmyy.cn/text6.html
2.如何查看是否携带有bom
使用nopad++,在右下脚可以查看,比如
下面是UTF-8,它带有bom文件
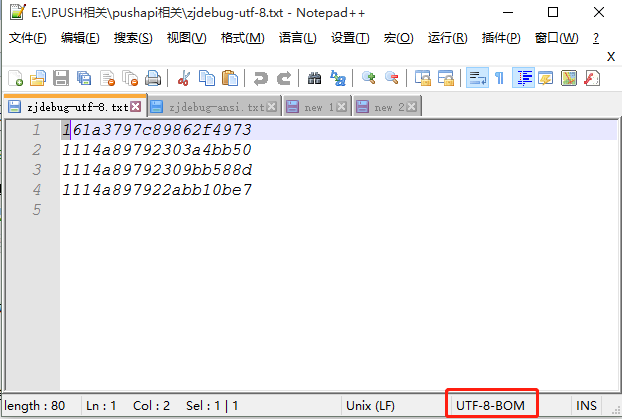
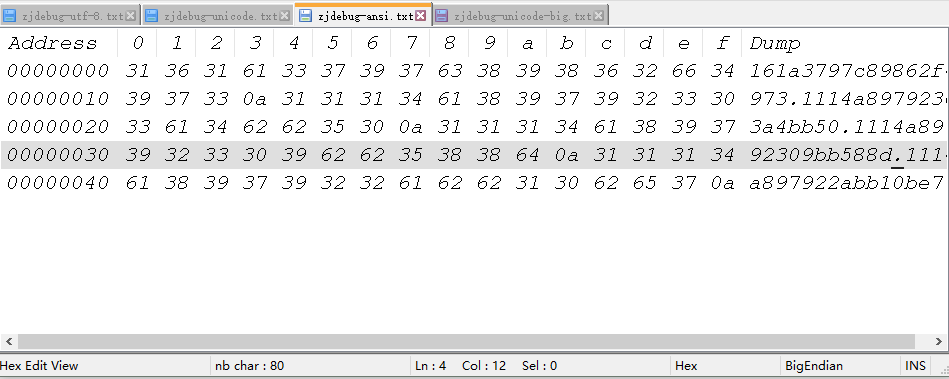
下面是ANSI,它没有bom文件
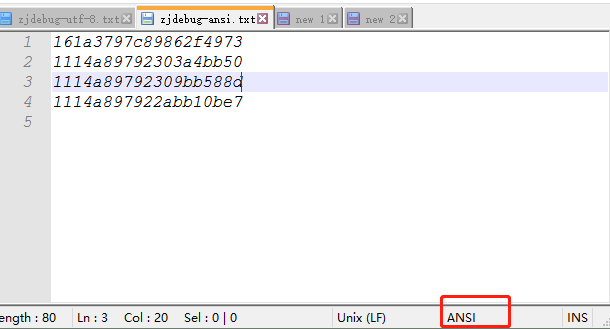
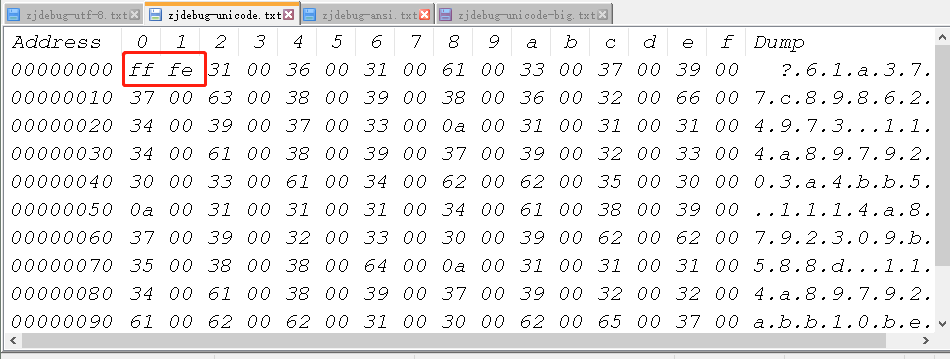
下面是unicode它携带bom
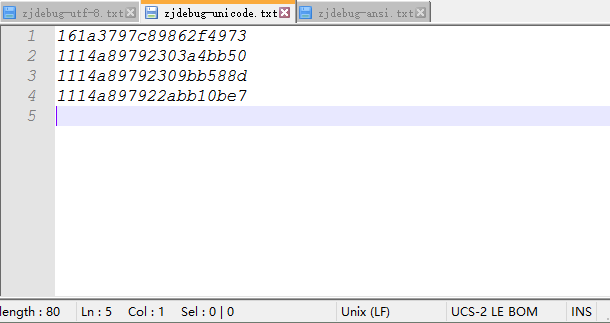
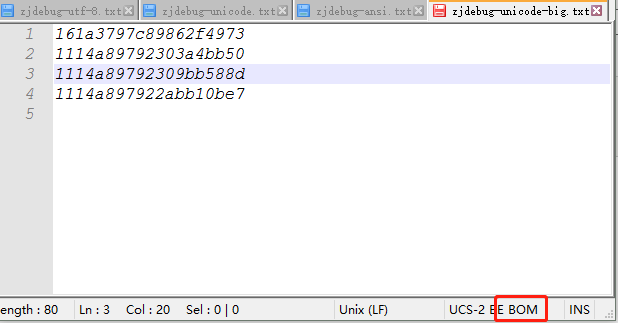
下面是unicode-big它携带bom
3.也可查看前面几个字节编码格式,知道是什么格式
比如utf-8的,前面3位是 EF BB BF,就知道是UTF-8
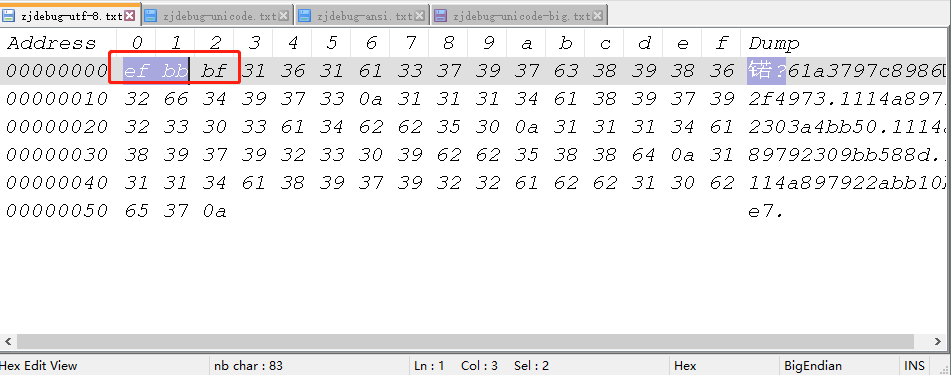
而ansi没有bom,就没有前面那一串
如果开头部分携带了FF FE这个就是携带了bom
关于如何查看,使用notpad++进行查看,插件——>HEX-Editor——>View in HEX。
|
作者:做梦的人(小姐姐) 出处:https://www.cnblogs.com/chongyou/ 本文版权归作者,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。 如果文中有什么错误,欢迎指出。以免更多的人被误导。 微信号:18582559217 |
