hadoop+hive+mysql+sqoop+spark完全分布式集群搭建
hadoop+hive+mysql+sqoop+spark完全分布式集群搭建
零、配置网络(固定ip)
(可以不做,但是后面关闭后ip会重复变动,后面步骤中有再次提到,后面操作在做)
1.固定ip
因centos 7 ip会在重启后不断变化,需要进行固定ip,先在centos 7图形界面中的文件管理器中找到如下地址文件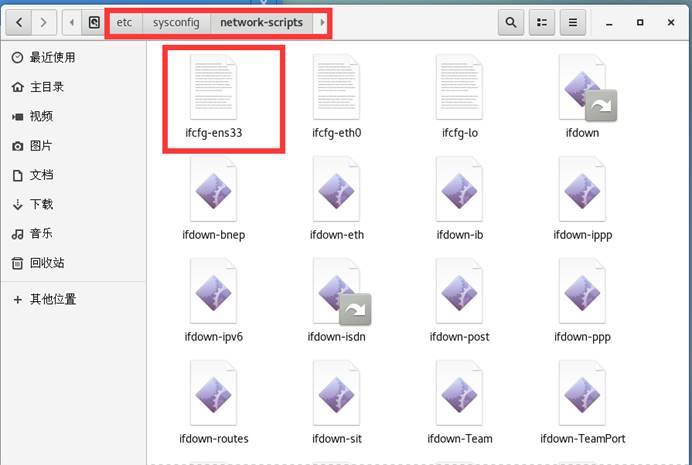
此处我的是红色框中文件,然后利用命令行vi /etc/sysconfig/network-scripts/ifcfg-ens33出现如下如图所示,点击insert进行编辑将BOOTPROTO=dhcp的值改为static,并在最后面加上(后面解释在添加的时候删除):
DNS1=192.168.184.2 --dns地址
IPADDR=192.168.184.135 --需要设置的ip地址
NETMASK=255.255.255.0 --子网掩码
GATEWAY=192.168.184.2 --网关
这里注意,因为静态ip地址设置为192.168.184.135,因此默认网关和DNS地址前面部分,即192.168.184须相同,不然会出现无法ping通的情况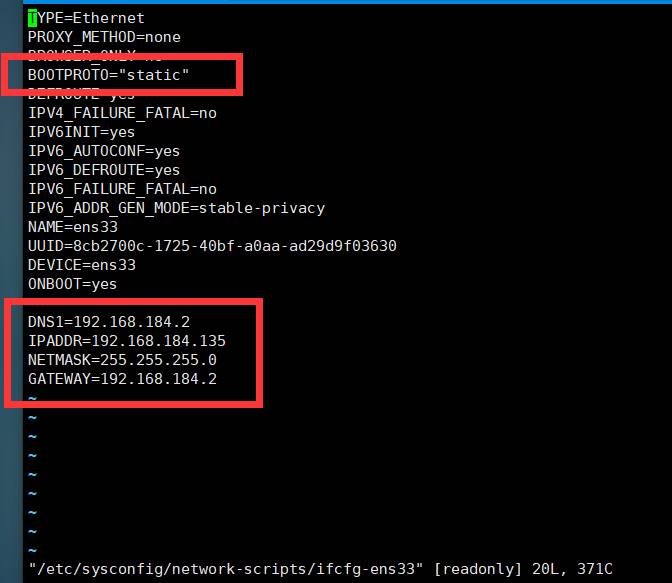
然后点击esc退出编辑模式,在输入:wq进行保存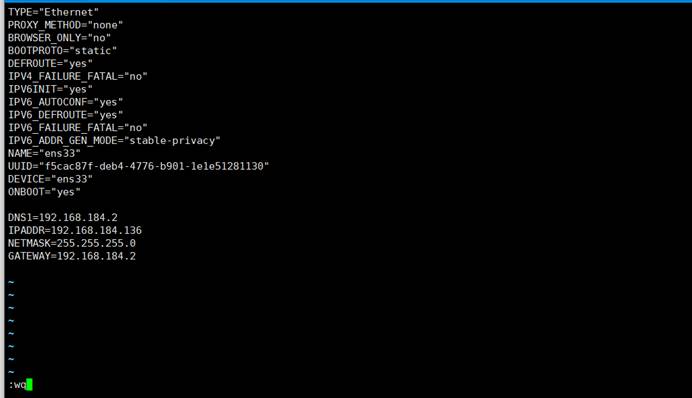
2. 重启网卡
service network restart
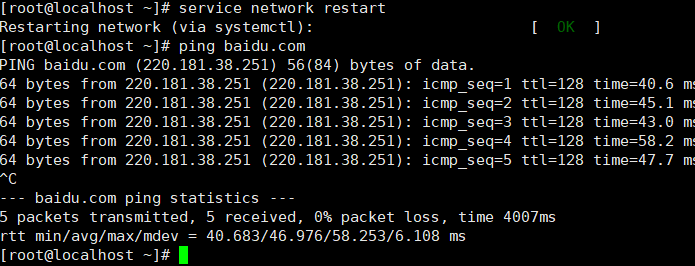
3. ping网络
用ping命令测试网络DNS是否可用,如下图所示,测试可用按ctrl+c停止
ping baidu.com
一、Hadoop完全分布式集群搭建
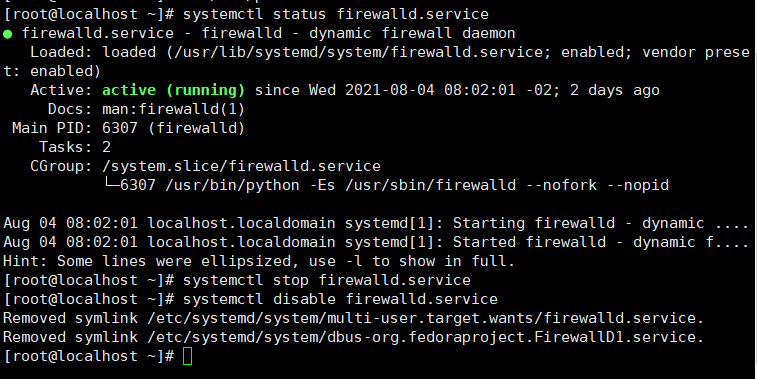
1.永久关闭防火墙
先查看防火墙状态systemctl status firewalld.service
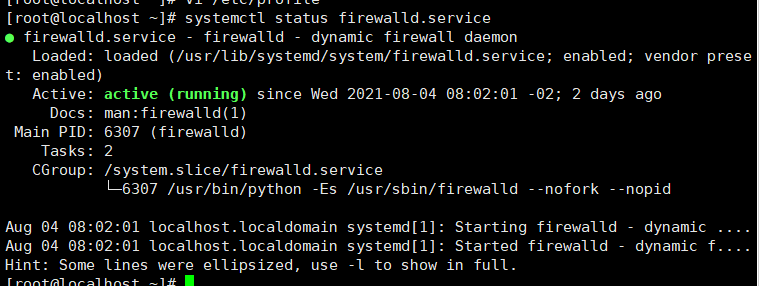
如果还在运行则关闭防火墙systemctl stop firewalld.service
禁用防火墙systemctl disable firewalld.service
2.将hadoop和Jdk上传解压
将tar包放入创建好的文件中进行解压缩
cd /home/hadoop
tar -zxvf hadoop-2.7.3.tar.gz
cd /home/java
tar -zxvf jdk-8u161-linux-x64.tar.gz
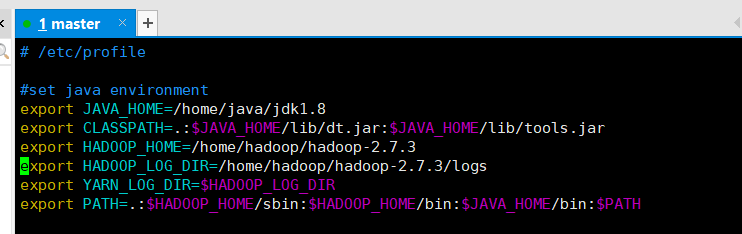
3.配置环境变量
vi /etc/profile或vim /etc/profile
编辑环境变量配置文件,添加或修改环境变量(有些系统可能有jdk工具,不要使用系统安装的openjdk,使用自己的jdk)。
添加jdk和hadoop的环境变量(路径设置为自己存放的目录)
export JAVA_HOME=/home/java/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_LOG_DIR=/home/hadoop/hadoop-2.7.3/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export PATH=.:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH
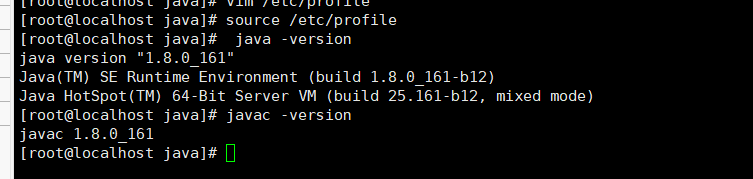
4.验证环境变量
输入 source /etc/profile 更新环境变量
输入 java -version 和 javac -version,看有无版本信息输出
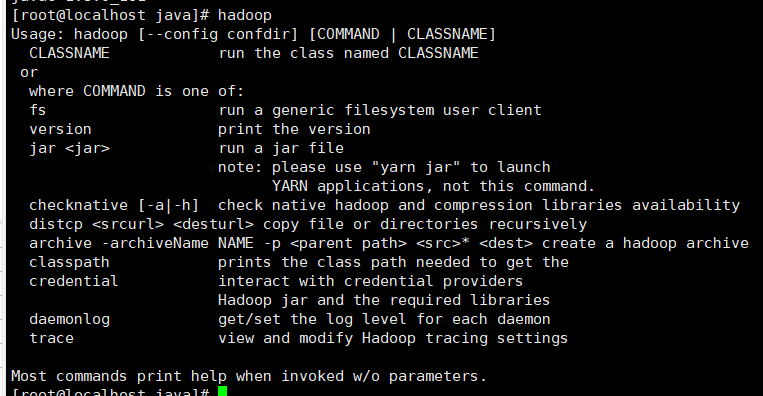
输入hadoop,同样看是否出现提示信息,如果有提示信息输出,则说明配置正确,如果没有仔细检查环境变量
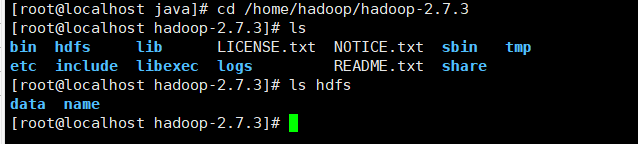
5.创建目录
mkdir /home/hadoop/hadoop-2.7.3/tmp 用来存放临时文件
mkdir /home/hadoop/hadoop-2.7.3/logs 用来存放日志文件
mkdir /home/hadoop/hadoop-2.7.3/hdfs 用来存储集群数据
mkdir /home/hadoop/hadoop-2.7.3/hdfs/name 用来存储文件系统元数据
mkdir /home/hadoop/hadoop-2.7.3/hdfs/data 用来存储真正的数据
6.修改hadoop中两个.sh文件
进入hadoop解压后的目录下,找到两个.sh文件,修改JAVA_HOME的值
cd etc/hadoop
vi hadoop-env.sh或vim hadoop-env.sh
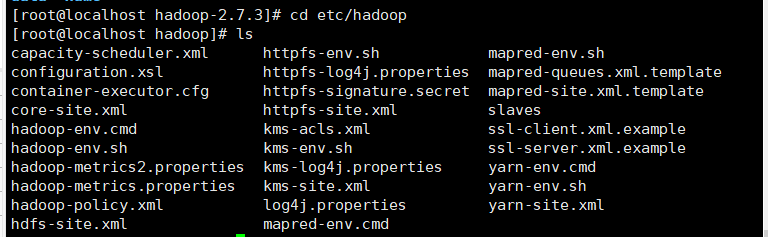
修改JAVA_HOME的值,指向存放Jdk的路径
export JAVA_HOME=/home/java/jdk1.8/

vi yarn-env.sh 或 vim yarn-env.sh
修改JAVA_HOME的路径
export JAVA_HOME=/home/java/jdk1.8/
7. 修改核心配置文件
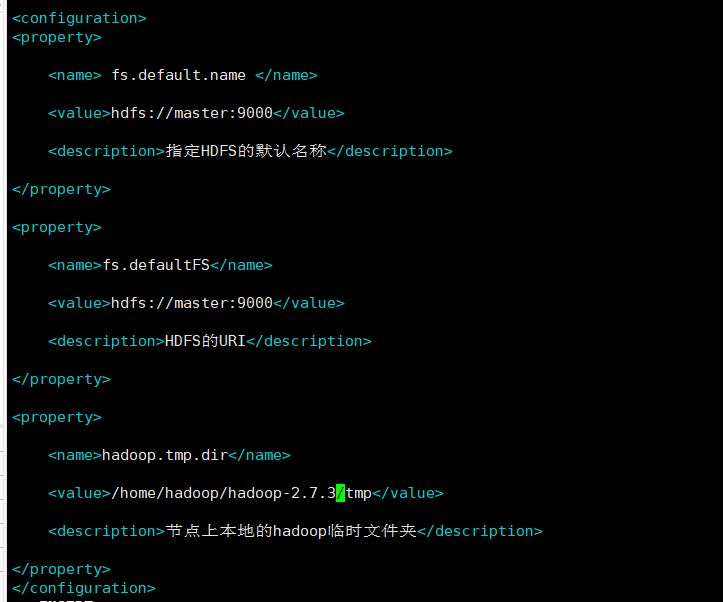
vi core-site.xml 或 vim core-site.xml
在配置标签中添加
<property>
<name> fs.default.name </name>
<value>hdfs://master:9000</value>
<description>指定HDFS的默认名称</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
<description>HDFS的URI</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop2.7.3/tmp</value>
<description>节点上本地的hadoop临时文件夹</description>
</property>
也可以用filezilla下载文件到本地进行修改,然后再上传覆盖即可
vi hdfs-site.xml 或 vim hdfs-site.xml
在配置标签中添加
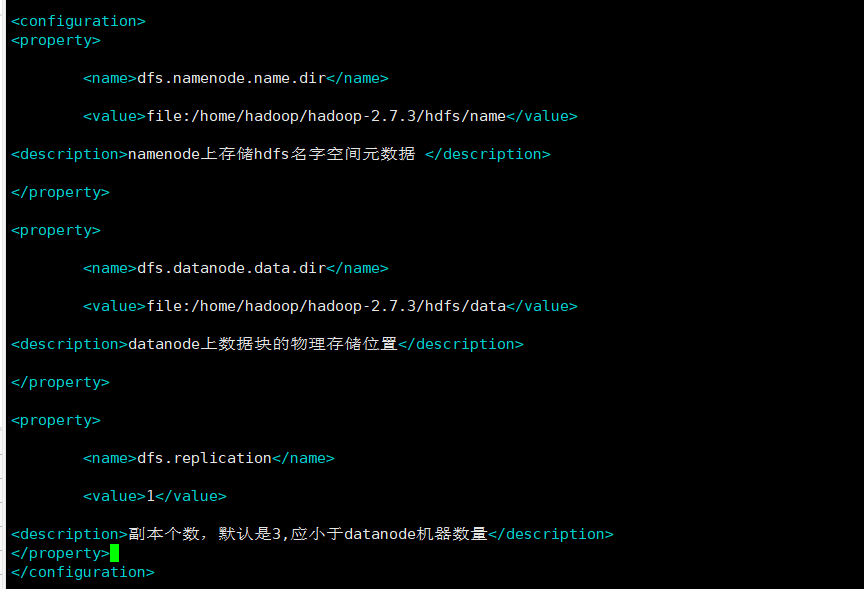
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop-2.7.3/hdfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop-2.7.3/hdfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,默认是3,应小于datanode机器数量</description>
</property>
输入 cp mapred-site.xml.template mapred-site.xml
就可以将mapred-site.xml.template文件复制到当前目录,并重命名为mapred-site.xml
vi mapred-site.xml 或 vim mapred-site.xml
在配置标签中添加
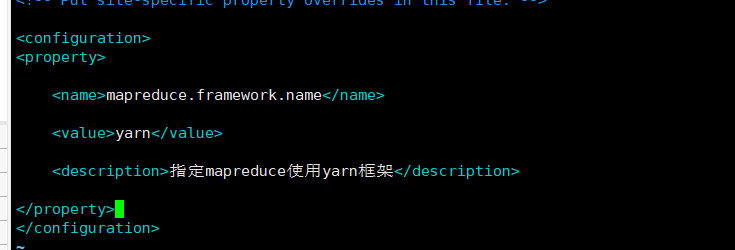
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mapreduce使用yarn框架</description>
</property>
vi yarn-site.xml 或 vim yarn-site.xml
在配置标签中添加
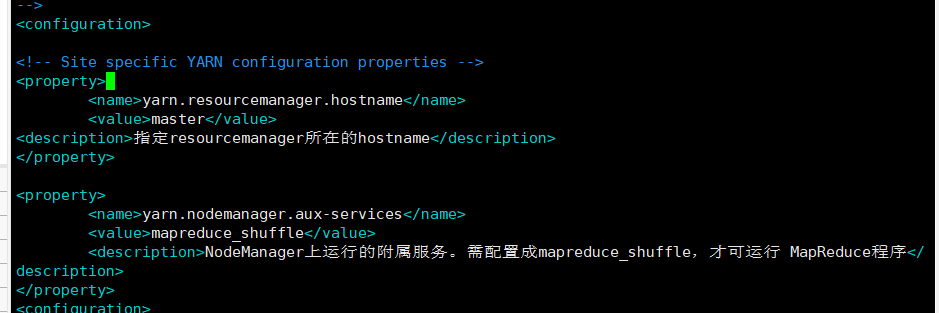
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
<description>指定resourcemanager所在的hostname</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行 MapReduce程序</description>
</property>
vi slaves 或 vim slaves
删除localhost,改为datanode的主机名
node1
node2
node3

8.克隆虚拟机
使用Vmware的克隆功能,完整克隆master
9.修改主机名
vi /etc/hostname 或 vim /etc/hostname
配置每一台主机,把localhost删除,修改为节点对应的名称,master,node1,node2,node3,如master修改为master
10.配置网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33或vim /etc/sysconfig/network-scripts/ifcfg-ens33
这里不同的系统可能网络接口名不同
将每一台主机配置为对应的ip地址,如master修改为192.168.128.135
将BOOTPROTO=dhcp的值改为static,并在最后面加上(后面解释在添加的时候删除):
DNS1=192.168.128.2 --dns地址
IPADDR=192.168.128.135 --需要设置的ip地址
NETMASK=255.255.255.0 --子网掩码
GATEWAY=192.168.128.2 --网关
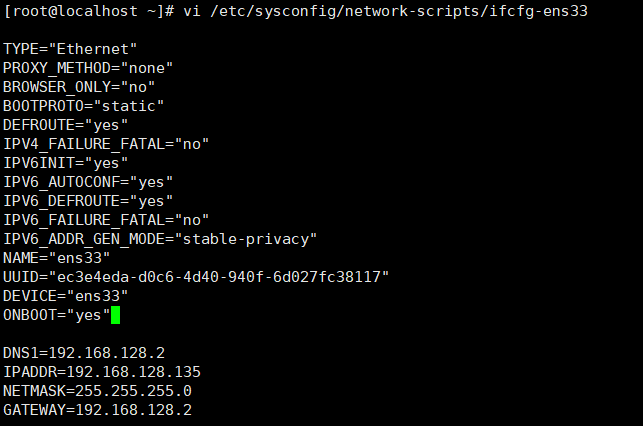
这里注意,因为静态ip地址设置为192.168.128.135,因此默认网关和DNS地址前面部分,即192.168.128须相同,不然会出现无法ping通的情况
重启网络服务service network restart,查看修改是否成功
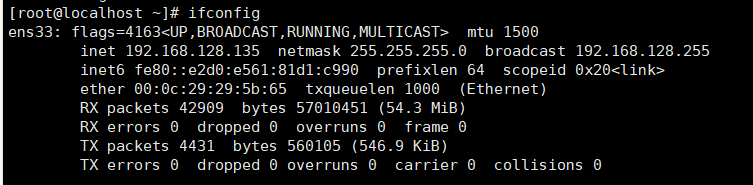
11.修改每一台主机的/etc/hosts文件
vi /etc/hosts 或 vim /etc/hosts
添加
192.168.128.135 master
192.168.128.136 node1
192.168.128.137 node2
192.168.128.138 node3
后期测试用到了如下(电脑问题一修改固定ip就会一直崩溃重启,没有去解决,如果没有修改ip,后面ip变动了,凡是涉及到IP的地方都需要去改):
192.168.95.128 master
192.168.95.130 node1
192.168.95.131 node2
192.168.95.129 node3
注意要与自己虚拟机实际Ip和主机名对应
12.配置ssh免密登录
原理:通过创建无密码公钥的方式,将公钥传给对方。使用ssh协议连接时,会寻找authorized_keys文件中存放的公钥,如果有目标主机的公钥则将公钥传给目标主机,目标主机用自己的私钥和公钥进行匹配,正确匹配之后则认为两者可信,即不需要密码就可以登录
实现节点之间免密服务原理:
通过把所有节点的公钥写入authorized_keys文件中,再把这个文件传输给每一台节点,此时所有节点都有了其他节点的公钥,则登录时就不需要输入密码
在每台主机上输入 ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa 创建一个无密码的公钥,-t是类型的意思,dsa是生成的密钥类型,-P是密码,’’表示无密码,-f后是秘钥生成后保存的位置
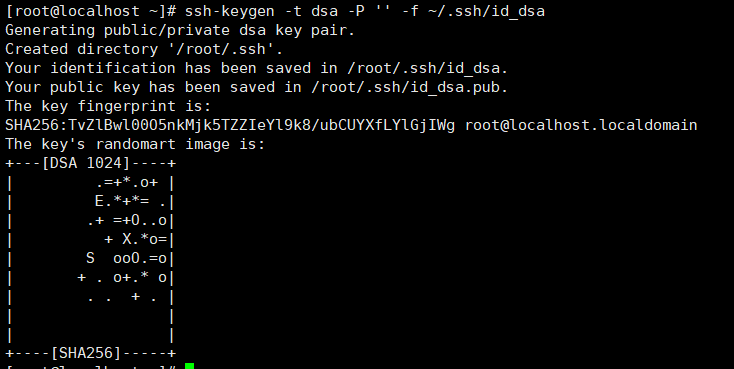
创建完成后,会出现两个文件
id_dsa 存放私钥
id_dsa.pub 存放公钥
主节点输入 cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 将公钥id_dsa.pub添加进authorized_keys
执行后会创建authorized_keys文件,这个文件用来放其他节点的公钥。
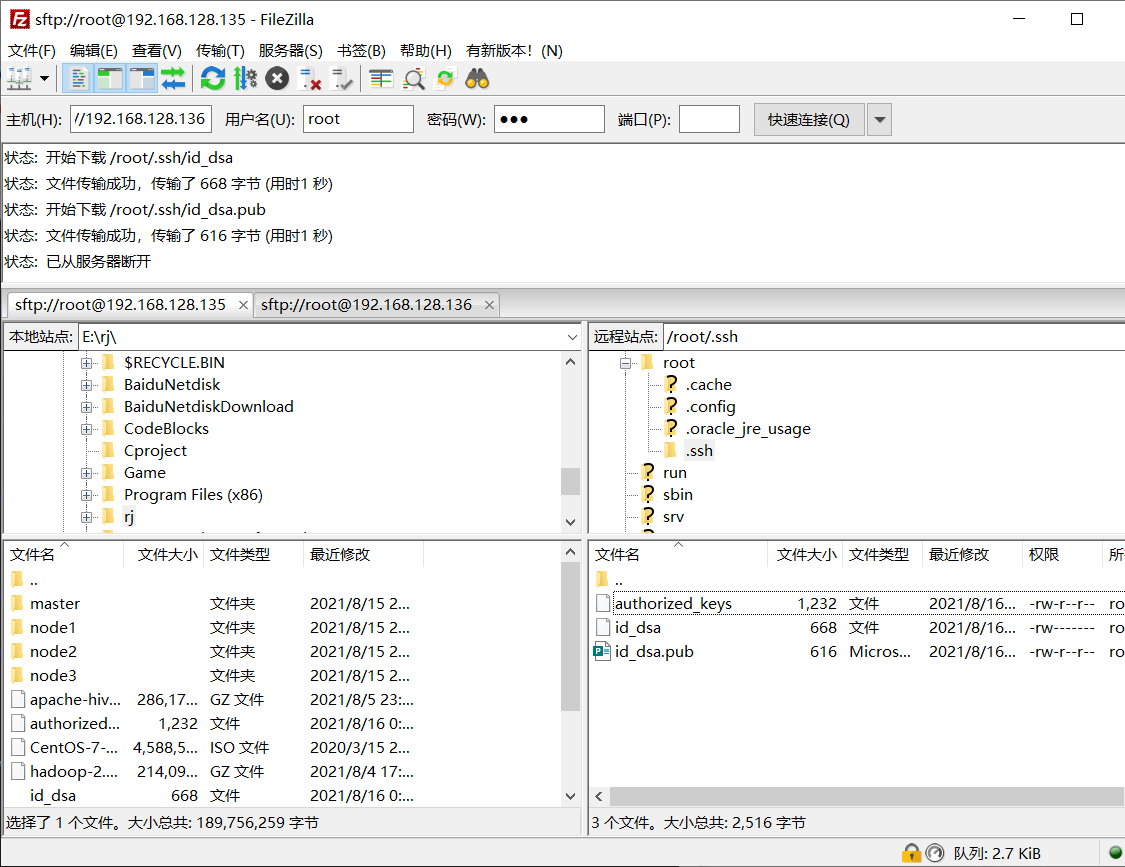
在非master节点上输入 ssh-copy-id -i ~/.ssh/id_dsa.pub master 将自己的公钥传输给master节点,如果出现输入yes/no的情况,输入yes,之后输入主节点的密码:123
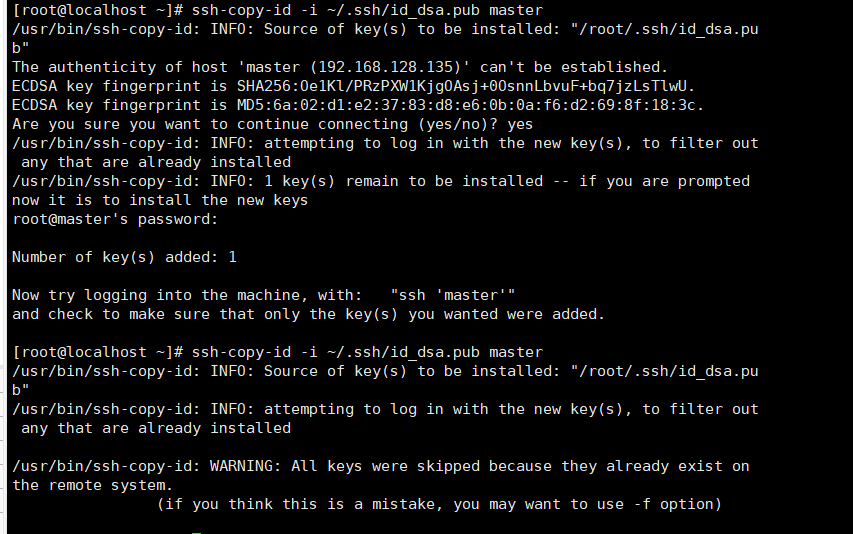
这时,master节点拥有所有节点的公钥。
在master中输入
scp -r /用户家目录/.ssh/authorized_keys 用户@主机名:/对应用户的家目录/.ssh/
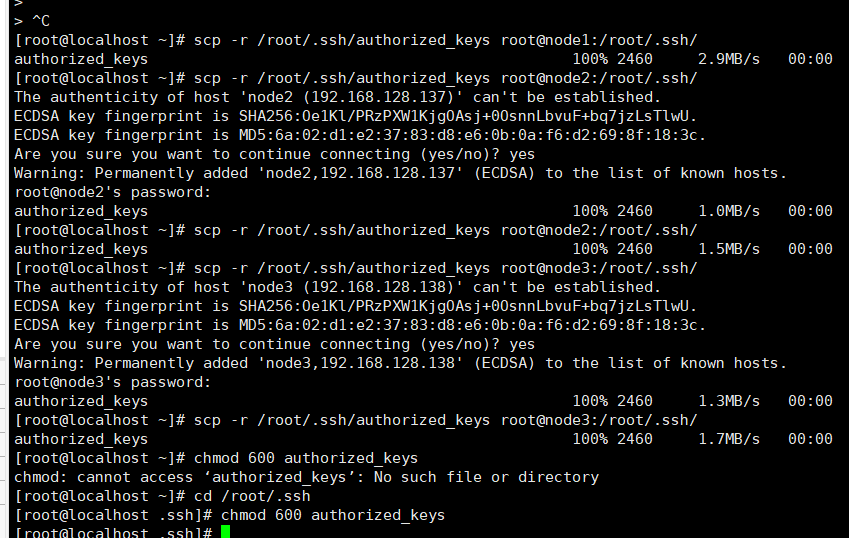
scp -r /root/.ssh/authorized_keys root@node1:/root/.ssh/
scp -r /root/.ssh/authorized_keys root@node2:/root/.ssh/
scp -r /root/.ssh/authorized_keys root@node3:/root/.ssh/
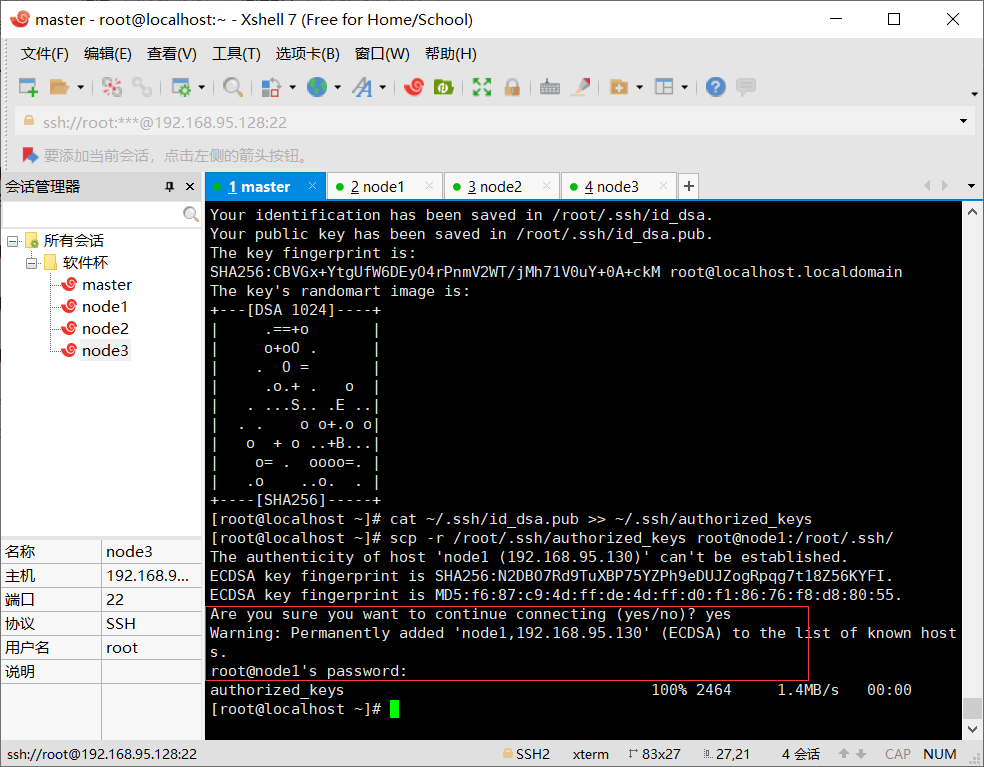
连接每个节点的时候需要输入所连接的节点密码,我这里都是123。
进入到密钥文件夹中:cd /root/.ssh
在每一台主机上输入 chmod 600 authorized_keys 修改文件权限(需要进入文件夹内在修改权限)
重启服务 service sshd restart
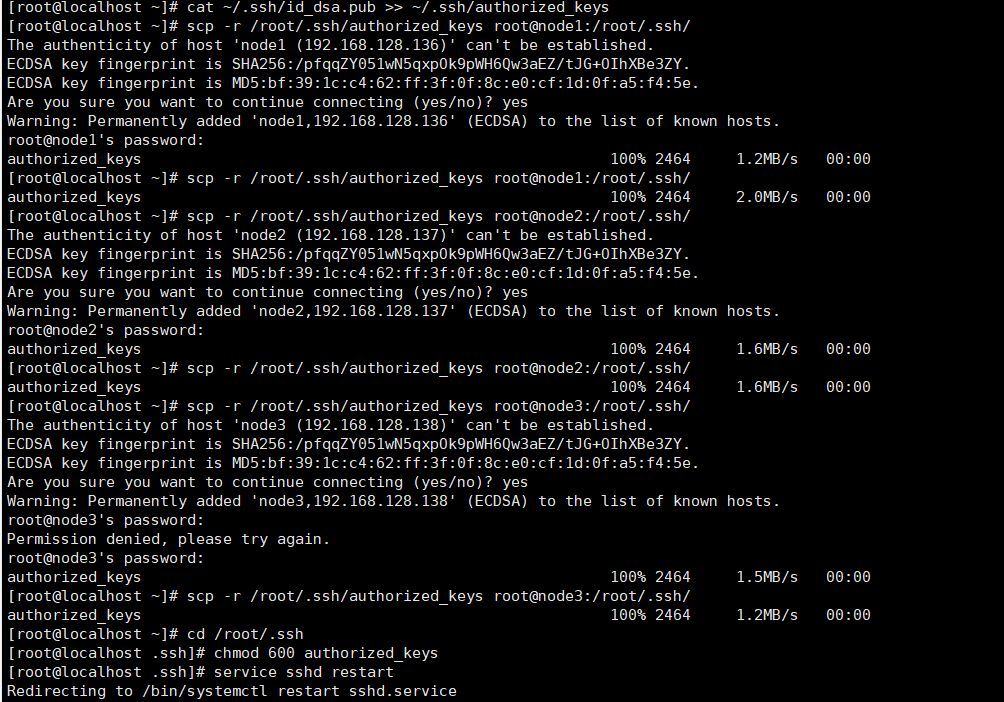
此时每个节点都保存了所有的公钥,节点之间也就可以ssh免密登录了(第一次仍然需要密码,输入密码:123前可能需要输入输入yes)第二次就不需要了,可以进行重复测试

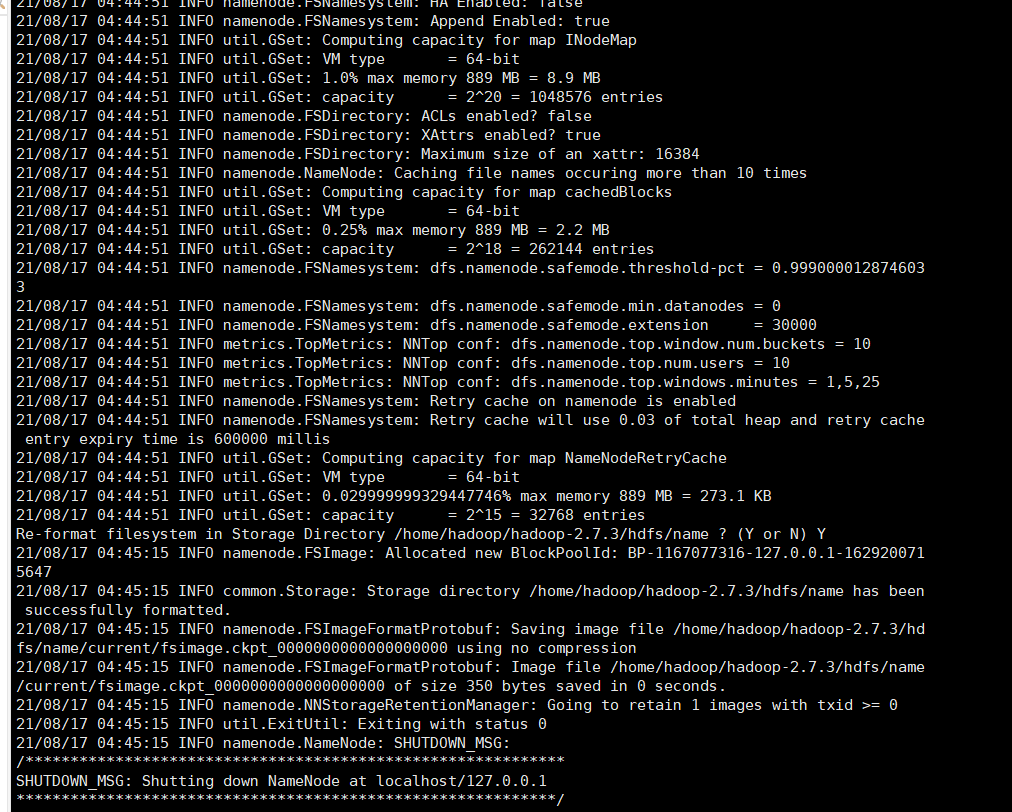
13.格式化hdfs
在master机器上输入hdfs namenode -format 格式化namenode,第一次使用需格式化一次,之后就不需要再重复格式化,如果修改了一些配置文件,则需要重新格式化(配置了环境变量任意位置执行都可以)

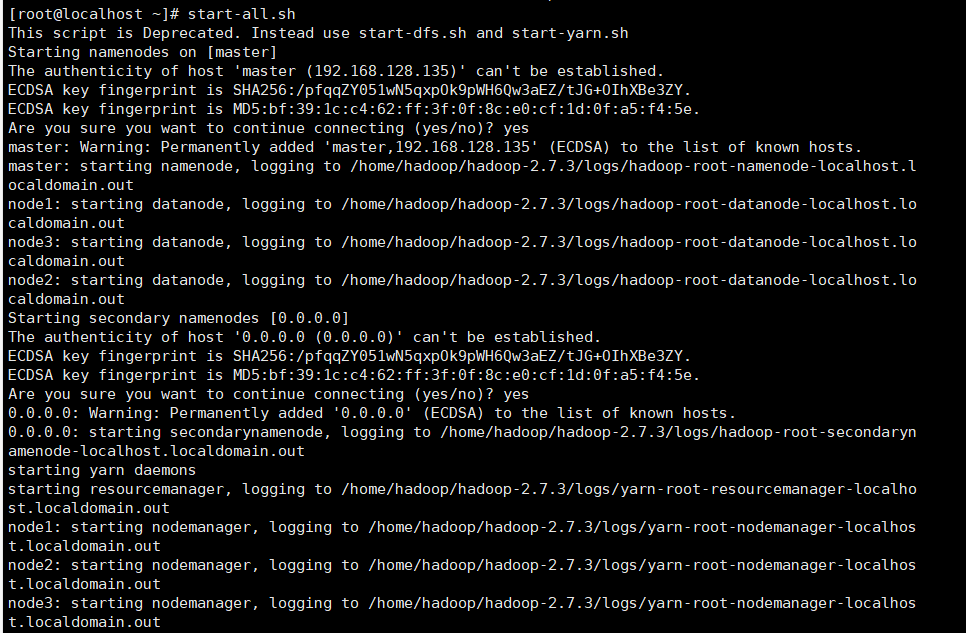
14.启动hadoop
如果没有配置环境变量则进入hadoop下的sbin目录,这里我们已经配置好了,直接输入 start-all.sh(start-dfs.sh也可以,不过是单一启动,为了我们能够很好的处理,启动集群的全部)即可,输入yes即可启动
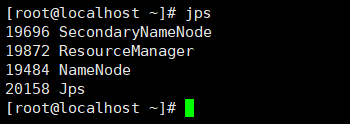
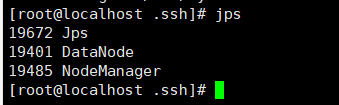
15.使用jps查看每个节点的进程
master节点有4个进程
NameNode
SecondaryNameNode
ResourceManager
Jps
其他节点(slave)有3个进程
DataNode
NodeManager
Jps
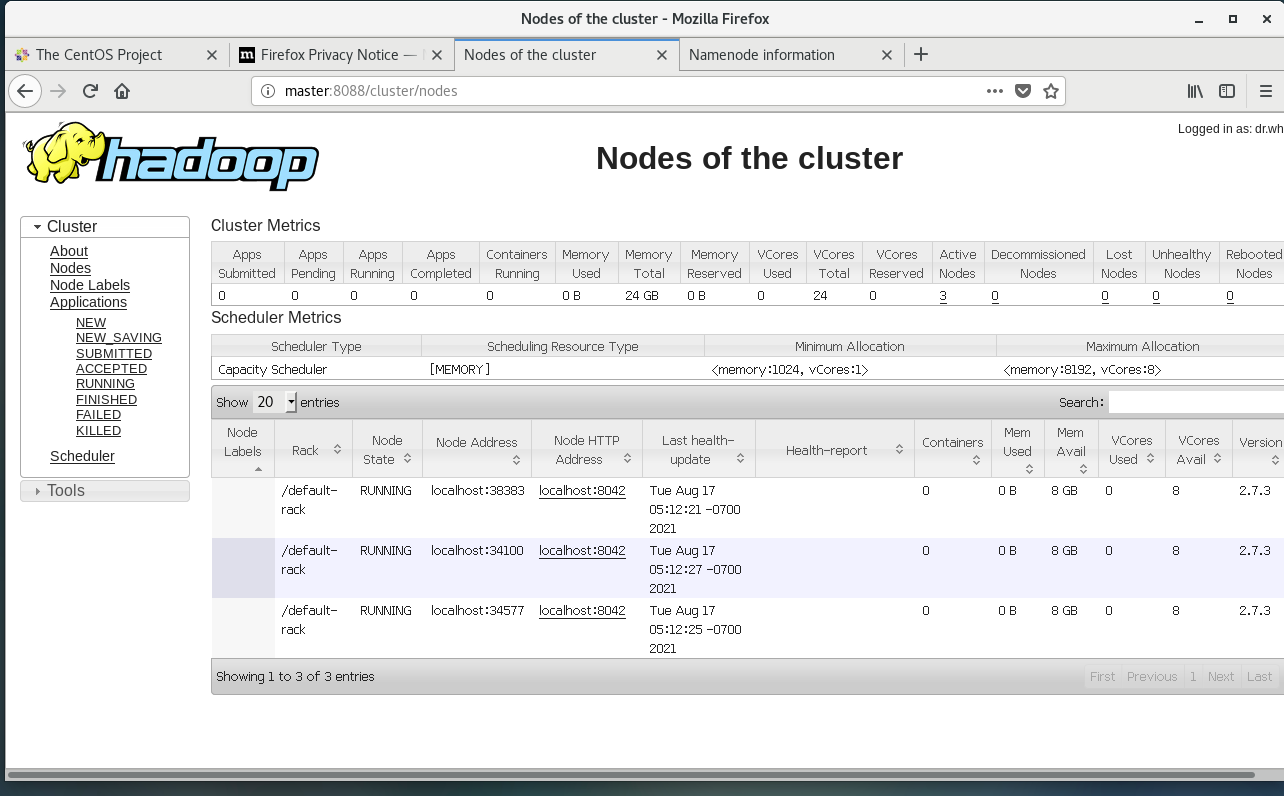
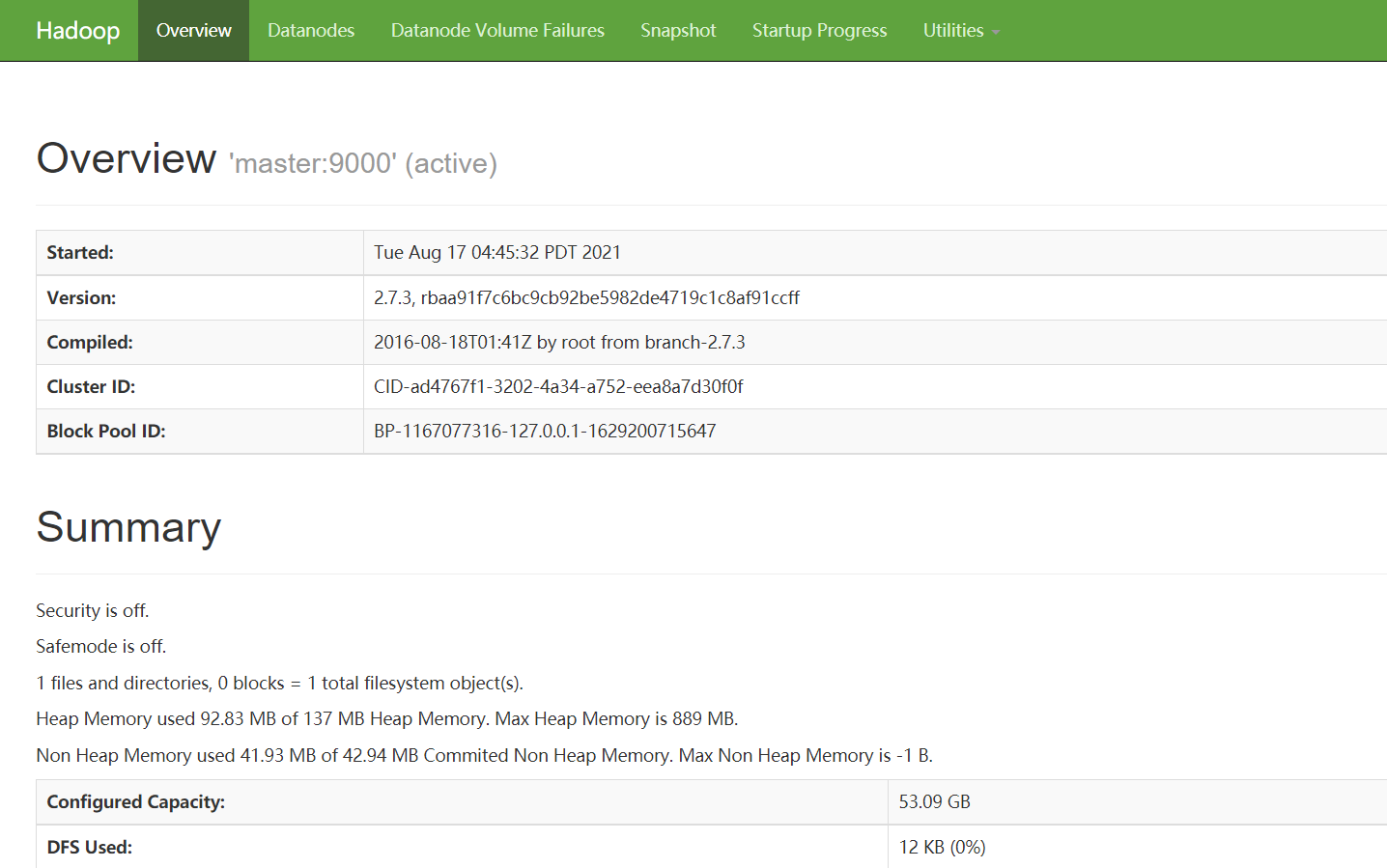
16.用虚拟机web查看节点信息或本地web查看
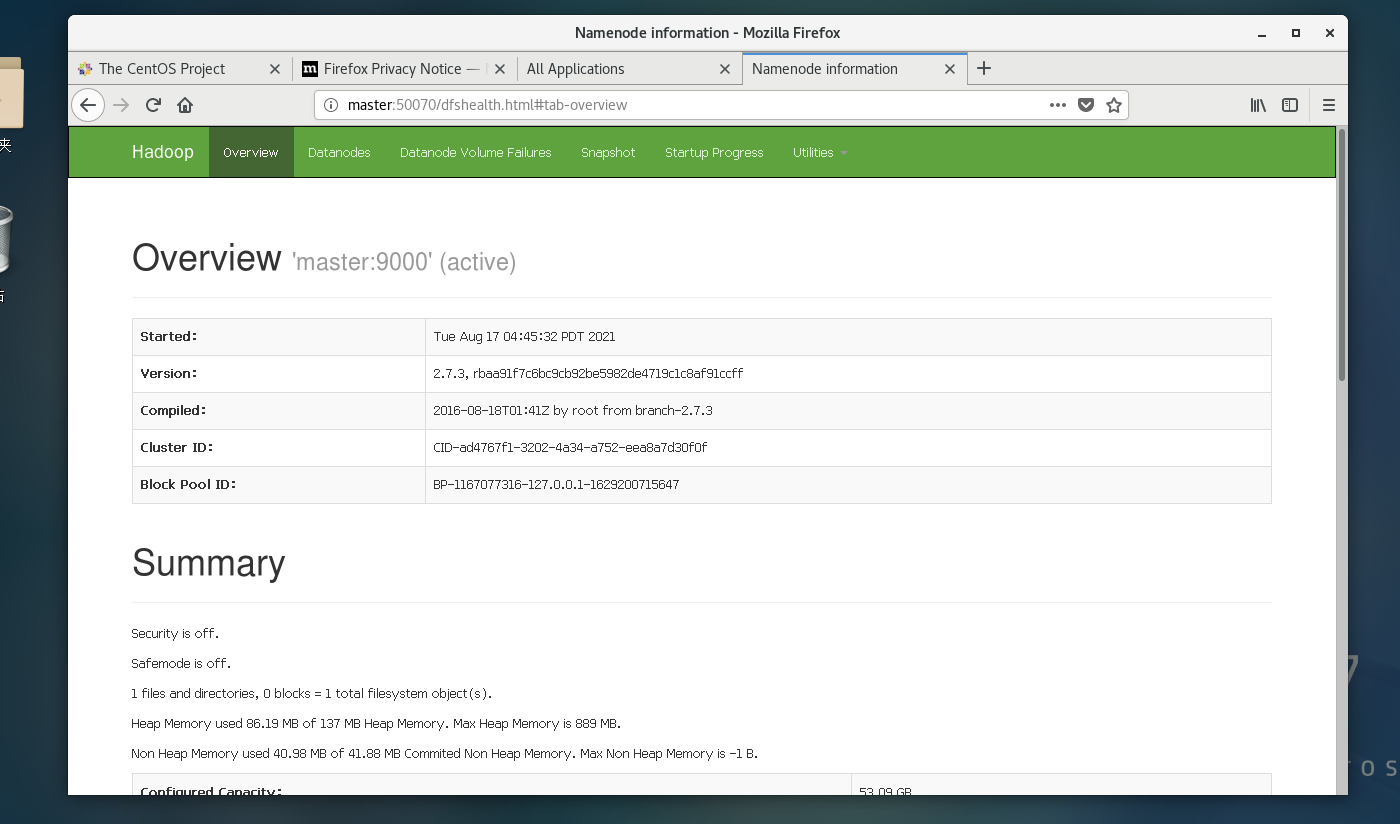
在虚拟机浏览器打开master:8088或master:50070
打开后显示节点的信息并都正常运行,即搭建成功
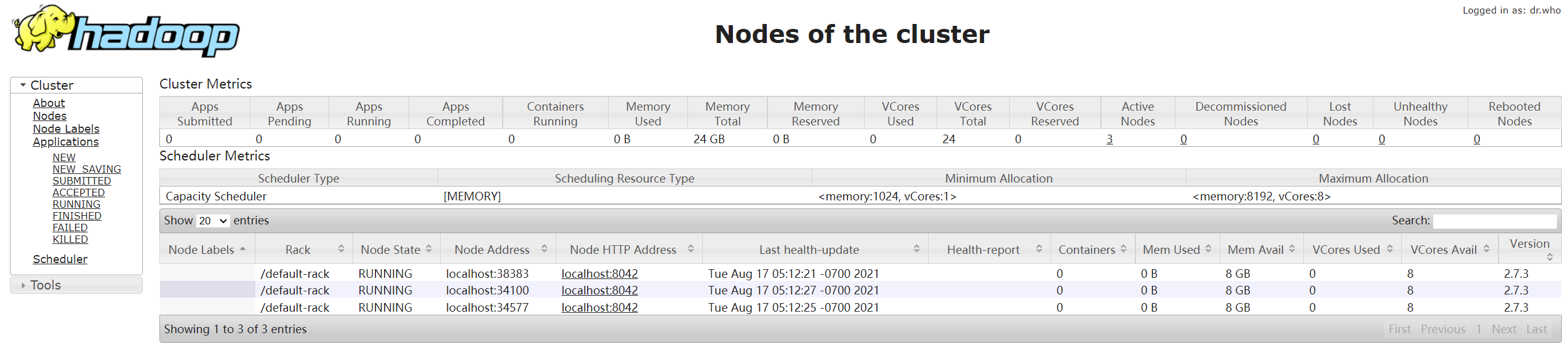
在本地浏览器打开192.168.128.135:8088/或192.168.128.135:50070/
打开后显示节点的信息并都正常运行,即搭建成功
17.关闭集群
输入stop-all.sh即可关闭
二、MySQL安装
1.安装mysql
查看本地是否自带数据,并卸载自带的数据库
rpm -qa |grep mysql
rpm -qa|grep mariadb
rpm -e --nodeps mariadb-libs-5.5.60-1.el7_5.x86_64

2.安装yum源
先进入我们上传文件的位置,然后安装yum源,安装过程Is this ok [y/d/N]: 时,填y
cd /home/
yum localinstall mysql80-community-release-el7-3.noarch.rpm

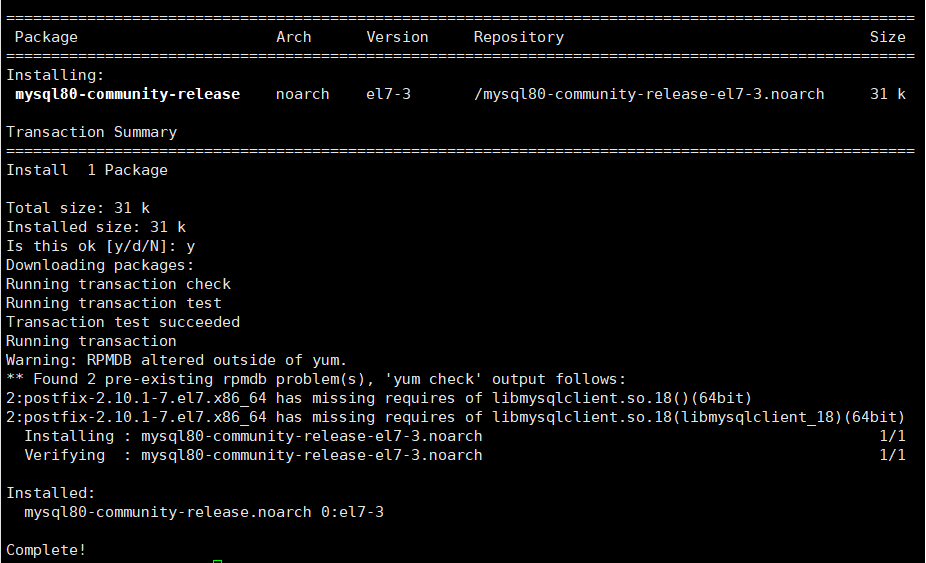
安装完成后可以用指令进行查看是否有相关文件
yum repolist enabled | grep "mysql.*-community.*"

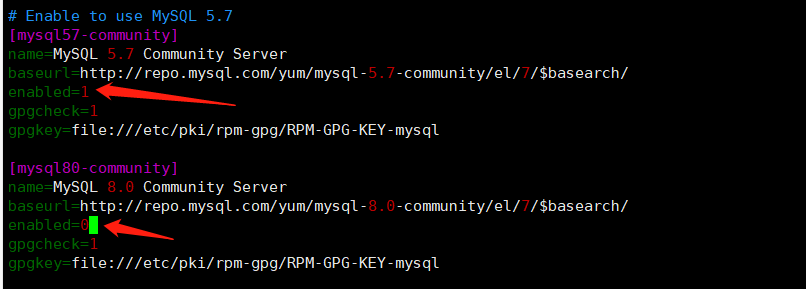
3.设置mysql版本
设置要安装的版本,这里我们使用5.7,而默认的版本时8.0
所以我们需要编辑文件进行更改
vim /etc/yum.repos.d/mysql-community.repo
修改mysql版本的enabled和gpgcheck的值,将想要下载的版本的enabled改为1,将默认版本的enabled改为0
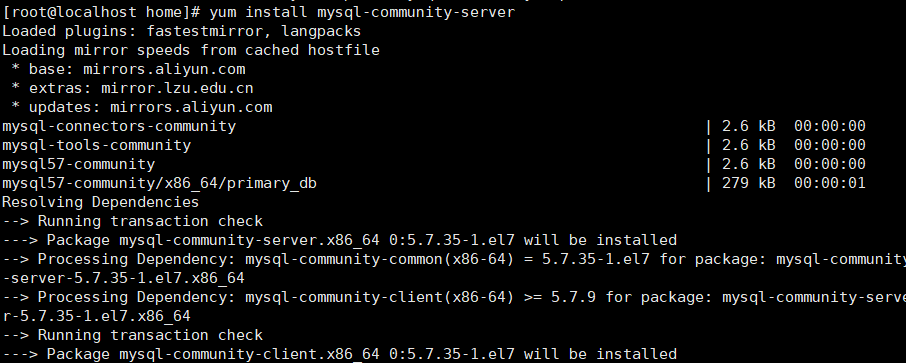
4.安装mysql
yum install mysql-community-server
安装过程中一路y即可

5.启动服务
开启服务
service mysqld start 或 systemctl start mysqld
查看服务状态
service mysqld status 或 systemctl status mysqld
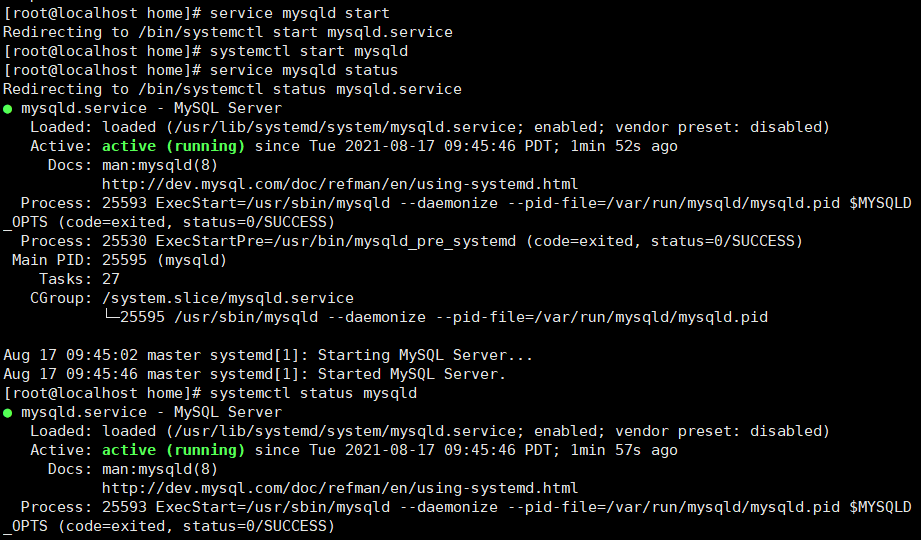
设置自启动(可选)
systemctl enable mysqld
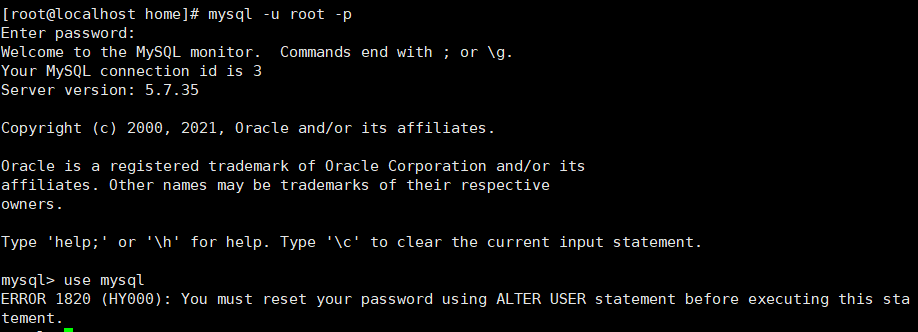
6.修改密码
刚安装完成的mysql密码是随机的,无法直接登录,需要通过查看日志文件找到默认密码或者是修改配置文件后修改密码之后才可以登录
方法一:查找日志文件,找到默认密码
登录mysql
mysql -u root -p
此时随意输入密码,提示错误后查找日志
grep 'temporary password' /var/log/mysqld.log

可以看到localhost后(2yaukrrwHp?i)即为随机密码,登录时用此密码即可登录
(需要注意的是,即使可以登录了还是需要修改一次密码,详细看下文修改密码安全策略)
方法二:修改配置文件,修改密码
编辑文件:vi /etc/my.cnf或vim /etc/my.cnf
在末尾添加:
skip-grant-tables

进入mysql
mysql -u root -p
use mysql
修改密码为root
update mysql.user set authentication_string=password('root') where user='root';
退出:exit
进入配置文件中将之前添加的skip-grant-tables注释或者删除
重启服务
service mysqld restart
两种都可以,这里我们选择第一种方式!!!
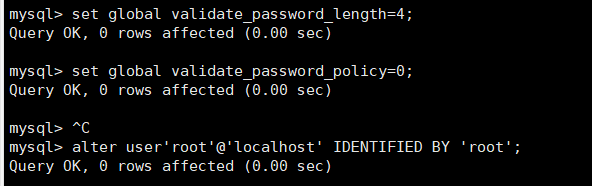
7.修改musql的密码安全策略
第一次安装完成后,即使修改了密码用root登录后还是会提示需要修改密码,此时需要按照标准进行修改,修改完成后修改配置参数,再重新还原。
登录后选择数据库时会提示需要修改密码
设置参数
set global validate_password_policy=0; //设置等级为0,即不限制大小写字符和特殊字符等
set global validate_password_length=4; //设置密码长度,最短为3
修改密码
alter user'root'@'localhost' IDENTIFIED BY 'root';
8.设置root远程连接数据库
登录选择数据库后,输入
grant all privileges on *.* to 'root'@'%' identified by 'root';
grant all privileges 表示赋于所有权限
on *.* 表示mysql中的所有数据对象
to ‘root’@’%’ 表示给root赋权,%允许root从任意ip连接
identified by ‘root’ 表示root从远程登录时使用的密码
从本机登录时还可以使用之前的密码
flush privileges; 刷新权限
如果出现提示密码不够安全的情况请按照步骤7设置安全策略

9.mysql修改字符集
查看当前字符集设置
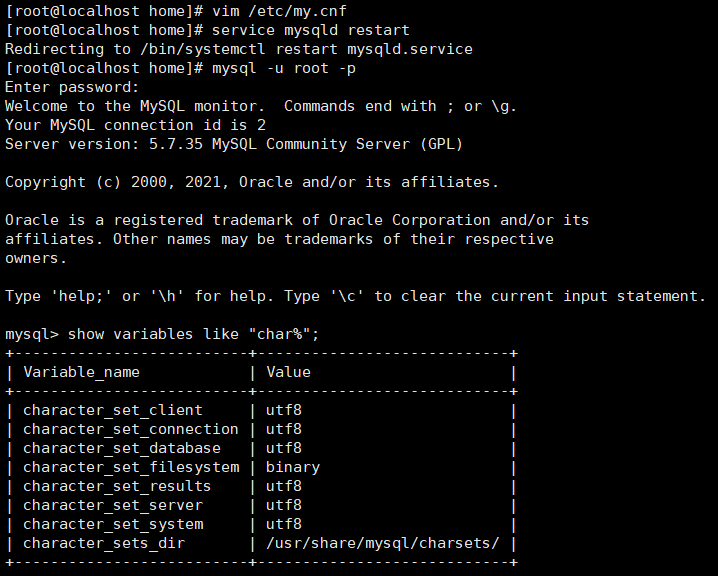
show variables like "char%";
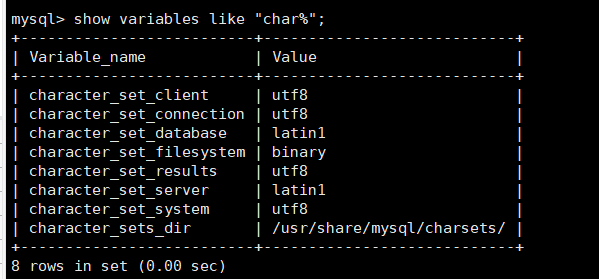
编辑配置文件:vi /etc/my.cnf 或 vim /etc/my.cnf,
添加: character_set_server=utf8
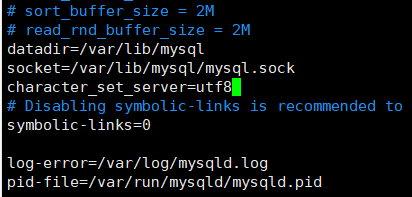
重启服务器之后重新登录查看发现全部变成了utf8
service mysqld restart
三、hive安装
1.解压缩hive并重命名文件夹
首先用上传工具将tar包上传到hadoop文件夹中
cd /home/hadoop
tar -zxvf apache-hive-2.3.9-bin.tar.gz
mv apache-hive-2.3.9-bin hive-2.3.9或者直接用上传工具进行更改
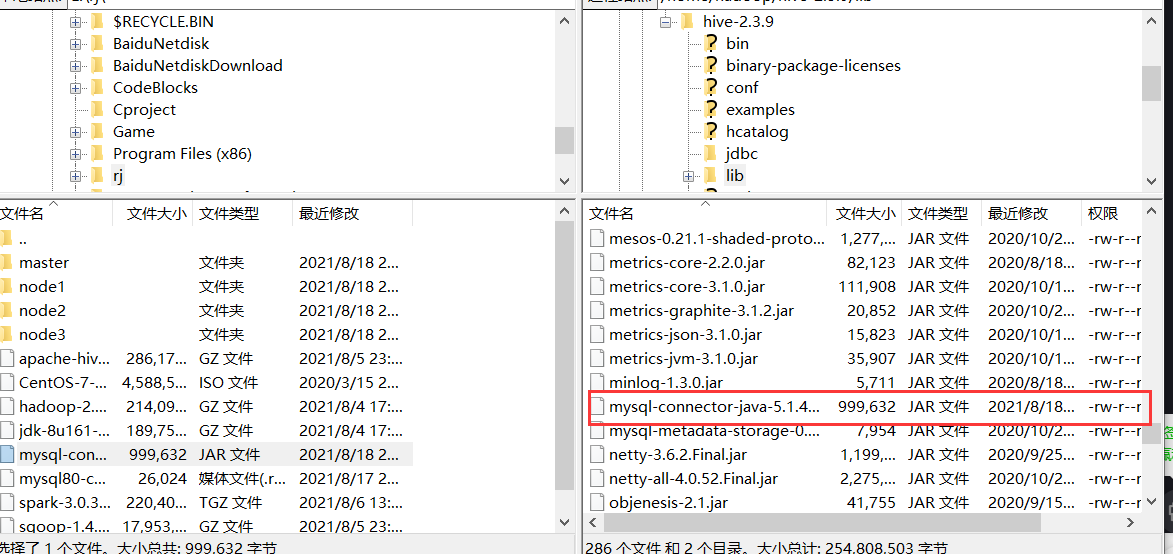
2.上传mysql-connector-java-5.1.44.jar
用上传工具将mysql-connector-java-5.1.44.jar文件上传至hive-2.3.9/lib/文件夹下
3.配置环境变量
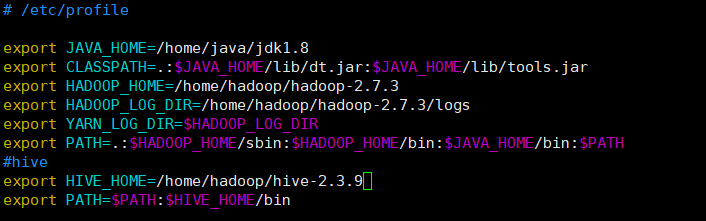
vi /etc/profile 或 vim /etc/profile
添加:
export HIVE_HOME=/home/hadoop/hive-2.3.9
export PATH=$PATH:$HIVE_HOME/bin
更新环境变量
source /etc/profile
4.进入conf配置文件中,将文件重命名
mv hive-env.sh.template hive-env.sh
mv hive-default.xml.template hive-default.xml
mv hive-log4j2.properties.template hive-log4j2.properties
mv hive-exec-log4j2.properties.template hive-exec-log4j2.properties
cp hive-default.xml hive-site.xml
5.启动hadoop集群,创建文件
启动集群:start-all.sh
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user
6.创建本地目录
mkdir -p /home/hadoop/hive-2.3.9/tmp
chmod -R 777 /home/hadoop/hive-2.3.9/tmp
7.修改hive-site.xml文件
vim hive-site.xml 或用上传工具下载到本地进行更改
这里我们选择下载到本地进行修改较为方便,然后修改完毕后上传覆盖即可
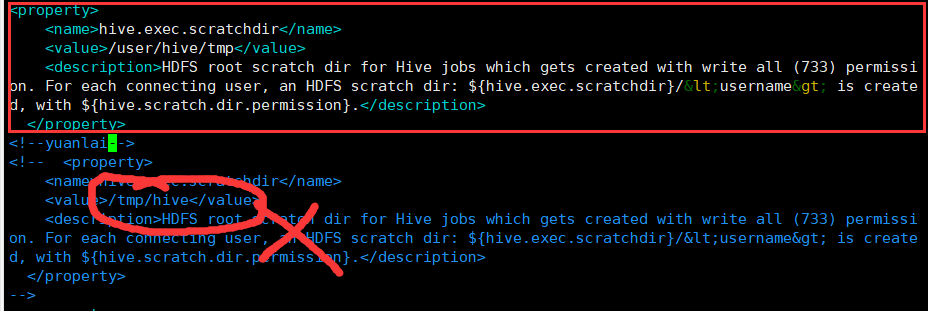
修改hive.exec.scratchdir一项
<property>
<name>hive.exec.scratchdir</name>
<value>/user/hive/tmp</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<username> is created, with ${hive.scratch.dir.permission}.</description>
</property>
修改 hive.metastore.warehouse.dir
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>

修改hive.querylog.location
<property>
<name>hive.querylog.location</name>
<value>/user/hive/log</value>
<description>Location of Hive run time structured log file</description>
</property>

修改javax.jdo.option.ConnectionURL
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>

修改javax.jdo.option.ConnectionDriverName
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>

修改javax.jdo.option.ConnectionUserName
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>

修改javax.jdo.option.ConnectionPassword
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>

修改hive.exec.local.scratchdir
将文件中的${system:java.io.tmpdir}替换为 /home/hadoop/hive-2.3.9/tmp (对应自己创建的tmp目录位置)
{system:user.name} 改成 {user.name}
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/hive-2.3.9/tmp/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>

修改hive.downloaded.resources.dir
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/hive-2.3.9/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>

修改hive.server2.logging.operation.log.location
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/home/hadoop/hive-2.3.9/tmp/${user.name}/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>

修改完毕之后,用上传工具将文件上传至原文件夹中覆盖即可
8.初始化hive
cd /home/hadoop/hive-2.3.9/lib
schematool -dbType mysql -initSchema
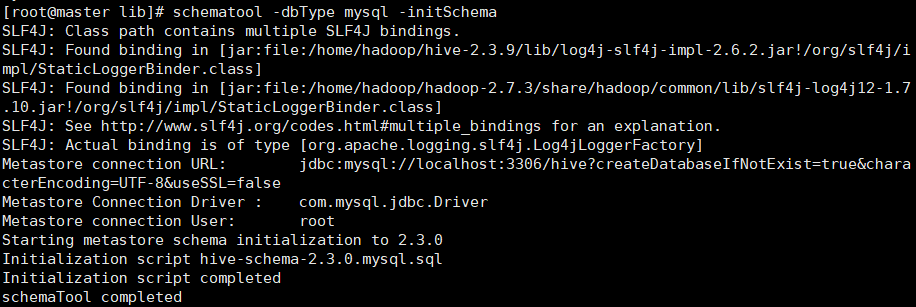
我们这里出现了jar包重复,进入到hive文件夹里的lib根据提示删除log4j-slf4j-impl-2.6.2.jar即可,可用上传工具直接删除,然后进入到mysql中删除hive表,之后退出:exit,再重新进行初始化hive 即可
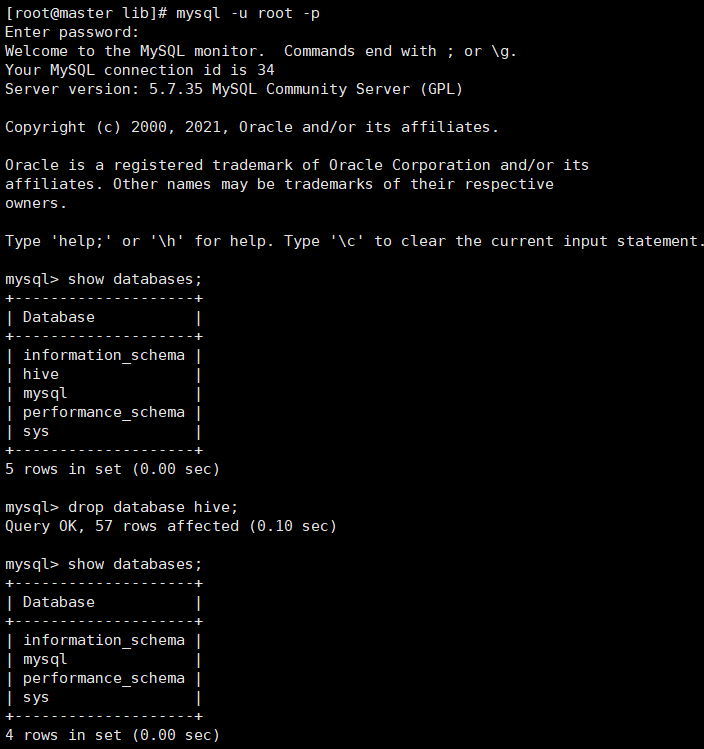
出现下图即可

9.进入hive
直接输入hive即可
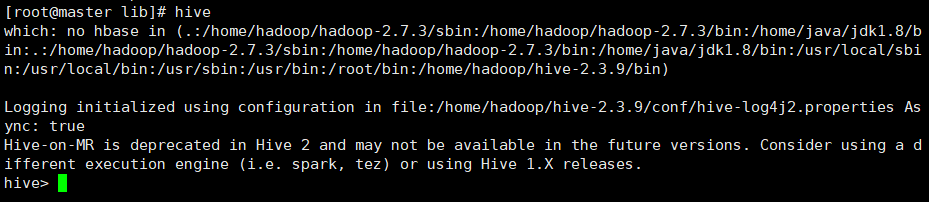
查看数据库
show databases
查看表
show tables
退出hive
exit;
四、sqoop安装
1.上传并解压
将文件上传到hadoop文件夹下
cd /home/Hadoop
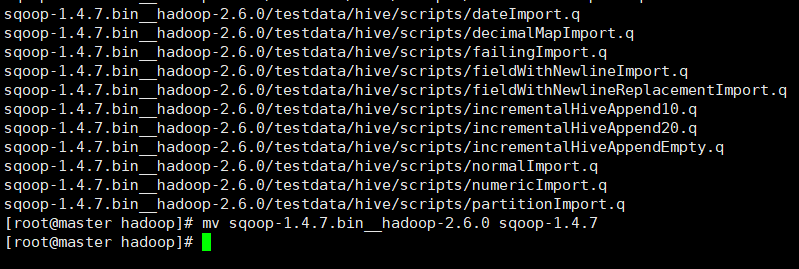
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
重命名方便使用
mv sqoop-1.4.7.bin__hadoop-2.6.0 sqoop-1.4.7
2.配置环境变量
vi /etc/profile 或 vim /etc/profile
添加
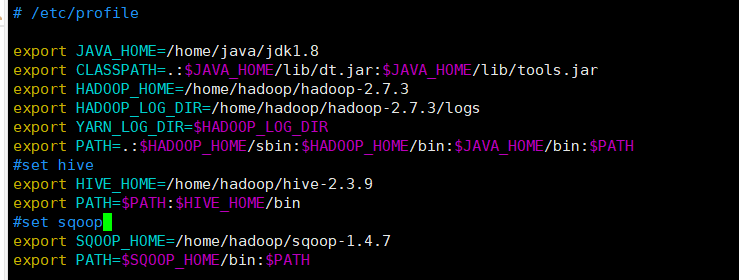
#set sqoop
export SQOOP_HOME=/home/hadoop/sqoop-1.4.7
export PATH=$SQOOP_HOME/bin:$PATH
3.修改配置文件
进入目录sqoop-1.4.7/conf下
cd /home/hadoop/sqoop-1.4.7/conf
复制一份配置文件并重命名
cp sqoop-env-template.sh sqoop-env.sh
编辑文件: vim sqoop-env.sh
修改路径(根据实际情况修改,暂时不用的可以不配置。例如我安装sqoop机器上没有hbase、zookeeper,则不配置)
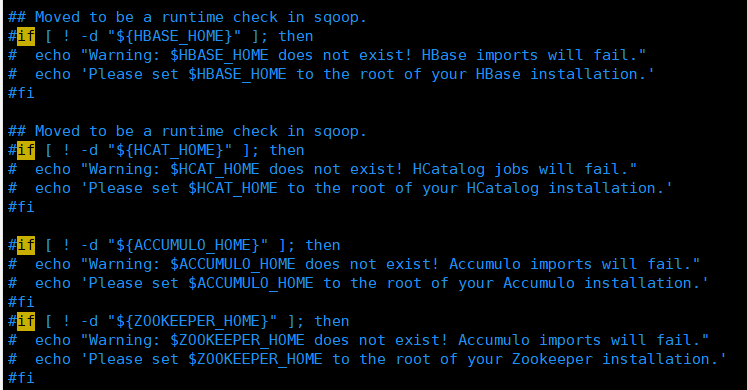
进入目录sqoop-1.4.7/bin下,编辑文件vim configure-sqoop注释以下代码(根据实际情况注释,不用的可以注释掉,否则会输出很多提示信息)
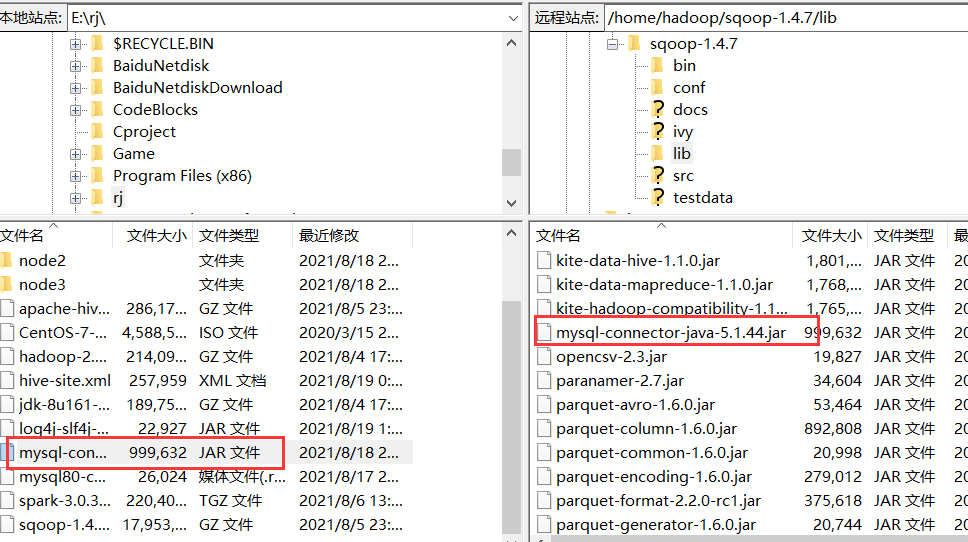
4.将jdbc驱动包放上传到sqoop的lib中(连接Mysql时使用)
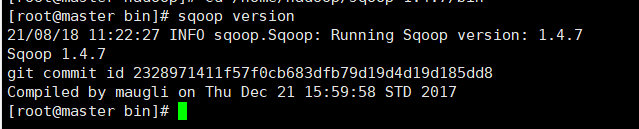
5.查看版本验证安装
sqoop version
如果出现了版本信息则说明安装成功
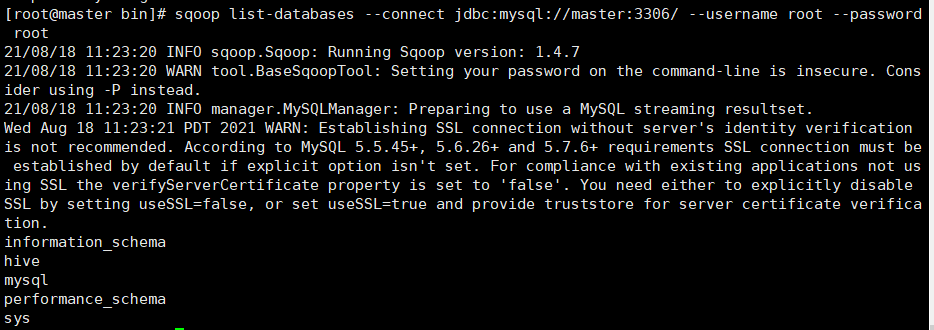
6.测试连接mysql,查看数据库
sqoop list-databases --connect jdbc:mysql://master:3306/ --username root --password root
五、spark安装
1.上传并解压
利用上传工具上传至指定文件夹中/home/Hadoop
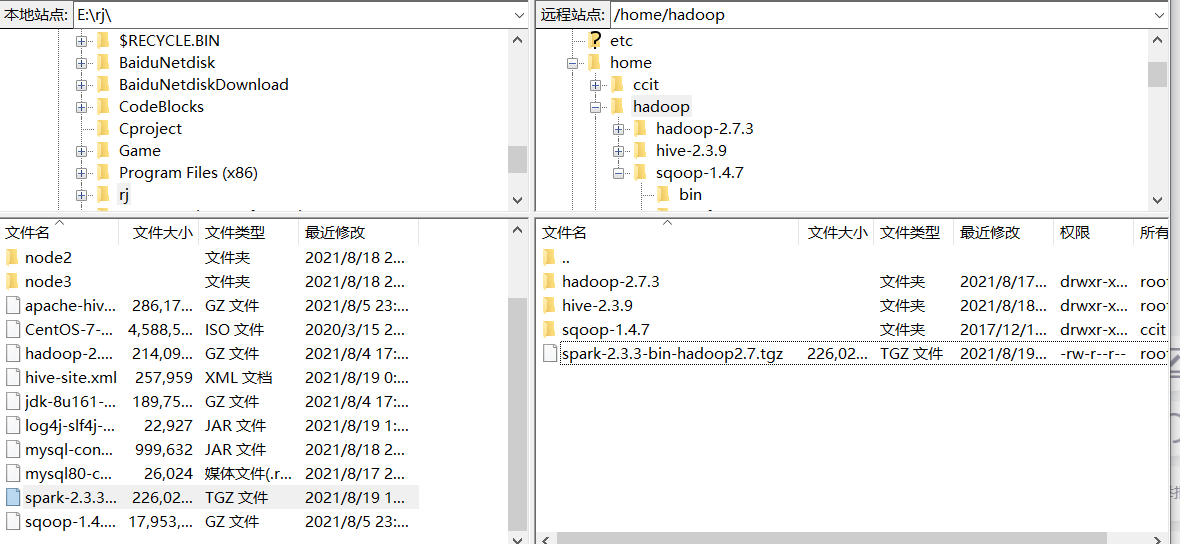
tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz
mv spark-2.3.3-bin-hadoop2.7 spark-2.3.3
2.配置环境变量
vim /etc/profile

更新环境变量 source /etc/profile
3.修改配置文件
复制配置文件模板并重命名
cd /home/hadoop/spark-2.3.3/conf
cp spark-env.sh.template spark-env.sh
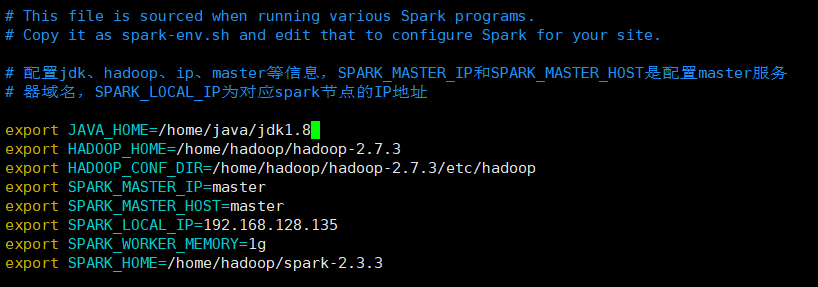
配置spark-env.sh
vim spark-env.sh
添加:
# 配置jdk、hadoop、ip、master等信息,SPARK_MASTER_IP和SPARK_MASTER_HOST是配置master服务
# 器域名,SPARK_LOCAL_IP为对应spark节点的IP地址
export JAVA_HOME=/home/java/jdk1.8
export HADOOP_HOME=/home/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.3/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_HOST=master
export SPARK_LOCAL_IP=192.168.159.101
export SPARK_WORKER_MEMORY=1g
export SPARK_HOME=/home/hadoop/spark-2.3.3
vim slaves 或vi slaves
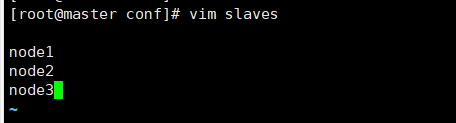
4.发送给其他节点
scp -r /home/hadoop/spark-2.3.3 root@node1:/home/hadoop/
scp -r /home/hadoop/spark-2.3.3 root@node2:/home/hadoop/
scp -r /home/hadoop/spark-2.3.3 root@node3:/home/hadoop/
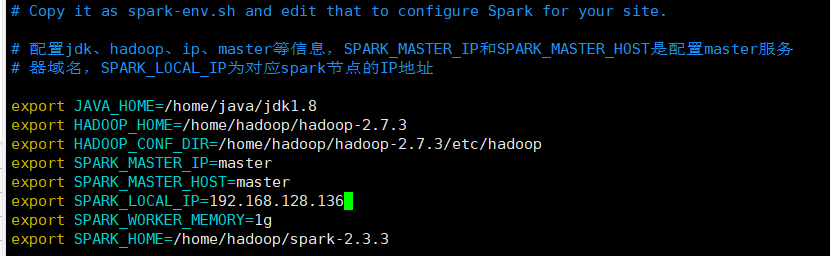
5.修改每台节点上的spark-env.sh配置文件
cd /home/hadoop/spark-2.3.3/conf
vim spark-env.sh
修改SPARK_LOCAL_IP为每台节点对应的ip地址,例如node1节点ip为192.168.128.136则修改为
export SPARK_LOCAL_IP=192.168.128.136
6.开启集群
开启spark集群
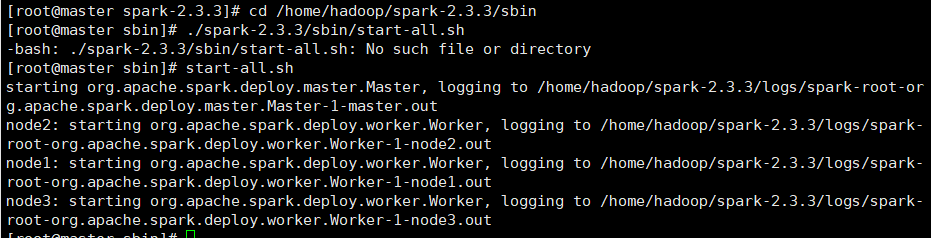
cd /home/hadoop/spark-2.3.3/sbin
start-all.sh
由于hadoop的开启脚本和spark的脚本名字一样,所以必须进入到spark的sbin目录下调用,或者更改spark脚本的名字
查看进程
首先创建jps-all.sh文件将以下内容添加:
#!/bin/bash
#输出提示信息
echo "start jps-all.sh..."
#设置映射集合
hosts="master node1 node2 node3"
#循环连接,执行脚本
for host in $hosts
do
echo "---------$host--------"
#连接host主机,调用jps指令
ssh $host "source /etc/profile; jps"
done
然后将文件上传至cd /home/hadoop/spark-2.3.3/sbin文件夹下
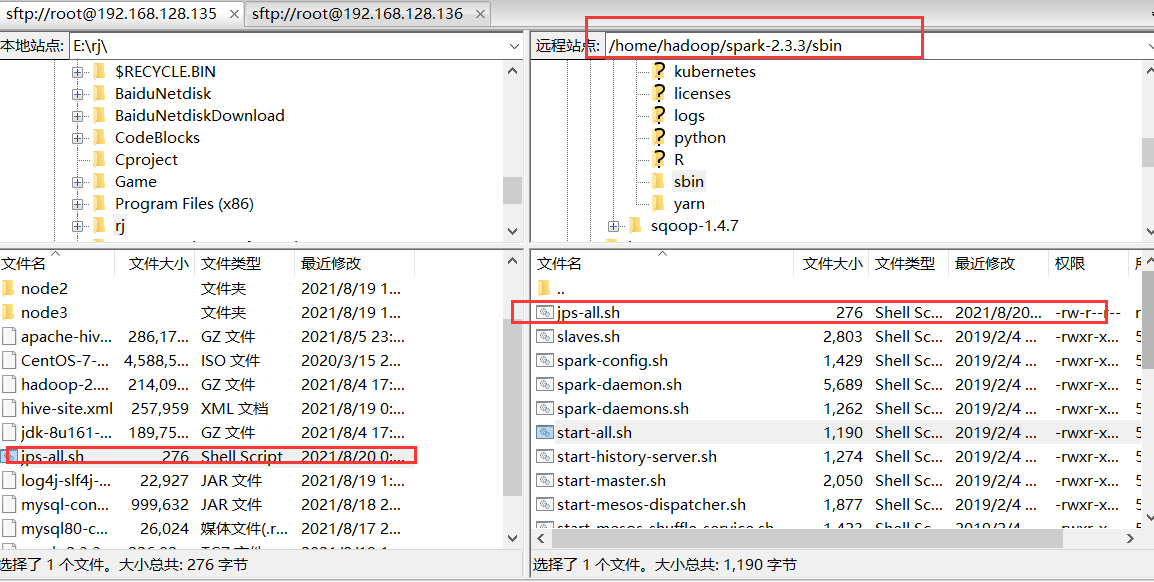
然后给予权限chmod 777 jps-all.sh
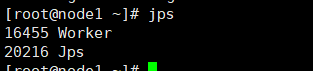
各节点用jps
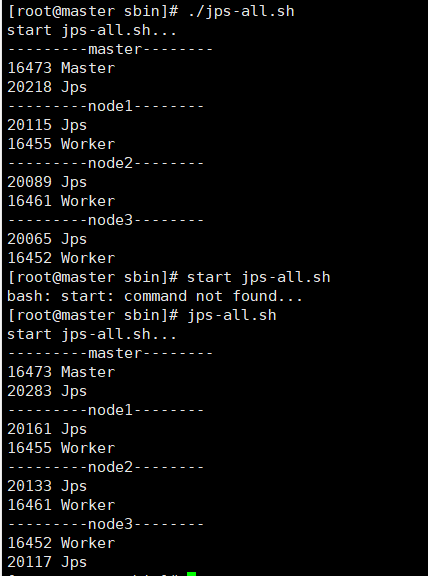
或者master使用jps-all.sh 或 ./jps-all.sh

7.web查看
在虚拟机浏览器访问master:8080
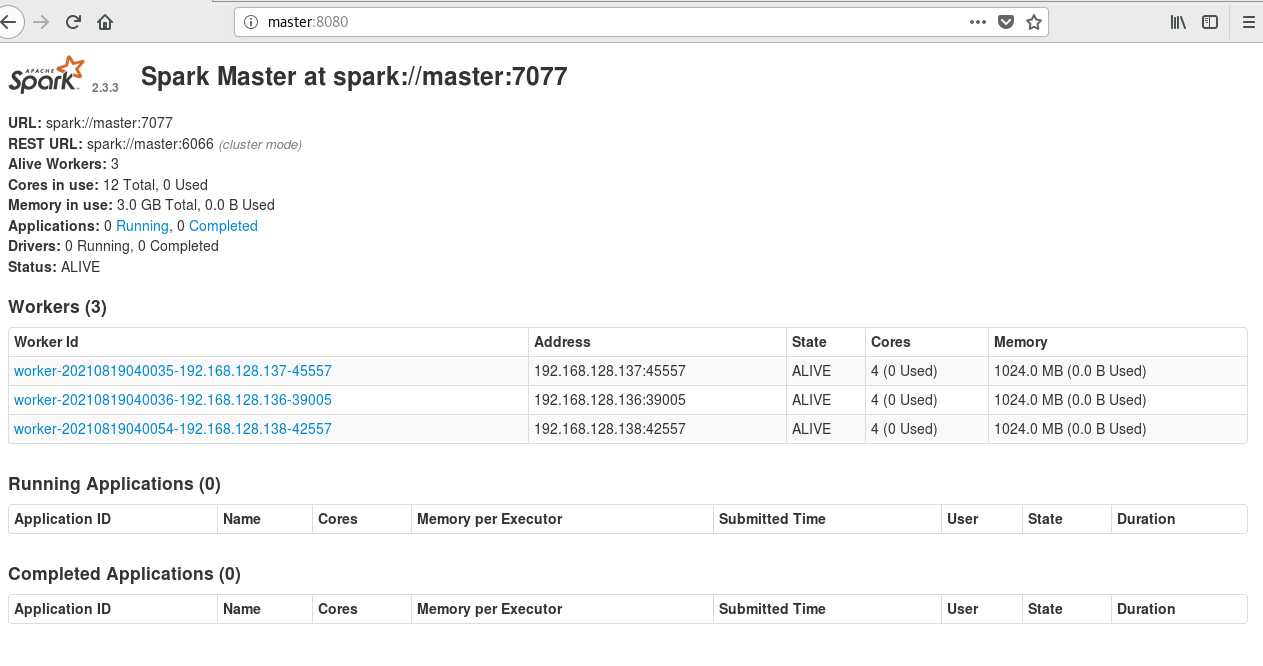
在本地浏览器访问192.168.128.135:8080
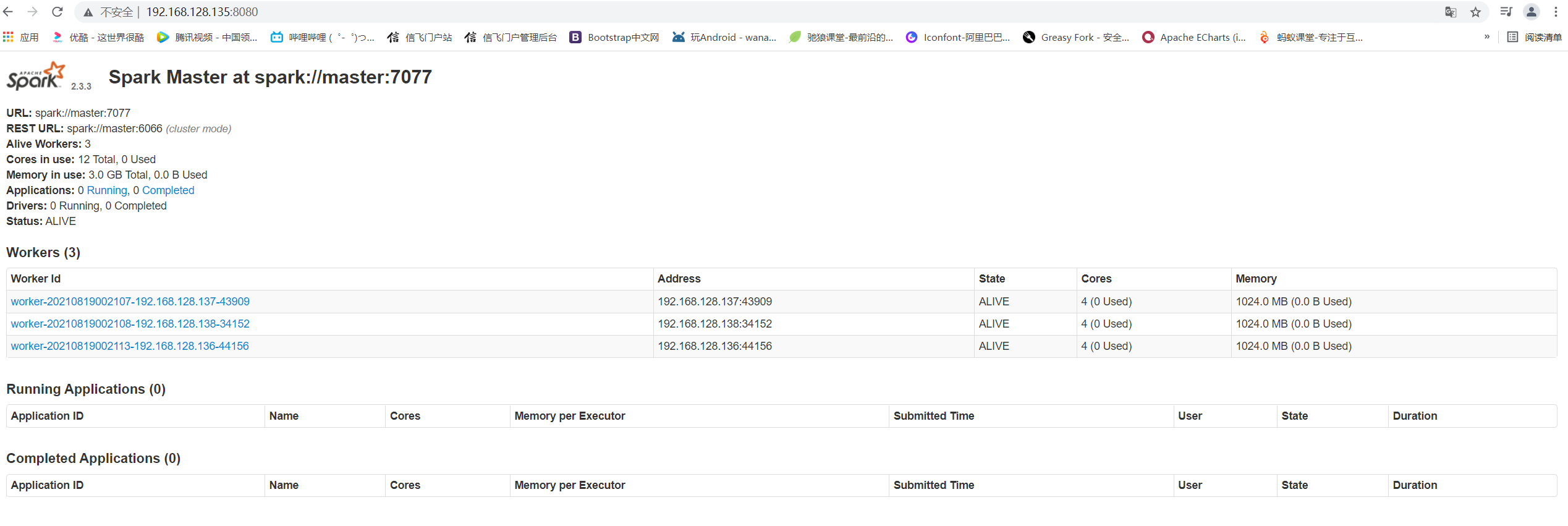
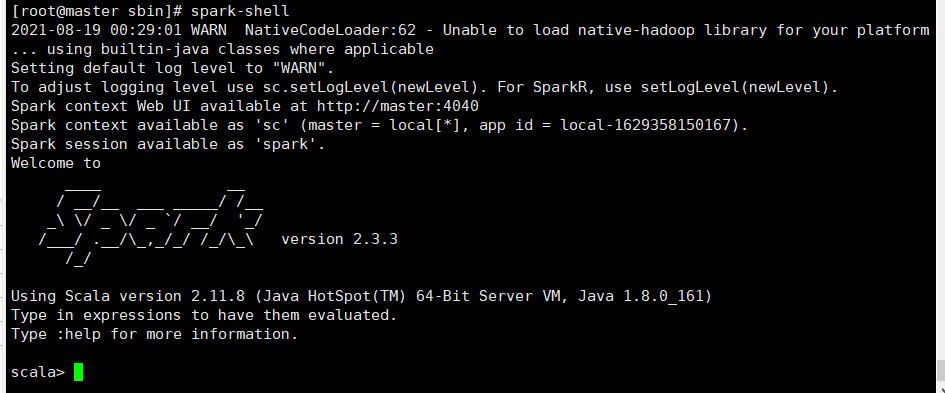
8.测试进入spark-shell环境
进入环境
spark-shell
退出环境
:quit
9.关闭集群
关闭spark集群
stop-all.sh
关闭Hadoop集群
stop-all.sh


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律