


SQL将字符串分裂成多行
SQL将字符串分裂成多行
最近遇到一个需求,我有一个表user,里面有两条记录
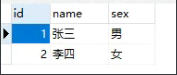
同时也有一个order表,里面有4条记录
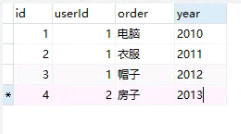
然后我需要查每个用户2010、2011、2012、2013、2014这五年的购物记录,如果有记录,就显示,如果没有记录,就字段留空。
就像下面这种结果:
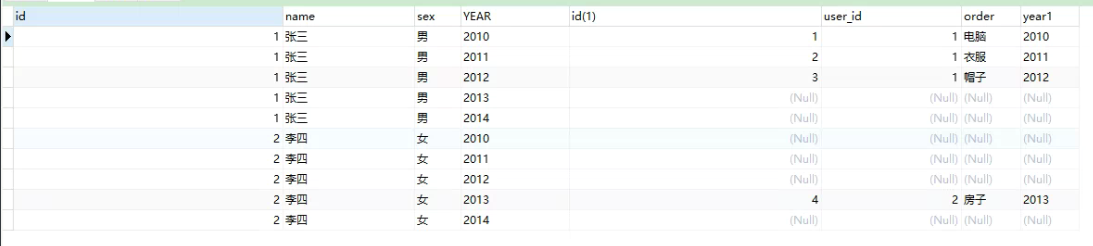
但是倘若我正常联表查询:
SELECT
*
FROM
USER u
LEFT JOIN order1 o ON u.id = o.user_id
WHERE
YEAR IN ( '2010', '2011', '2012', '2013', '2014' )
那最终也只会是下面这种效果,没有值的2014年就没有记录了。

为了实现我想要的效果,那我就必须给用户表每条记录,都加上一个年份,已达到下面的效果

而要实现这样的效果,可以考虑笛卡尔积,但是笛卡尔积也只能是表跟表进行,我传入的年份也只是字符串或者数组。我需要一个表,而且还是临时表,来实现笛卡尔积:
select
*
from
user , years
所以这个问题就转变成如何将一个数组,或者一个字符串分离成多行的问题了。
针对MySQL:
SELECT
SUBSTRING_INDEX( SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', help_topic_id + 1 ), ',',- 1 ) AS num
FROM
mysql.help_topic
WHERE
help_topic_id < LENGTH( '2010,2011,2012,2013,2014' )- LENGTH(REPLACE ( '2010,2011,2012,2013,2014', ',', '' ))+ 1
分析下这个SQL:
SUBSTRING_INDEX:切割字符串函数,返回第几个分隔符前面的字符串。
第一个参数:目标字符串
第二个参数:分割符
第三个参数:第几个分隔符,从1开始。如果是负数,则分隔符从右往左数,并且返回分隔符后面的字符串
-- 例如:
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', 1 ) 返回 2010
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', 2 ) 返回 2010,2011
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', 3 ) 返回 2010,2011,2012
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', 30 ) 返回 2010,2011,2012,2013,2014
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', -1 ) 返回 2014
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', -2 ) 返回 2013,2014
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', -3 ) 返回 2012,2013,2014
SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', -30 ) 返回 2010,2011,2012,2013,2014
-- 想必到这里,前面用两重SUBSTRING_INDEX,你们也知道是为啥了把
help_topic:这个表是mysql数据库里面的内置表,有什么用咱不需要管,咱先看下他里面有啥:

咱也不知道这玩意干啥的,但是看回我们的SQL,我们发现我们有且仅有用到这个表的help_topic_id字段,是不是突然觉得很懵,为啥要用这个字段呢?
我们再回头看下刚刚咱们分析的那个SUBSTRING_INDEX函数,他第三个参数是不是需要一个数字,从1开始,一直递增。
所以我们用这个表,仅仅是因为它id字段从0开始,而且不断递增,刚好符合我们函数的需要,而我们查这个表,他的记录就是从id为0开始。
如果你不想用这个help_topic表,或者你没有权限,你完全可以自己创建一个递增的表,插入一些记录,不需要很多字段,只要有个递增字段就OK了。
LENGTH:返回字符串的长度。
第一个参数:字符串
REPLACE:替换字符串中指定的字串
第一个参数:原字符串
第二个参数:要替换的旧串
第三个参数:要替换的新串
LENGTH( '2010,2011,2012,2013,2014' ) - LENGTH(REPLACE ( '2010,2011,2012,2013,2014', ',', '' ))+ 1
这里你们可能会不太理解,其实简化下:
LENGTH( '2010,2011,2012,2013,2014' ) - LENGTH( '20102011201220132014')+ 1
现在再看,缺了啥? 缺了分隔符。 两个长度一减,在加个1,那不就是元素的个数么
现在再看回这个SQL:
SELECT
SUBSTRING_INDEX( SUBSTRING_INDEX( '2010,2011,2012,2013,2014', ',', help_topic_id + 1 ), ',',- 1 ) AS num -- 两次切割字符串,获取元素
FROM
mysql.help_topic -- 借用一个递增字段
WHERE
help_topic_id < LENGTH( '2010,2011,2012,2013,2014' )- LENGTH(REPLACE ( '2010,2011,2012,2013,2014', ',', '' ))+ 1 -- 确定元素个数
针对postgresql:
postgresql要分离多行其实很简单
SELECT unnest(string_to_array('2010,2011,2012,2013,2014', ',')) AS year
unnest:unnest 函数将输入的数组转换成一个表,这个表的每一列都代表相应的一个数组中的元素。如果unnest与其他字段一起出现在select中,就相当于其他字段进行了一次join。
string_to_array:将字符串切割成数组
第一个参数:字符串
第二个参数:分隔符
第三个参数:指定元素用null替换
函数可以参考这个文章:https://blog.csdn.net/rocklee/article/details/79398903
针对oracle:
SELECT
regexp_substr( '2019,2020,2015,2018', '[^,]+', 1, LEVEL ) year
FROM
dual connect by LEVEL <= regexp_count ( '2019,2020,2015,2018', ',' ) + 1
regexp_substr:按正则表达式切割字符串
第一个参数:需要进行正则处理的字符串
第二个参数:进行匹配的正则表达式
第三个参数:起始位置,从字符串的第几个字符开始正则表达式匹配(默认为1) 注意:字符串最初的位置是1而不是0
第四个参数:获取第几个分割出来的组(分割后最初的字符串会按分割的顺序排列成组)
第五个参数:模式(‘i’不区分大小写进行检索;‘c’区分大小写进行检索。默认为’c’)针对的是正则表达式里字符大小写的匹配
'[^,]+' 这是个正则表达式,^是匹配开始标志,但是 ^ 在括号中,他就是“非”,而 ^, 那就是匹配除了逗号外的东西。[ ] 中括号,是一个可选内容的范围,例如[1, 2, 3, a],那就是只匹配1、2、3、a这四个字符。+ 表示至少1个。
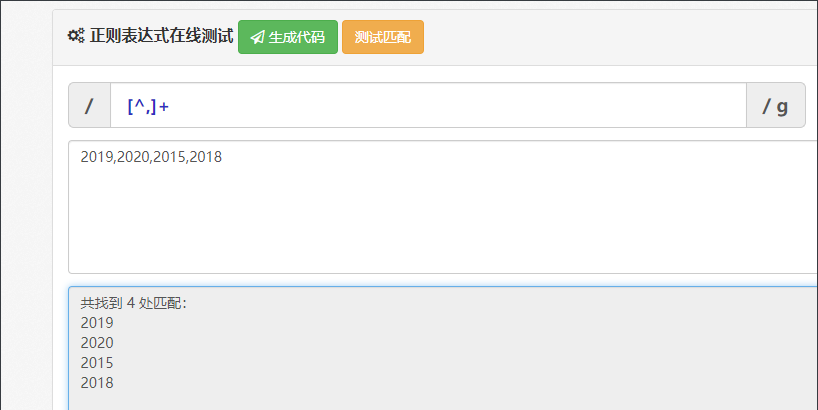
connect by :咱先来看看基本语法
select *,level from table [start with condition1] connect by [prior] id = parentid
select *,level from table [start with condition1] connect by id = [prior] parentid
一般用来查找存在父子关系的数据,也就是树形结构的数据;其返还的数据也能够明确的区分出每一层的数据。
start with condition1 是用来限制第一层的数据,或者叫根节点数据;以这部分数据为基础来查找第二层数据,然后以第二层数据查找第三层数据以此类推。
connect by [prior] id=parentid 这部分是用来指明oracle在查找数据时以怎样的一种关系去查找;比如说查找第二层的数据时用第一层数据的id去跟表里面记录的parentid字段进行匹配,如果这个条件成立那么查找出来的数据就是第二层数据,同理查找第三层第四层…等等都是按这样去匹配。
简单来说:
select * from table 把全部数据都查出来
start with condition1 根据条件筛选第一层的记录
connect by 下一层的记录需要满足什么条件
prior 这个关键字修饰的字段就是上一层的字段
level 层级,从1开始
SELECT
regexp_substr( '2019,2020,2015,2018', '[^,]+', 1, LEVEL ) year -- 正则表达式切割成数组,再根据level从1开始获取元素
FROM
dual
connect by LEVEL <= regexp_count ( '2019,2020,2015,2018', ',' ) + 1 -- 每一层都会去判断记录是否满足条件,当level到了元素个数后,就不在递归了

