

cdh-组件配置
hive
1. 设置执行引擎
set hive.execution.engine=mr;
set hive.execution.engine=spark;
如果设置执行引擎为mr,那么就会调用Hadoop的maprecude来运行需要执行job的程序;如果设置执行引擎为spark,那么就会调用spark来执行任务。有条件的话,就设置执行引擎为Spark,因为实在是运行的比Hadoop的MapReduce快了很多。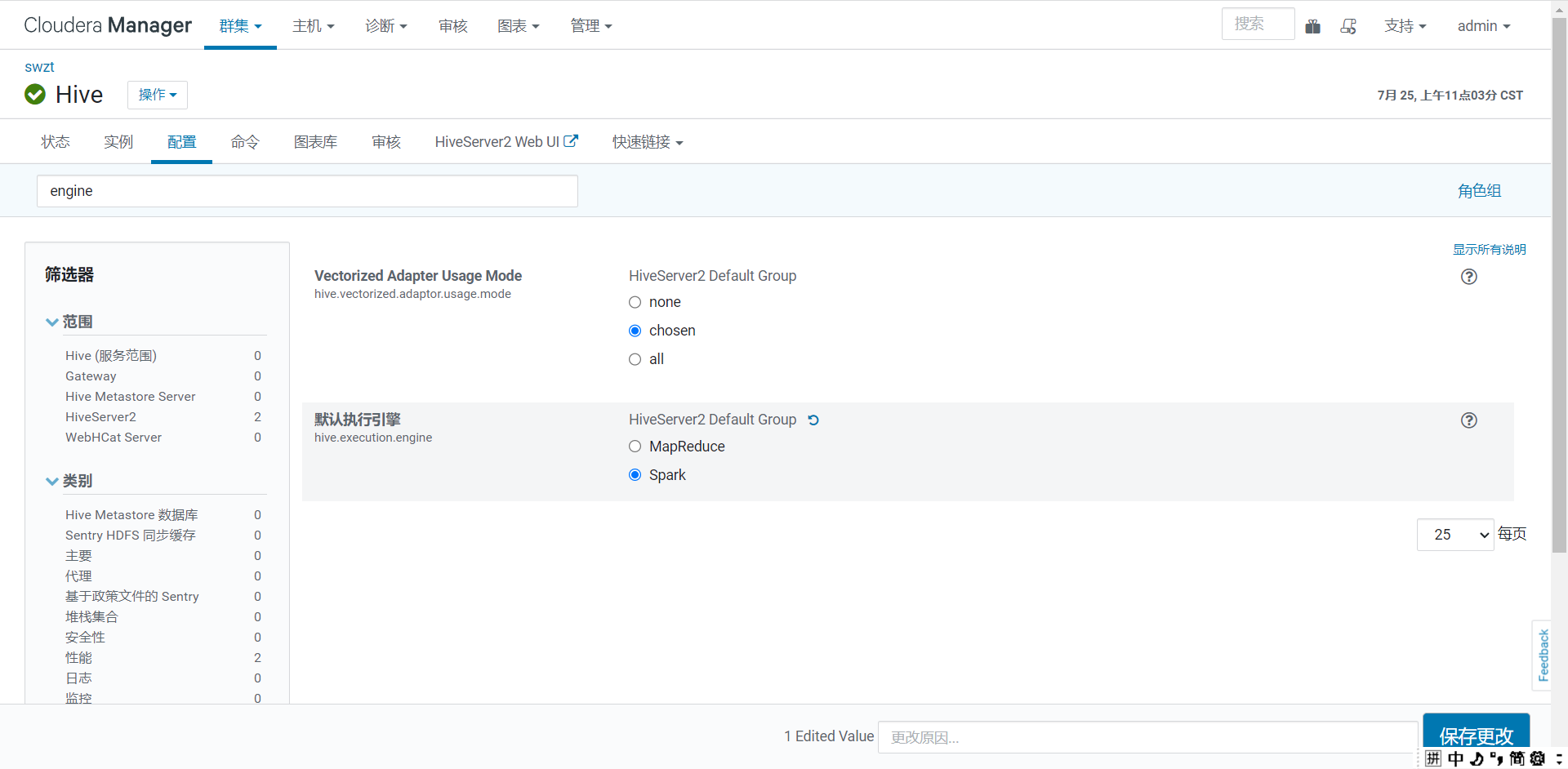
2. 针对mr调优,可以设置参数(针对map端):
set mapred.max.split.size=1000000;
这个设置每个map处理的数据大小,如果现在有一个10M的数据,那么设置参数如上,运行可以有多少个map任务呢?
10个 = 10 M / 1000000
mapreduce.map.memory.mb=4096 // 设置申请map资源 内存
mapreduce.map.cpu.vcores=1 //设置申请cpu资源(useless)
第一个参数是设置Map申请的内存大小,单位是M,这是设置也就是4G;第二个参数设置是map的cpu资源,不过这个设置没有效果(在实验的过程中因为在yarn的配置中并没有做这个配置,所以导致失效,也就是不管设置为多少其占用都是1个;如果要观察到实验效果,那么可以考虑配置集群yarn相关配置);
那假设现在有144个map任务,集群资源为:3子节点*8G内存*8核cpu,启动Hive的MR任务,同时会有多少个任务在运行呢?
要回答这个问题,就需要梳理下MapReduce运行任务时,YARN资源分配的流程;
1)YARN启动MR任务时,会首先启动一个ApplicationMaster来管理当前任务,所以启动后,这个ApplicationMaster会占用一定资源,比如我这里占用资源2G内存,1核cpu,会被随机分配到一个节点上,比如我这里的slave1节点: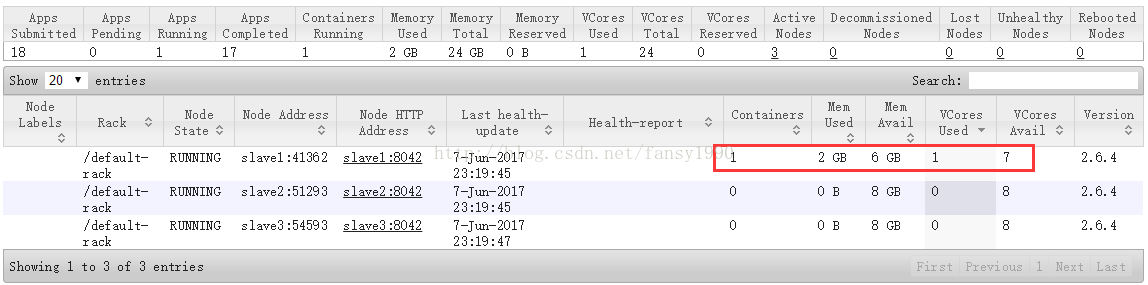
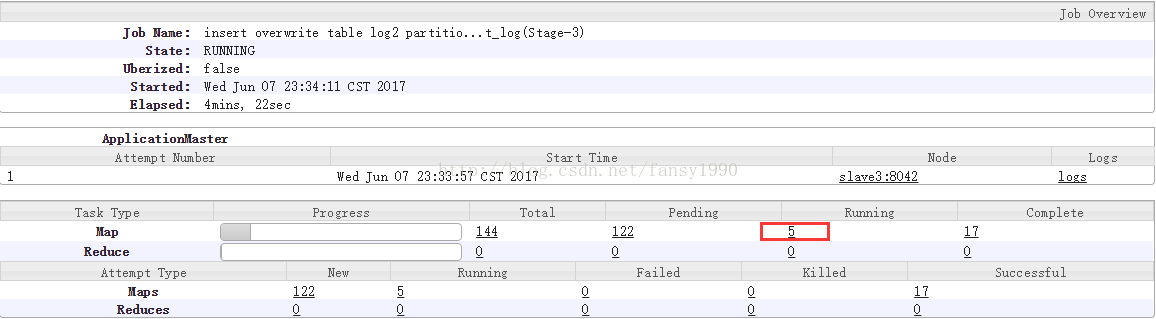
2) 接下来怎么判断可以同时运行多少个Map任务呢?
现在集群还剩资源= 22G内存+23核cpu ,如果map任务配置内存为4G,核心为1核那么,能同时运行:
5 = min(22G/4G = 5 , 23/ 1 = 23 )
也就是同时运行5个map任务,如下:
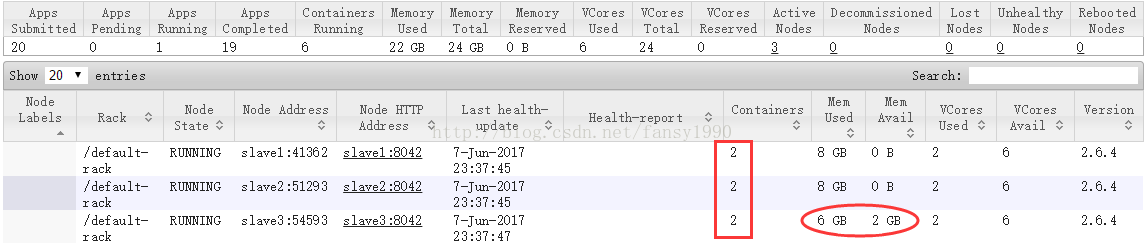
3)那这时集群还剩多少资源呢?
(3*8G内存 + 3*8核CPU )- (1核CPU,2G内存) - 5 * (4G内存,1核CPU) = (2G内存,18核CPU)
验证一下:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)