

spark foreachPartition算子
1.foreach
val list = new ArrayBuffer() myRdd.foreach(record => { list += record })
2.foreachPartition
val list = new ArrayBuffer rdd.foreachPartition(it => { it.foreach(r => { list += r }) })
说明:
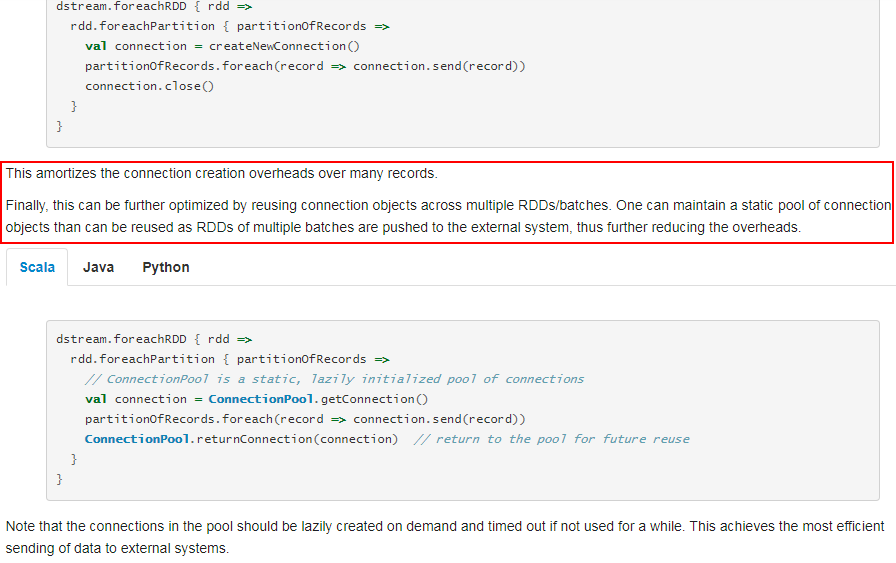
foreachPartition属于算子操作,可以提高模型效率。比如在使用foreach时,将RDD中所有数据写Mongo中,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。
参考官网的说明:
获取每个分区的索引:
rdd.foreachPartition { partitionOfRecords: Iterator[Row] =>
partitionOfRecords.foreach((record: Row) => {
println(TaskContext.getPartitionId)
print(record.get(0))
print(record.get(1))
print(record.get(2))
})
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)