

hive简介
2.1. Hive 简介
什么是 Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储,说白了hive可以理解为一个将SQL转换为MapReduce的任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端
hive元数据:
1.记录表和文件之间对应关系。
2.记录表字段和文件字段之间的关系。
元数据存储: derby、mysql
默认情况下,Hive元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用,为了支持多用户回话,需要一个独立的元数据库,所以使用 MySQL。
为什么使用 Hive
-
采用类SQL(HQL)语法去操作数据,提供快速开发的能力。
-
避免了去写MapReduce,减少开发人员的学习成本。
-
功能扩展很方便。
2.2. Hive 架构
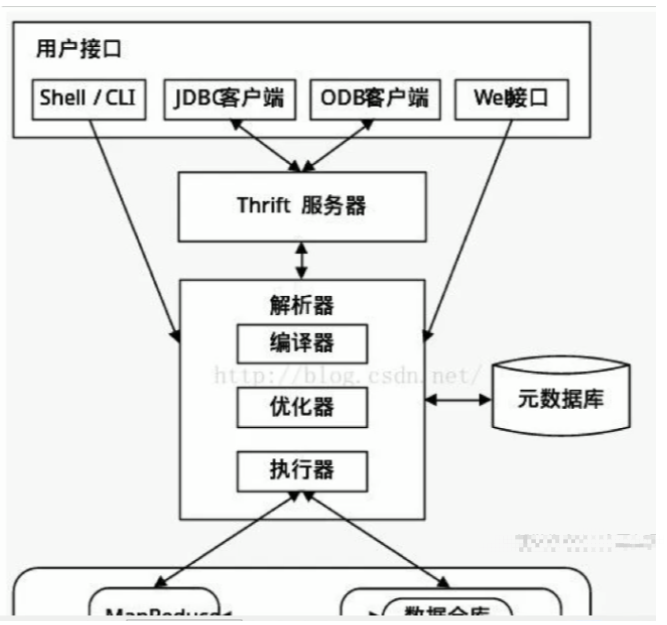
-
-
元数据存储: 通常是存储在关系数据库如mysql/derby中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
-
解释器、编译器、优化器、执行器:
2.3. Hive 与 Hadoop 的关系

2.4. Hive与传统数据库对比
hive用于海量数据的离线数据分析
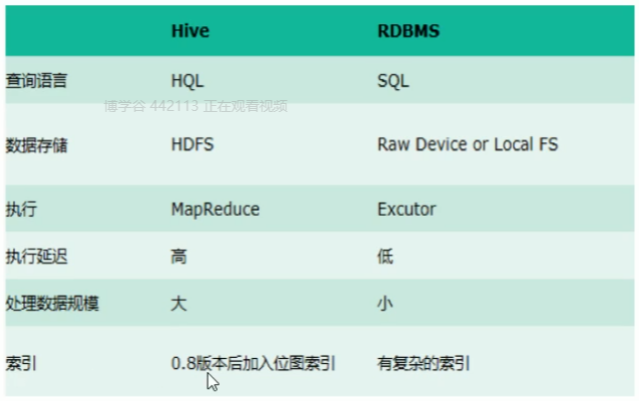
总结:hive具有sql数据库的外表,但应用场景完全不同,hive只适合用来做批量数据统计分析
hive: 分布式计算 hdfs HQL 数据量大
rdbms:执行器 磁盘 SQL 数据规模小


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)