hadoop完全分布式
虚拟机克隆
a. vim /etc/udev/rules.d/70-persistent-net.rules
更改网卡名

b. vim /etc/sysconfig/network-scripts/ifcfg-eth0
更新网卡
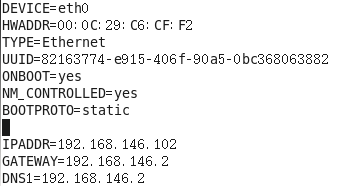
c. vim /etc/sysconfig/network
更改主机名称

d. 配置hosts
vim /etc/hosts
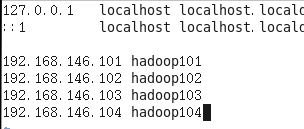
windows主机hosts:C:\Windows\System32\drivers\etc\hosts

e. 重启虚拟机
集群配置
a. 集群部署规划
| hadoop102 | hadoop103 | hadoop104 | |
| HDFS |
NameNode DataNode |
DataNode |
SecondaryNameNode DataNode |
| YARN | NodeManager |
ResourceManager NodeManager |
NodeManager |
b. 配置集群文件
配置core-site.xml
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:9000</value> </property> <!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property>
配置hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
<!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>3</value> </property> <!-- 指定Hadoop辅助名称节点主机配置 --> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:50090</value> </property>
配置yarn-env.sh
# some Java parameters export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
<!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property>
配置mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml
<!-- 指定MR运行在YARN上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
c. ssh无密登录
生成公钥和私钥
cd ~
ssh-keygen -t rsa
公钥拷贝到要免密登录的目标机器上
ssh-copy-id hadoop102 ssh-copy-id hadoop103 ssh-copy-id hadoop104
注:由于节点间的通讯,hadoop102需要root用户在配置一次,hadoop103普通用户配置一次
群起集群
a. 配置slaves
/opt/module/hadoop-2.7.2/etc/hadoop/slaves

脚本同步所有节点配置文件
b. 启动集群
sbin/start-dfs.sh
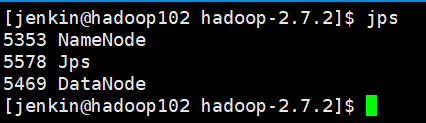
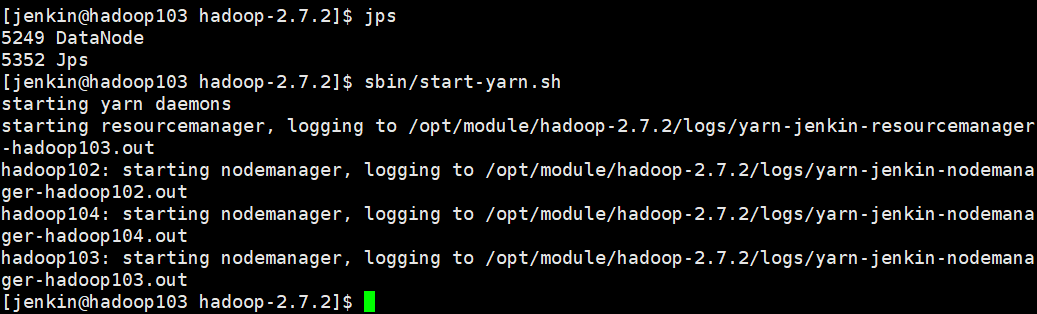
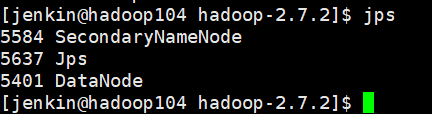
注:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
集群时间同步
时间同步的方式:找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,比如,每隔十分钟,同步一次时间
时间服务器配置
a. 检查ntp是否安装
rpm -qa | grep ntp

b. 修改ntp配置文件
vim /etc/ntp.conf
修改1(授权192.168.146.0-192.168.146.255网段上的所有机器可以从这台机器上查询和同步时间)
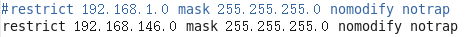
修改2(集群在局域网中,不使用其他互联网上的时间)
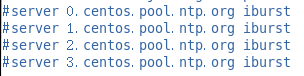
添加3(当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步)
添加在conf文件末尾
server 127.127.1.0
fudge 127.127.1.0 stratum 10
c. 修改/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd
# 让硬件时间与系统时间一起同步
SYNC_HWCLOCK=yes
d. 重新启动ntpd服务
service ntpd status
service ntpd start
e. 设置ntpd服务开机启动
chkconfig ntpd on
其他机器配置
a. 在其他机器配置10分钟与时间服务器同步一次
crontab -e
编写内容
*/10 * * * * /usr/sbin/ntpdate hadoop102
b. 修改任意机器时间
date -s "2020-11-11 11:11:11"
c. 十分钟后查看机器是否与时间服务器同步
date

 浙公网安备 33010602011771号
浙公网安备 33010602011771号