
7.逻辑回归实践
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?
(1)首先什么是过拟合?
过拟合是指训练模型时过于严格,学习能力太强,导致训练出的模型过于复杂,学习到了很多无关紧要的特征,过度拟合的问题通常发生在变量(特征)过多的时候。这种情况下训练出的方程总是能很好的拟合训练数据,此时的代价函数可能非常接近于 0 或者就为 0,出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
(2)如何防止过拟合?
1)增加样本量,适用任何模型。
2)使用正则化:如果数据稀疏,使用L1正则,其他使用L2正则较好
3)特征选择,检查选取的特征,将一些不重要的特征去除降低模型复杂度;
4)逐步回归
4)进行离散化处理,所有特征都离散化(逻辑回归特有的防止过拟合的方法)
(3)为什么正则化可以防止过拟合?
L1正则是通过增大正则项导致更多参数为0,参数系数化降低模型复杂度,从而抵抗过拟合,L2正则是通过使得参数都趋于0,变得很小,降低模型的抖动,从而抵抗过拟合。正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对会对预测或多或少产生影响影响。所以我们不能一昧的把那些特征数据删掉,我们可以利用正则化对特征数据进行减拟合,防止过拟合。
2.用logiftic回归来进行实践操作,数据不限。
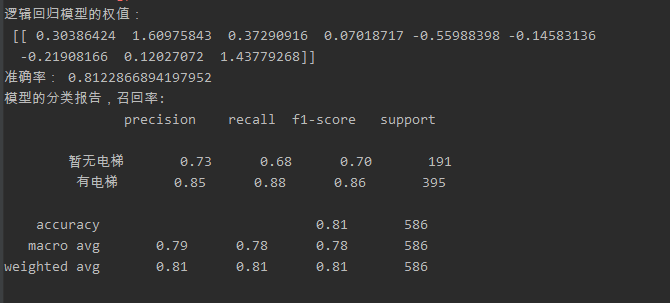
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import classification_report import pandas as pd def log_R(): data = pd.read_csv('./venv/data/房产信息.csv') # 文件为从https://guangzhou.leyoujia.com/esf/乐有家官网爬取的数据 # 201706120019hdfend.csv文件为处理有导出的数据文件 # 房屋朝向特征化: # 南:0 # 东:1 # 北:2 # 西:3 # 房屋有无电梯特征化: # 暂无:0 # 有电梯:1 # 房屋楼层特征化: # 高楼层:0 # 中楼层:1 # 低楼层:2 # 装修程度特征化: # 普装:0 # 精装:1 # 毛呸:2 # 豪装:3 x = data.loc[:, ['朝向', '时间', '楼层', '面积㎡', '室', '厅', '房', '装修程度','售价']] print(x) y = data.iloc[:, 2] print(y) #缺失值处理 data = data.dropna(axis=0) #数据分割 x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.3) # 进行标准化处理,只处理将x标准化,y不需要,因为y是只有0,1的分类 std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) #构建回归模型 LR_model = LogisticRegression() # 模型预测 LR_model.fit(x_train,y_train) # 预测结果 y_pre = LR_model.predict(x_test) print('逻辑回归模型的权值:\n', LR_model.coef_) print("准确率:",LR_model.score(x_test,y_test)) print("模型的分类报告,召回率:\n",classification_report(y_test,y_pre,target_names=["暂无电梯","有电梯"])) if __name__ == '__main__': log_R()
训练集
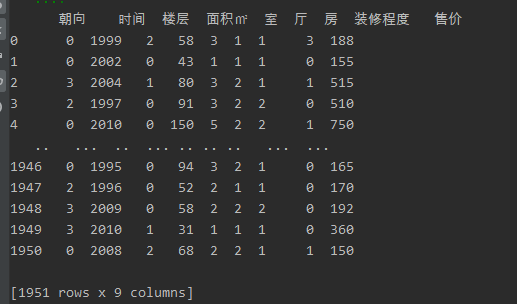
结果集
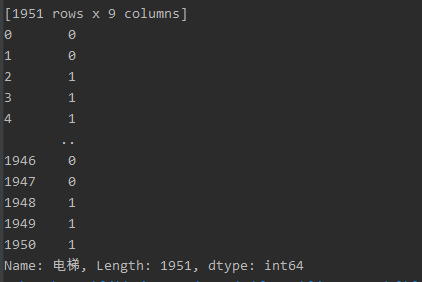
预测 结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号