python爬虫入门学习4 Selenium请求库
写在前面:
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题
selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转,输入,点击,下拉等,来拿到网页渲染之后的结果,可支持多种浏览器
from selenium import webdriver
#谷歌浏览器
browser=webdriver.Chrome()
#火狐浏览器
browser=webdriver.Firefox()
#无界面浏览器
browser=webdriver.PhantomJS()
#苹果浏览器
browser=webdriver.Safari()
#IE浏览器
browser=webdriver.Edge()
安装
#安装:selenium+chromedriver
pip3 install selenium
然后下载chromdriver.exe放到python安装路径的scripts目录中即可
国内镜像地址:npm.taobao.org/mirrors/chromedriver/2.38/
一 Selenium请求库
1.什么是selenium?
selenium是一个自动测试工具,它可以帮我通过代码
去实现驱动浏览器自动执行相应的操作。
所以我们也可以用它来做爬虫。
2.为什么要使用selenium?
主要使用selenium的目的是为了跳过登录验证。
3.安装与使用
- 下载驱动器:
http://npm.taobao.org/mirrors/chromedriver/2.38/
- 下载selenium请求库
- 修改下载源为清华源
- D:\python36\Lib\site-packages\pip\models\index.py (在Pycharm中寻找)
- PyPI = Index('https://pypi.tuna.tsinghua.edu.cn/simple')
- pip3 install selenium 或 settings中安装
- 安装谷歌浏览器
...
from selenium import webdriver #用来驱动浏览器的
import time
'''
驱动浏览器的两种方式
'''
# 第一种直接去Script文件夹中查找驱动
driver = webdriver.Chrome()
time.sleep(5)
driver.close()
# 第二种填写驱动路径
webdriver.Chrome(
二:
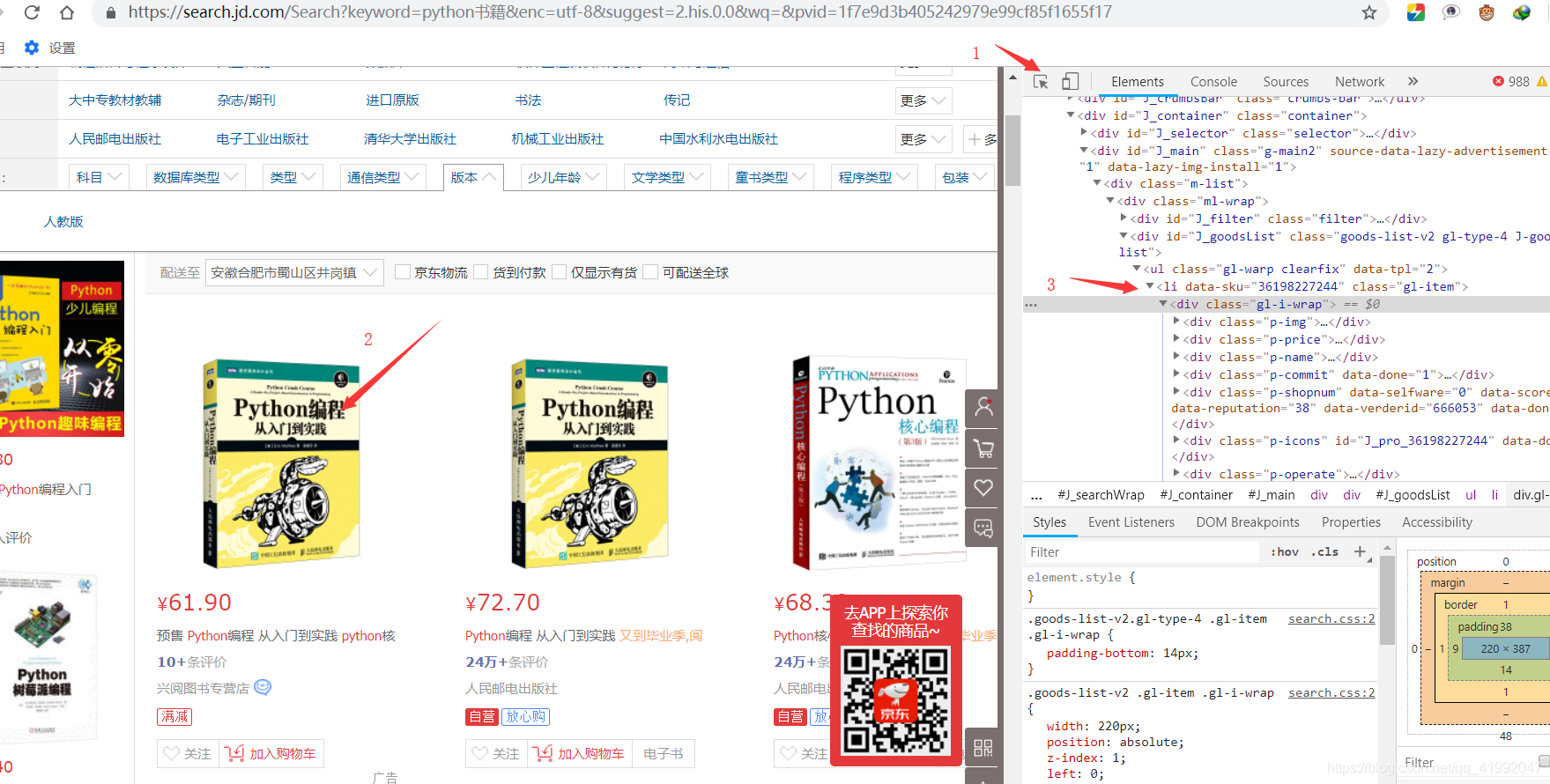
获取京东商城python书的价格,评论,url
首先总结一下各种查找方式
# 1、find_element_by_id 通过id元素去找
# 2、find_element_by_link_text 通过链接文本去找,根据精确文本匹配内容
# 3、find_element_by_partial_link_text # 根据文本局部匹配去查找标签
# 4、find_element_by_tag_name # 根据标签名查找
# 5、find_element_by_class_name #根据类元素查找
# 6、find_element_by_name #根据name属性去查找
# 7、find_element_by_css_selector #根据属性选择器查找
# 8、find_element_by_xpath #根据xpath查找
#element 找一个
#elments找多个
#查找所有的商品列表
good_list=driver.find_elements_by_class_name('gl-item')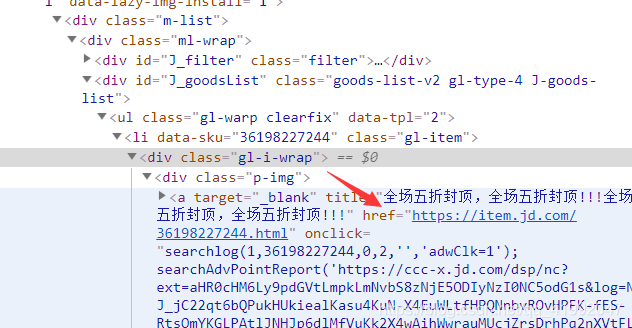
#通过属性选择器查找商品详情页url
#url
good_url=good.find_element_by_css_selector('.p-img a').get_attribute('href')
print(good_url)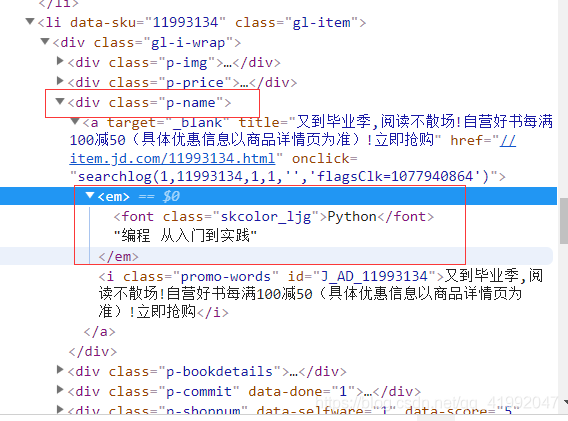
#名称
good_name=good.find_element_by_css_selector('.p-name em').text
print(good_name)
#价格
good_price=good.find_element_by_class_name('p-price').text
print(good_price)
#评价数
good_commit=good.find_element_by_class_name('p-commit').text
print(good_commit)from selenium import webdriver
#导入键盘keys
from selenium.webdriver.common.keys import Keys #键盘按键操作
import time
driver=webdriver.Chrome()
#检测代码块
try:
#隐式等待,等待标签加载
driver.implicitly_wait(10)
#往京东主页发送请求
driver.get('https://www.jd.com')
#通过id查找input输入框
input_tag=driver.find_element_by_id('key')
#send_keys为当前标签传值
input_tag.send_keys('python书')
#按键盘的回车键
input_tag.send_keys(Keys.ENTER)
time.sleep(3)
'''
爬取京东商品信息
python书
名称
url
价格
评价
'''
#element 找一个
#elments找多个
#查找所有的商品列表
good_list=driver.find_elements_by_class_name('gl-item')
#循环遍历每一个商品
for good in good_list:
#通过属性选择器查找商品详情页url
#url
good_url=good.find_element_by_css_selector('.p-img a').get_attribute('href')
print(good_url)
#名称
good_name=good.find_element_by_css_selector('.p-name em').text
print(good_name)
#价格
good_price=good.find_element_by_class_name('p-price').text
print(good_price)
#评价数
good_commit=good.find_element_by_class_name('p-commit').text
print(good_commit)
str1=f'''
url:{good_url}
名称:{good_name}
价格:{good_price}
评价:{good_commit}
\n
'''
#把商品信息写入文本中
with open('jd.txt','a',encoding='utf-8') as f:
f.write(str1)
time.sleep(10)
#捕获异常
except Exception as e:
print(e)
#最后都会把驱动浏览器关闭掉
finally:
driver.close()from selenium import webdriver
#导入键盘Keys
from selenium.webdriver.common.keys import Keys
import time
driver=webdriver.Chrome()
#检测代码块
try:
#隐式等待,等待标签加载
driver.implicitly_wait(10)
#往京东主页发送请求
driver.get('https:www.jd.com/')
#通过id查找input输入框
input_tag=driver.find_element_by_id('key')
#send_keys为当前标签传值
input_tag.send_keys('python书籍')
#按键盘的回车键
input_tag.send_keys(Keys.ENTER)
time.sleep(10)
#捕获异常
except Exception as e:
print(e)
#最后都会把驱动器关掉
finally:
driver.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号