
爬虫学习(二)requests模块的使用
一、requests的概述
requests模块是用于发送网络请求,返回响应数据。底层实现是urllib,而且简单易用,在python2、python3中通用,能够自动帮助我们解压(gzip压缩的等)网页内容。
二、requests的基本使用
1、基本使用:
- 安装requests模块:
pip install requests - 导入模块:
import reqeusts - 发送请求,获取响应:response = requests.get(url)
- 从响应中获取数据
2、方法:
(1)requests.get(url, params=None, **kwargs),发送一个get请求,返回一个Response对象
- url:请求的url
- params:get请求的?后面可选参数字典
方式一:自己拼接一个带有参数的URL,比如"https://www.sogou.com/web?query={}"
方式二:在发送请求时,使用params指定,格式requests.get("url", params={}) - **kwargs:可选参数
headers:请求头参数字典。
proxies:代理参数字典。# 请求头格式 headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36" } requests.get(url, headers=headers)
# 代理格式 proxies = { "http": "http://ip:端口号", "https": "https://ip:端口号" } requests.get(url, proxies=proxies) # 使用需要账号和密码的代理 proxies = { "http":"http://username:password@ip:端口号", "https": "https://username:password@ip:端口号" } request.get(url, proxies=proxies)
cookies:cookies参数字典。
verify:请求SSL证书验证。
timeout:设置超时。能够加快整体的请求速度。
(2)requests.post(url, data=None, json=None, **kwargs),发送一个post请求
- url:
- data:
- json:
- **kwargs:可选参数
headers:请求头参数字典
proxies:代理参数字典。
cookies:cookies参数字典。
(3)requests.util.dict_from_cookiejar(cj):把cookie对象转化为字典
- cj:cookie对象(response.cookies)
(4)requests.util.quote(url):URL编码
(5)requests.util.unquote(url):URL解密
3、对象:
(1)Response对象,是发送请求后的响应对象
常用属性:
- Response.text:str类型的响应数据
- Response.content:二进制类型的响应数据
- Response.status_code:响应状态码
- Response.headers:响应头
- Response.request.headers:请求头
- Response.json() :获取json类型的响应数据,如果返回的数据不是json类型就不能使用
三、代理
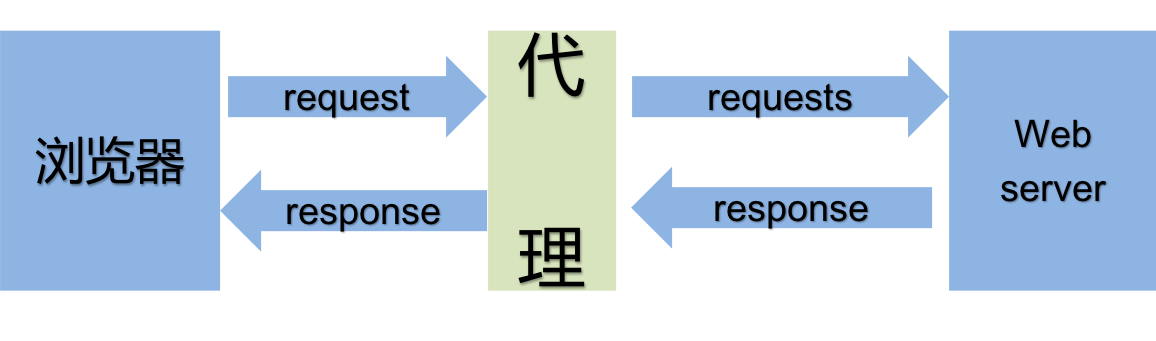
在requests模块中使用代理发送请求的原因是:如果使用一个固定IP不断的发送请求,服务器会认为这样的操作不是人干的,就把你的IP给封了,而且还会根据你的IP快速锁定你。
代理的分类:
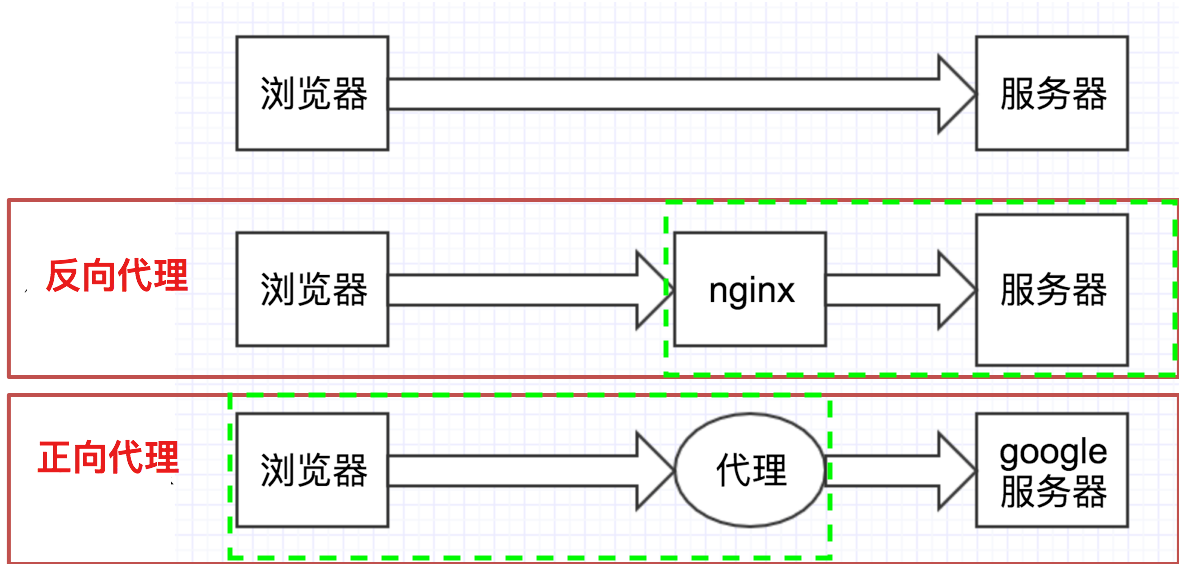
1、正向代理:
- 客户端知道代理的存在,正向代理是为了保护客户端,防止被追踪。
- 服务端不知道真实的客户端。
2、反向代理:
- 服务器端知道代理的存在,反向代理是为了保护服务器或负责负载均衡。
- 客户端不知道代理的存在。

代理IP的分类
1、根据匿名程度:
- 透明代理:透明代理虽然可以直接隐藏你的IP地址,但是还是可以查到你是谁。
- 匿名代理:别人只能知道你用了代理,无法知道你是谁。
- 高匿代理:让别人根本无法发现你是在用代理,所以是最好的选择。
2、根据请求的协议:
- http代理
- https代理
- socket代理
不同分类的代理,在使用的时候需要根据抓取网站的协议来选择。
使用代理IP的注意点:
- 反反爬:使用代理IP时使用随机的方式进行选择使用,不要每次都使用一个代理IP。
- 更新代理IP池:购买的代理IP很多时候大部分可能无法使用了,需要通过程序去检验哪些可用,把不能用的删除掉。
import random import requests # 1. 准备代理列表 proxies = [ {'http': '121.8.98.198:80'}, {'http': '39.108.234.144:80'}, {'http': '125.120.201.68:808'}, {'http': '120.24.216.39:60443'}, {'http': '121.8.98.198:80'}, {'http': '121.8.98.198:80'} ] # 2. 随机选出一个代理 for i in range(0, 10): proxy = random.choice(proxies) print(proxy) try: response = requests.get("http://www.baidu.com", proxies=proxy, timeout=3) print(response.status_code) except Exception as ex: print("代理有问题: %s" % proxy)
四、获取服务器端登录后的资源
三种方式:
- 发送请求的时候,在headers中指定cookie字符串。
headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36", # "Cookie": cookie_str }
- 发送请求的时候,通过cookies参数指定,是一个字典。
response = requests.get(url, headers= headers, cookies=cookie_dic)
- 使用session进行登录,登录后使用session访问登录后资源,这时session会自动携带cookie信息。
-
import requests # 1. 获取session对象 session = requests.session() headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36", } # 2. 使用session对象,进行登录,登录后seesion对象会记录用户相关的cookie信息 login_url = "http://www.renren.com/PLogin.do" data = { "email":"15565280933", "password":"a123456" } response = session.post(login_url, data=data, headers=headers) print(response.status_code) print(response.content.decode()) # 3. 再使用记录cookie信息对象session访问个人主页 profile_url = "http://www.renren.com/965194180/profile" response = session.get(profile_url)
五、retrying模块的使用
如果访问速度很慢,可以选择刷新页面,在代码中使用retrying模块刷新请求,通过装饰器的方式,让被装饰的函数反复执行。
@retry(stop_max_attempt_number=3),让函数报错后继续重新执行,达到最大执行次数的上限,如果每次都报错,整个函数报错,如果中间有一个成功,程序继续往后执行
- stop_max_attempt_number:最大重试次数。
import requests from retrying import retry headers = {} #最大重试3次,3次全部报错,才会报错 @retry(stop_max_attempt_number=3) def _parse_url(url) #超时的时候会报错并重试 response = requests.get(url, headers=headers, timeout=3) #状态码不是200,也会报错并重试 assert response.status_code == 200 return response def parse_url(url) try: #进行异常捕获 response = _parse_url(url) except Exception as e: print(e) #报错返回None response = None return response

 浙公网安备 33010602011771号
浙公网安备 33010602011771号