如何给本地部署的DeepSeek投喂数据,让他更懂你
如何给本地部署的DeepSeek投喂数据,让他更懂你
写在前面
在上一篇文章中,我们说了怎么在本地部署DeepSeek。对本地部署DeepSeek感兴趣的小伙伴看过来。
本地部署 DeepSeek:小白也能轻松搞定!
话说回来了,为啥要本地部署呢?
① 在使用DeepSeek中,经常会出现服务器繁忙,请稍后再试。
② 不想让个人隐私数据暴露出去
③ 可以将各种格式的文件,如pdf、csv、txt、md 格式的数据投喂给它。比如你想让 DeepSeek 了解你的公司业务,就把相关的文档上传给它。
DeepSeek 就能吃下你给它的各种“知识大餐”,然后变得更聪明,更懂你
一、RAG是什么?
为了投喂数据,我们要用到RAG。首先,我们先来了解下什么是RAG?
我们就问问昨天部署好的DeepSeek好了。
首先我们在命令行输入:ollama run deepseek-r1:1.5b 命令,启动DeepSeek
然后打开浏览器并输入快捷键:ctrl+shift+l 调出WebUI可视化AI界面
输入:RAG是什么?
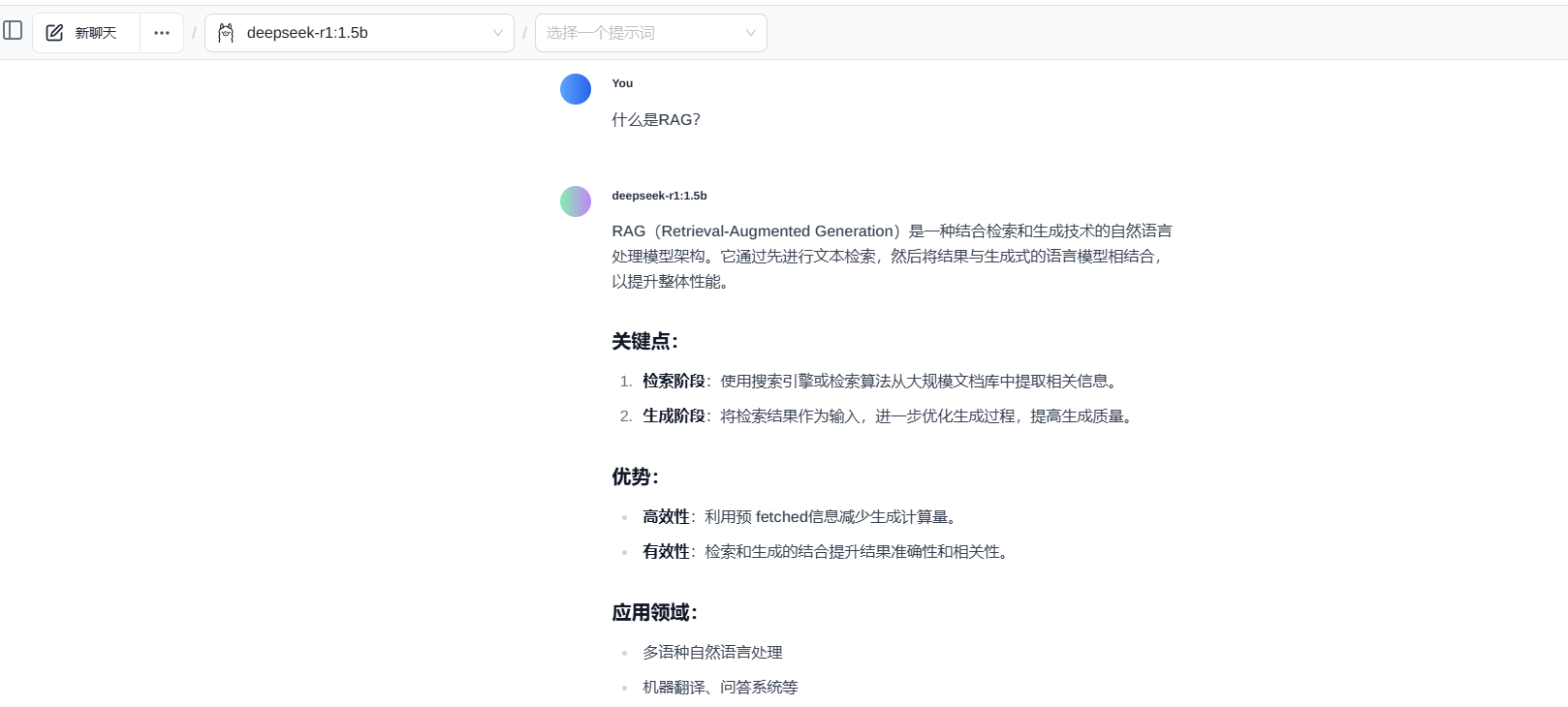
翻译成大白话就是:我们把知识放到知识库里,然后把它投喂给人工智能。我们需要用一个量化的工具,把各种格式的数据量化给人工智能,让它能看得懂。
人工智能通过对这些知识的学习后,以后你再问它的时候,他就能将知识提取出来,加工处理后回答你的问题。
RAG 就是让 DeepSeek 不仅能靠自己的知识库回答问题,还能通过检索外部数据来增强回答的准确性和丰富性。就好比你考试时偷偷带了小抄,但 DeepSeek 是光明正大地“作弊”,还能把答案说得头头是道。
二、 拉取nomic-embed-text
刚说了RAG是啥?我们需要一个RAG工具来完成量化工作。
各种开源免费的RAG工具挺多,我们这里选择最近比较获得ollama 提供的nomic-embed-text。
https://ollama.com/library/nomic-embed-text
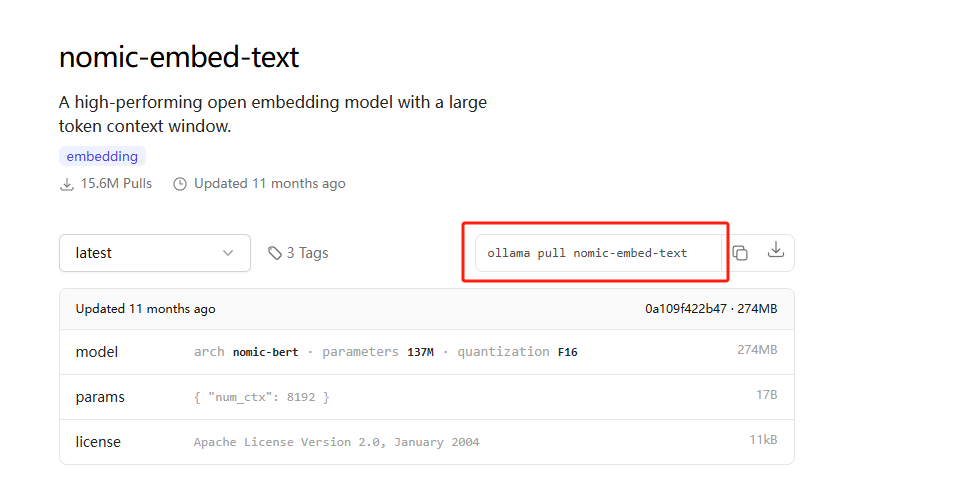
我们使用上面圈出来的命令拉取即可,274M,大约1min左右就可以下完,出现【success】字样表示下载成功。

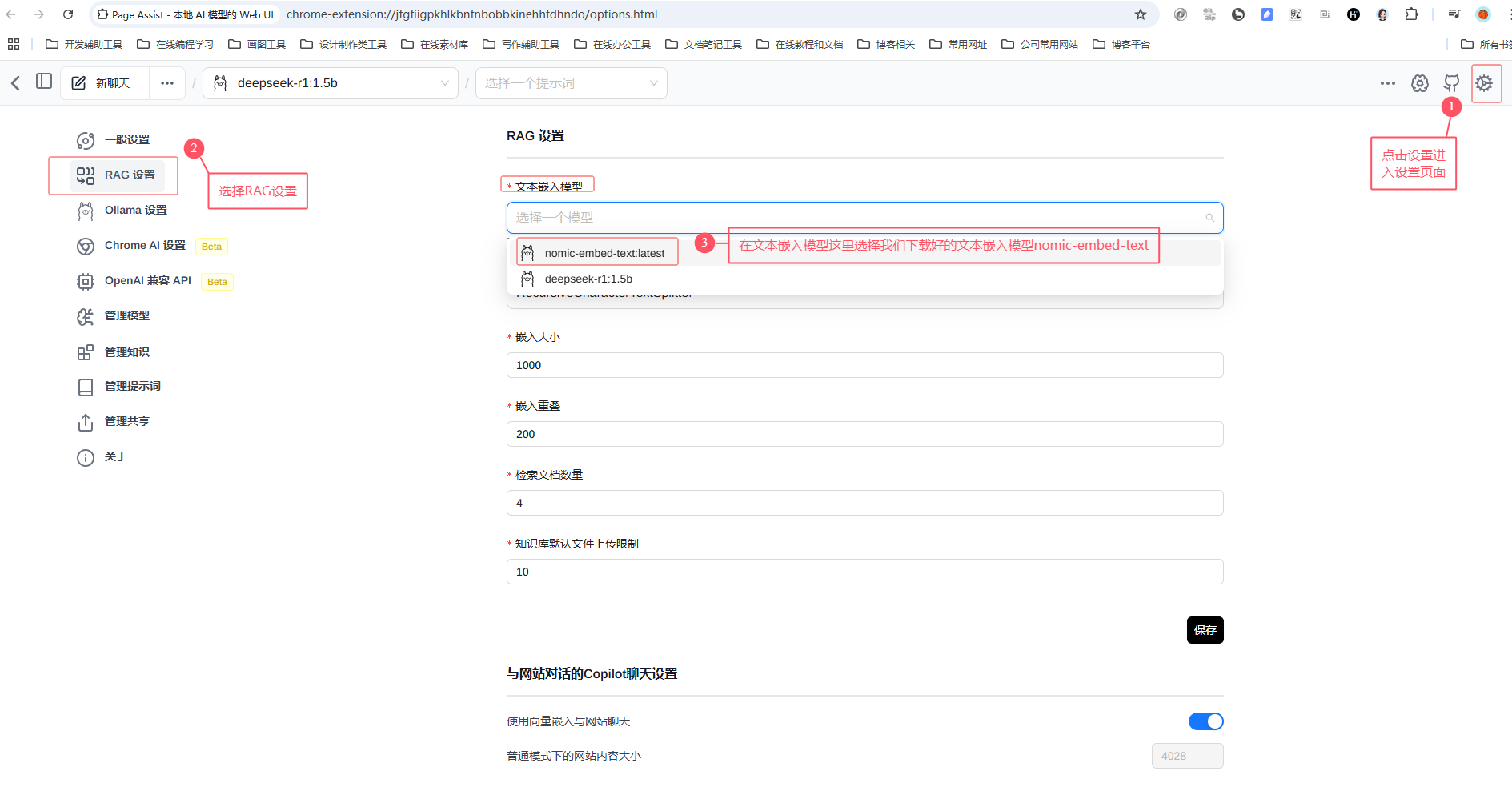
三、RAG设置
打开WebUI界面,我们会看到一个RAG设置文本嵌入模型。
文本嵌入模型就是把我们投喂的各种文档数据量化成DeepSeek认识的数据。
四、添加新知识
工具都准备好后,我们开始准备给DeepSeek投喂数据......
① 投喂前不认识晓凡
在投喂数据之前,我们问问它认不认识晓凡。结果不用我说了,肯定是不知道的 😅

 浙公网安备 33010602011771号
浙公网安备 33010602011771号