【Transformer 基础系列】手推显存占用
https://zhuanlan.zhihu.com/p/648924115
本文试图以最清晰的方式手动推导 Transformers 每一步的参数量到显存、计算量问题。理解底层,才能更好的做训练和优化。可能是目前最全的大模型显存优化方案分析。
本文内容包括
(1)模型训练和推理过程中的显存占用
(2)KV cache、中间激活值等显存占用
(3)模型状态显存优化方案: Megatron(3D) + Deepspeed(ZeRO)(更新于2023-09-11)
(4)激活值显存优化方案:重计算 + 3D 并行(更新于2023-08-11)
(5)KV Cache 显存优化方案:MQA 和 GQA(更新于2023-09-11)
关于计算量、参数量的分析在本系列其他文章记录。
乞力马扎罗不说话:【Transformer 基础系列】手推计算量FLOPS和训练时间
乞力马扎罗不说话:【Transformer 基础系列】模型参数量
0 前置知识和标记
- 显存占用 = 参数数量 x 该参数精度占用的 bytes 数
- 换算关系:Int8 需1 bytes, fp16 / bf16 数需 2 bytes, fp32 需要 4 bytes
- transformer 模型的层数为 �
- 隐藏层维度为 ℎ
- 注意力头数为 �
- 词表大小为 �
- 批次大小为 �
- 序列长度为 �
1 训练过程
训练中的显存占用分两块,分别是:
- 模型状态,参数、梯度和优化器状态
- 剩余状态, 中间激活值、临时buffer、显存碎片等
1-1 模型状态显存
模型状态指的是和模型参数、梯度和优化器状态相关的显存占用。
设模型参数量为 Φ ,模型参数(fp16)、模型梯度(fp16)和优化器状态(fp32),总参数量 = 2Φ+2Φ+�Φ=(4+�)Φ 。参数量和模型配置之间的关系可以看另一篇文章推导,合计约 �ℎ+�(12ℎ2+13ℎ) 。
一般是混合精度训练,梯度/权重为 fp16,但所有涉及累加操作都需要 fp32 防止误差累计,同时优化器也要存 fp32 主权重。以 Adam 系列为例,总数为 2Φ+2Φ+(4+4+4)Φ=16Φ 。
- 这部分比较固定,主要和参数量有关,和输入大小无关。
- 在整个训练过程中都要存在显存中。 模型参数一般只能通过并行切分(Tensor Parallelism/Pipeline Parallism)能减少。优化器状态一般通过ZeRO 来减少。
- 不同优化器的 K 值不同,算法的中间变量、框架的实现都有可能有一定区别。复旦 LOMO 的方法也是基于类似的思路重新改进 SGD 来减少 K 值和梯度部分显存。
不同优化器的 K 值
| 优化器 | K值 | 构成 |
|---|---|---|
| adamw | 12 | fp32 主权重 4 + 动量 4 +方差 4 |
| SGD | 8 | fp32 主权重 4 + 动量 4 |
| bitsandbytes | 6 | fp32 主权重 + 动量 1 + 方差 1 |
| LOMO | 0 |
1-2 中间激活值显存
激活(activations)指的是前向传递过程中计算得到的,并在后向传递过程中需要用到的所有张量。
中间激活值占用显存分两个部分分析:Attention 和 MLP,Embedding 没有中间值。最终合计 (34��ℎ+5��2�)∗�=(13��ℎ+5��2�+21��ℎ)∗� 。
- 这部分比较灵活,激活值与输入数据的大小(批次大小 b 和序列长度 )成正相关。
- 在训练过程中是变化值,特别是 batch size 大的时候成倍增长很容易导致 OOM。
- 可以通过重计算、并行切分策略减少。
直接看公式不太直观,下面是 GPT-3 和 LLaMA 为例计算的模型显存和中间激活值显存占用比例。
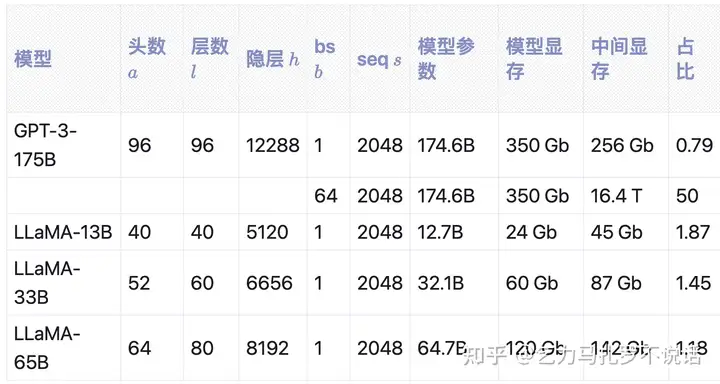
Attention 层中间显存表
self-attention 块的计算公式如下: �=���,�=���,�=��� ����=�������(���ℎ)⋅�⋅��+�
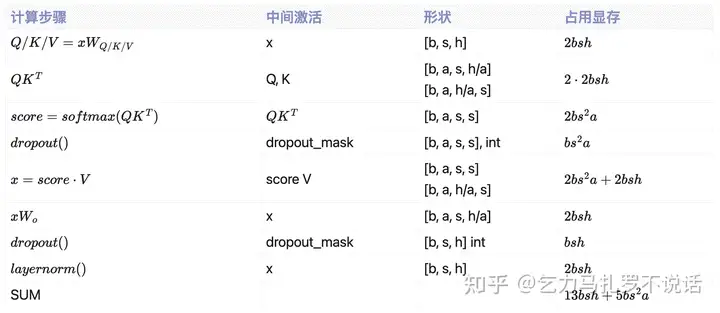
Attention 层单步中间激活值显存表
MLP 层中间显存表
MLP 块的计算公式如下:
�=�����(�����1)�2+����

MLP 层单步中间激活值显存表
2 模型状态显存优化方案
如 1-1 所推,模型状态占用 2Φ+2Φ+�Φ=(4+�)Φ,其中一般只能通过各种各样的并行来解决。比如模型参数显存优化一般是 模型并行,包括张量并行 (tensor parallel, TP) 和流水线并行(pipeline parallel, PP),业内通用方案参考 Megatron。只做数据并行 (data parallelism, DP) 情况下,模型参数和优化器状态一般通过 Deepspeed ZeRO 来均摊到所有卡上。
总的来说,都是用通信时间换显存空间。业内很多框架也是基于 Megatron+Deepspeed 这一套比较成熟的底层上改的。
2-1 Megatron-LM 3D Parallel
Megatron-LM 里称之为 Model Parallel,也叫 Tensor Parallel。
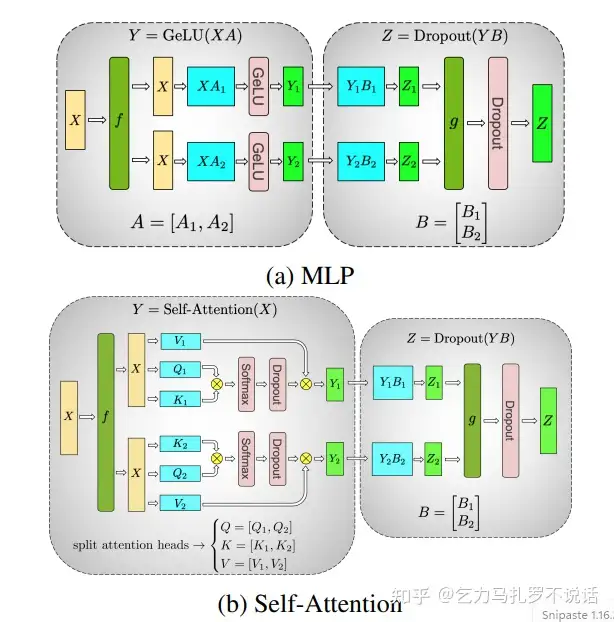
Q / K / V 矩阵做列切分(纵刀流),对Dropout做行切分(横刀流),方便GPU 中间计算各算各的,减少额外通信
不切分的时候各层参数如下表

Model Parallel 需要切分所有参数 embedding / attention / mlp 为 � 份,其中 embedding 层 V 在 Megatron 中会补全到最小的 � 倍数以便于切分。因此,显存为 �′ℎ+(12ℎ2+13ℎ)�� 。
Pipeline Parallel 需要按层切分所有参数,一般是 � 层均分 � 份,embedding 在最前面一层或单独一层。不过针对一些奇特结构不能整除的(比如44层的 NeoX)可能需要设计特定切分策略。每层显存为 (12ℎ2+13ℎ)�/� 。
这里显存都没什么好说的,主要是通信量值得分析。
2-2 ZeRO Stage 1-3
Deepspeed ZeRO 本质上都是在数据并行层面对模型状态一步步做分片(partition),系统内只维护一份模型状态,需要全量状态时就执行通信。
ZeRO Stage: 不同 stage 区别主要是切什么,显存占用论文里这张图就很直观了。
- Stage 1(P os): fp32 optimizer state
- Stage 2(P os+g): fp32 gradient + Stage 1
- Stage 3(P os+g+p): fp16 parameters + Stage 1 + Stage 2
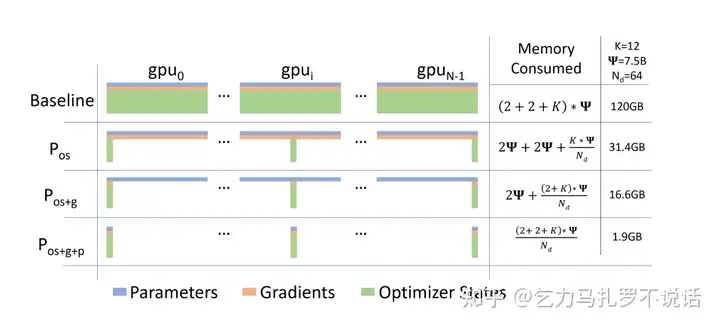
- 总卡数越多越省。stage 1 下,按照一个节点估算,模型状态从 16Φ→5.5Φ ,如果是现在一般规模的预训练规模,卡数至少上百,优化器状态可以忽略不计,模型状态基本接近。
- Stage 1和2 不会额外增加通信量,Stage 3 会额外增加 50%(forward 和 backward 时分别一次 broadcast 参数以获得全量参数),因此后面 Deepspeed ZeRO++ 支持了 stage 3 量化和参数分层存储来降低通信量。
- ZeRO 除了分片还支持 offload,显存不够内存来凑,但是内存显存之间的 I/O 成本也不可忽视,因此实际训练中还是很少用。
- All-reduce 通信到底怎么充分利用设备和设备之间的带宽也很有趣,请参考袁老师文章 OneFlow:手把手推导Ring All-reduce的数学性质。
3 中间激活值显存优化
1-2 中中间激活值式子可以看到,激活值与输入数据的大小成正相关,batch size 较大时远超过模型参数占用。因此主要显存优化是优化中间激活值,有重计算和并行两个思路
(34��ℎ+5��2�)∗�=(13��ℎ+5��2�+21��ℎ)∗�
3-1 重计算
- activation checkpoint (recompute) :时间换空间,前向的时候重新计算一次来避免存储。计算量的增加参考另一篇博客。
- 全部重计算可以减少到只有每个 attn 层输入的 2��ℎ�
- 部分重计算可以减少 �(�2) 项相关的 QK 乘法中间结果,其他不变,减少到 34��ℎ�
3-2 TP 中间激活值
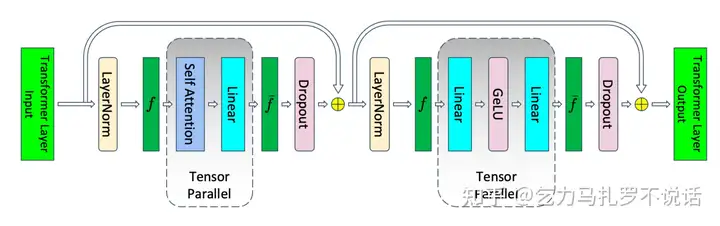
Tensor Parallelism 通过切 attention/mlp 层减少中间值
- attention (8��ℎ+5��2�)/�
- mlp 16��ℎ/�
- dropout/layernorm 6��ℎ (外层的不受影响,但 softmax dropout 也要切 t)
- attention/mlp input 2��ℎ+2��ℎ (f' 表示需要在 forward/backward 中需要 all reduce因此attn, mlp 输入也是完整的)
显存合计 ��ℎ(10+24�+5��ℎ�)
3-3 SP+TP 中间激活值
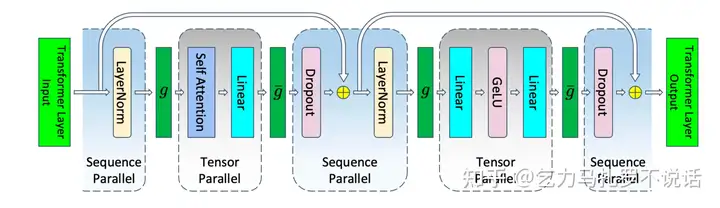
Sequence Parallelism 输入沿着 seq 维度切,从而进一步减少两个输入和 layernorm,dropout 的中间激活值
- attention (8��ℎ+5��2�)/� 不变
- mlp 16��ℎ/� 不变
- dropout/layernorm 6��ℎ/� 外层的 sequence parallel 也切 t 份
- attention/mlp input (2��ℎ+2��ℎ)/� ,外层g, g' 是 all-gather 操作
显存合计 ��ℎ�(34+5��ℎ)
3-4 PP+SP+TP 中间激活值
Pipeline Parallelism 没有减少
- 和 pp size 无关, 1F1B pp 同时有 L/p 个 microbatch,即便参数只有 L/p 这么多,但是激活状态需要整个 batch 全保留才能backward 时用
- Megatron 里 interleaving 如果开了需要存 �(1+(�−1)/��) 层的,m 为 interleaving stage
显存合计 ��ℎ��(34+5��ℎ)
3-5 总结
上述优化方案和组合方案优化后的中间激活值如下表

以 LLaMA 和 GPT 预估部分重算情况下模型显存和中间激活值比例
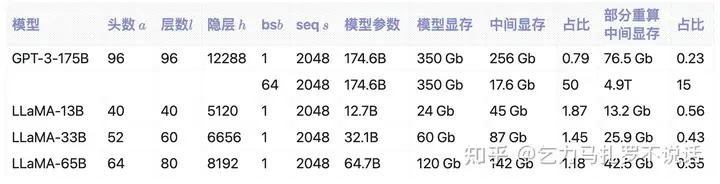
感兴趣也可以根据公式算全部方案下中间激活值节省。以下是博客:
4 推理过程
推理显存没有梯度和优化器,主要是模型参数,一般总显存经验值估算为 1.2 倍参数量
- 模型参数 fp16 下推理参数占 2Φ bytes
- KV Cache (如有) 缓存 KV Cache 加速方法
- 中间结果和输入数据 比较少,一般 20% 内
4-1 KV Cache 显存分析
KV Cache 是典型的推理加速方法,推理时缓存第 n 个 token 及前计算结果,第 n+1 个 token 相当于增量计算从而加速。
- 预填充阶段:输入一个 prompt 序列,为每个 transformer 层生成 key cache 和 value cache(KV cache) ()��⋅���(�) ,其中 ,��∈[�,���],��∈[ℎ,���],���∈[�,���,ℎ] 。这里是简化后的单头,多头时 ��∈[�,���,�,ℎ/�] 。
- 解码阶段:拼接并 concat 更新 KV cache,一个接一个地生成词,当前生成的词依赖于之前已经生成的词。假设输入序列的长度为 s ,输出序列的长度为 n ,最后一个token 推理时长度为 (s+n), KV Cache 占用峰值。
所以每层 2个K/V 各(s+n)bh ,每个 fp16 占 2 个 bytes,KV cache 的峰值显存占用大小为 �(�+�)ℎ∗�∗2∗2=4��ℎ(�+�)
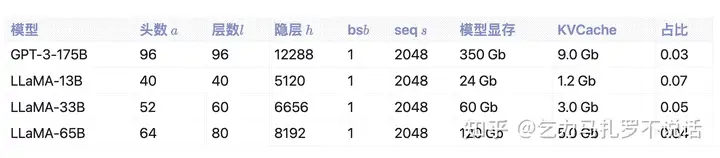
KV Cache 占模型显存比例
4-2 MQA & GQA
面向推理的显存(和速度)的优化主要是 Multi-Query Attention (MQA) 和 Group-Query Attention (GQA),本质上是通过多头共用 KV Cache 减少内存 I/O 时间占总时间比例。已经应用或支持的包括 ChatGLM2、LLaMA2、和 flash attention v2 解决方案。
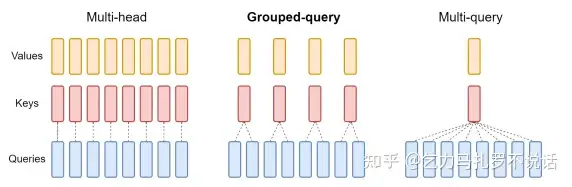
MHA(n:n) vs GQA(n/t : n) vs MQA(1:n)
这里显存的节省比较简单,如 MQA KV Cache 为原来的 1/n 倍,GQA 为原来的 1/������ 倍。主要是为了加速而不是显存优化提出的方法,推内存时间减少的比较值得一看。
5 参考
[1] Reducing activation recomputation in large transformer models
[2] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[3] Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelis
[4] https://arxiv.org/pdf/1911.02150.pdf
[5] https://arxiv.org/pdf/2305.13245.pdf
[6] OneFlow:手把手推导Ring All-reduce的数学性质

 浙公网安备 33010602011771号
浙公网安备 33010602011771号