
数据插入异常,原因是: (1054, "Unknown column '\ufeff95001' in 'field list'")
今天用python调用本地文本插入数据库时出现标题错误,多了个ufeff。
这涉及的编码知识和各编码之间的转换问题。
方法1:只需在后面加入decode
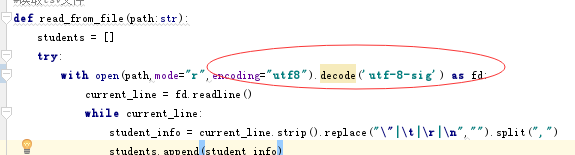
方法2:
用编辑器打开,选择相应编码
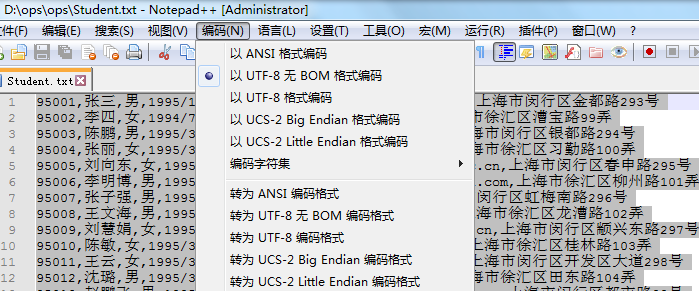
选择UTF-8无BOM编码格式
各编码相关基础知识
1. ANSCII:
标准的 ANSCII 编码只使用7个比特来表示一个字符,因此最多编码128个字符。扩充的 ANSCII 使用8个比特来表示一个字符,最多也只能
编码 256 个字符。
2. UNICODE:
使用2个甚至4个字节来编码一个字符,因此可以将世界上所有的字符进行统一编码。
3. UTF:
UNICODE编码转换格式,就是用来指导如何将 unicode 编码成适合文件存储和网络传输的字节序列的形式 (unicode ->
str)。像其他的一些编码方式 gb2312, gb18030, big5 和 UTF 的作用是一样的,只是编码方式不同。
4. 在Windows下用文本编辑器创建的文本文件,如果选择以UTF-8等Unicode格式保存,会在文件头(第一个字符)加入一个BOM标识。
什么是BOM?
BOM = Byte Order Mark
BOM是Unicode规范中推荐的标记字节顺序的方法。比如说对于UTF-16,如果接收者收到的BOM是FEFF,表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明“我是UTF-8编码”。BOM的UTF-8编码是EF BB BF(用UltraEdit打开文本、切换到16进制可以看到)。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号