
Redis缓存
(图片来源: https://www.cnblogs.com/rjzheng/p/8908073.html)
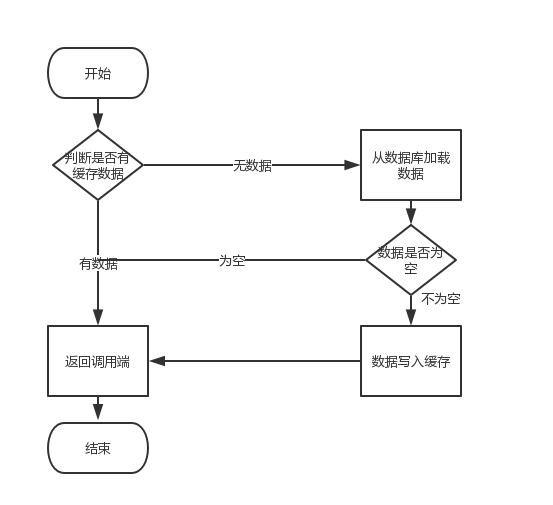
访问过程存在三种情况:
(1)请求 --> 缓存中存在key --> 返回 (2)请求 --> 缓存中不存在key --> 查询数据库 --> 数据库存在key --> 写入缓存 --> 返回 (3)请求 --> 缓存中不存在key --> 查询数据库 --> 数据库不存在key --> 返回
1. 为什么需要缓存?
假设没有缓存系统, 所有的请求都会直接连接数据库。 当访问量过大时,数据库必须过载无法连接,并且查询数据库是一个耗时操作。缓存可以减少数据库的查询次数,避免同时大量数据库连接操作。
2.访问存在三种情况,第一种和第二种是正常访问。在第三种情况下,访问时绕过了缓存直接连接缓存,完全是在消耗资源,如何避免这种情况?
如果缓存的目的是减少数据库连接,那么就不能让访问绕过缓存。
(1)加锁。当缓存中不存在key时,需要获取锁,获取锁的客户端可以访问数据库,没有获锁的用户等待。目的在于有顺序有组织的与数据库交互,避免数据库过载。例如:地铁在人流量很大的时候,会采取限流策略,让先来的人先进去。
请求 --> 缓存中不存在key --> 获取锁(令牌) --> 查询数据库 --> 返回
(2)先确认身份,再访问数据库。可以先在缓存中保存所有的key。当需要访问数据库时,先检查是否存在这个key,如果存在,再访问数据库。也就是,确认身份,vip可进。
请求 --> 缓存中不存在key --> 检测是否存在key -->(如果存在key) 查询数据库 --> 返回

 浙公网安备 33010602011771号
浙公网安备 33010602011771号