
xgboost的predict接口输出问题以及相关参数的探究(evals、evals_result、verbose_eval、pred_leaf、pred_contribs)、利用gbdt进行特征组合问题(gbdt+lr)
一、一直对xgboost的输出有些疑惑,这里记录一下
1.xgboost的predict接口输出问题(参数pred_leaf、pred_contribs)
2.训练过程中输出相关参数的探究(evals、evals_result、verbose_eval)
3.多分类内部原理探究(不涉及源码)
4.利用gbdt进行特征组合问题(gbdt+lr)
二、导入验证数据,验证问题
针对问题1
# 导入数据
import xgboost
from sklearn.datasets import load_iris(多分类), load_breast_cancer(二分类)
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.preprocessing import OneHotEncoder
# 多分类
iris_data = load_iris()
x = iris_data.data
y = iris_data.target # 类别0、1、2
dtrain = xgboost.DMatrix(data=x, label=y, weight=None, missing=None)
params = {
# General Parameters
'booster': 'gbtree'
# Booster Parameters
, 'eta': 0.3
, 'gamma': 0
, 'max_depth': 6
# Task Parameters
, 'objective': 'multi:softmax'
, 'num_class': 3
}
xgb_model = xgboost.train(params=params, dtrain=dtrain, num_boost_round=3)
## 1. 多分类 .predict()接口 直接输出float32类型的类别实数数组 [0. 0. 0. 0. 1. 2. 2 ]
res = xgb_model.predict(xgboost.DMatrix(data=x[:3]))
print(res)
# [0. 0. 0.]
## 2. 预测接口参数 pred_leaf 输出每个样本在所有树中的叶子节点
res = xgb_model.predict(xgboost.DMatrix(data=x), pred_leaf=True)[:3]
print(res)
# [[1. 1. 3. 1. 1. 3. 1. 1. 3.]
# [1. 1. 3. 1. 1. 3. 1. 1. 3.]
# [1. 1. 3. 1. 1. 3. 1. 1. 3.]]
# 3. 预测接口参数 pred_contribs 输出每个样本各个特征的贡献度
res = xgb_model.predict(xgboost.DMatrix(data=x[0].reshape(1,-1)), pred_contribs=True)
print(res) # 鸢尾花数据集共四个特征,输出4个特征重要性,外加最后一列bias,为啥输出3行,问题三解决
'''
[[[ 0. 0. 0.96979856 0. 0.49221304]
[ 0.00316561 0.00255702 -0.7801311 0.19311588 0.4988653 ]
[ 0. 0. -0.31247163 -0.2724296 0.48901463]]]'''
## 4. 导出迭代过程逻辑, xgboost 为每一个类别,建立一组树,树的个数等于num_class * num_boost_round
xgb_model.dump_model('model.txt')
'''
booster[0]:
0:[f2<2.45000005] yes=1,no=2,missing=1
1:leaf=0.430622011
2:leaf=-0.220048919
booster[1]:
0:[f2<2.45000005] yes=1,no=2,missing=1
1:leaf=-0.215311036
2:[f3<1.75] yes=3,no=4,missing=3
3:[f2<4.94999981] yes=5,no=6,missing=5
5:[f3<1.54999995] yes=9,no=10,missing=9
9:leaf=0.428571463
10:leaf=0.128571421
6:[f3<1.54999995] yes=11,no=12,missing=11
11:leaf=-0.128571451
12:leaf=0.128571421
4:[f2<4.85000038] yes=7,no=8,missing=7
7:leaf=-7.66345476e-09
8:leaf=-0.213812172
...... 共9棵树= 类别数*训练轮数
'''
## 5. xgboost可视化输出,如下图
graph = xgboost.to_graphviz(xgb_model, num_trees=0) # 指定第num_tree输出图像
graph.format = 'png'
graph.view('./xgb_tree')
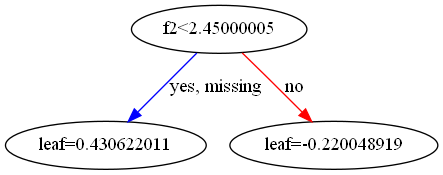
针对问题2:
# 二分类问题
breast_cancer_data = load_breast_cancer()
x = breast_cancer_data.data
y = breast_cancer_data.target # 类别 0,1
# 1. xgboost原接口训练方式
dtrain = xgboost.DMatrix(data=x, label=y, weight=None, missing=None)
validx = xgboost.DMatrix(data=x[:100], label=y[:100], weight=None, missing=None)
params = {
# General Parameters
'booster': 'gbtree'
# Booster Parameters
, 'eta': 0.3
, 'gamma': 0
, 'max_depth': 6
# Task Parameters
, 'objective': 'binary:logistic'
, 'eval_metric': 'logloss'
}
res = {}
xgb_model = xgboost.train(params=params, dtrain=dtrain, num_boost_round=10,
evals=[(dtrain, 'dtrain'), (validx, 'validx')], # 训练过程中验证集
evals_result=res, # 保存训练过程中的验证集的结果
verbose_eval=2 # 每隔几轮,窗口打印训练过程中的
)
## 针对 verbose_eval参数,训练过程中,打印验证集的结果,便于调试
# [0] dtrain-logloss:0.46043 validx-logloss:0.47871
# [2] dtrain-logloss:0.24233 validx-logloss:0.26559
# [4] dtrain-logloss:0.14270 validx-logloss:0.16211
# [6] dtrain-logloss:0.08949 validx-logloss:0.10722
# [8] dtrain-logloss:0.06163 validx-logloss:0.07396
# [9] dtrain-logloss:0.05215 validx-logloss:0.06349
## 针对 evals_result参数,保存训练结果,用于记录训练过程
print(f'训练过程中evals参数中验证集每轮评估效果:\n{res}')
# 训练过程中evals参数中验证集每轮评估效果:
# {'dtrain': OrderedDict([('logloss', [0.460426, 0.327564, 0.24233, 0.18487, 0.142699, 0.11199, 0.089492, 0.074096, 0.061629, 0.052155])]),
# 'validx': OrderedDict([('logloss', [0.47871, 0.345854, 0.265594, 0.208941, 0.16211, 0.133699, 0.107224, 0.089368, 0.073962, 0.063492])])}
## 二分类输出结果*(不是输出0、1目标分类,而是输出类似logisticregressor的几率或概率)
print(f'predict接口输出形式:{xgb_model.predict(dtrain)[:3]}')
# predict接口输出形式:[0.07583217 0.02762461 0.02571429]
#2. xgboost 中sklraen形式的接口
xgb = xgboost.XGBClassifier()
xgb.fit(x, y)
print(f'此时predict接口直接输出预测类别{xgb.predict(x[:3])}')
print(f'此时predict_proba接口直接输出预测概率{xgb.predict_proba(x[:3])}')
针对问题三
# 根据问题1,得到的训练迭代过程model.txt和样本所在叶子节点,
# 1.对第一个样本类别为0,叶子节点[[1. 1. 3. 1. 1. 3. 1. 1. 3.],计算每棵树的结果
'''
[[ 第1棵树 0.43 第2棵树 0.215 第3棵树 -0.219]
[ 第4棵树 0.29 第5棵树 0.191 第6棵树 -0.195]
[ 第7棵树 0.236 第8棵树 -0.175 第9棵树 -0.18 ]]
'''
# 2.针对最后一个样本类别2,叶子节点[[2. 8. 2. 2. 8. 10. 2. 8. 10.]]]
'''
[[ 第1棵树 -0.22 第2棵树 -0.213 第3棵树 0.402]
[ 第4棵树 -0.196 第5棵树 -0.191 第6棵树 0.297]
[ 第7棵树 -0.181 第8棵树 -0.174 第9棵树 0.237]]
'''
# 3.对类别为0的样本和类别为2的样本,对树表垂直方向上求sum
'''
类别为0的样本 sum = [0.956 0.231 -0.594] 经过softmax [0.5894, 0.2855, 0.1251] ≈ [1,0,0]
类别为2的样本 sum = [-0.597 -0.578 0.936] 经过softmax [0.1503, 0.1532, 0.6964] ≈ [0,0,1]
一般原理上经过softmax,实际代码上直接求取sum里最大值对应的类别
'''
# 4.结论:
'''
xgb针对多分类是采用的多个二分类实现的(本类为1,其他类为0),所以参数num_boost_round=3,却出现9棵树,每个类别训练了一次(源码我并未验证)
'''
针对问题四
# 使用xgbt进行特征的非线性组合(+可配合lr使用)
res = xgb_model.predict(xgboost.DMatrix(data=x), pred_leaf=True)
onehot = OneHotEncoder()
res = onehot.fit_transform(res).toarray()
print(res.shape) # (150, 42) 鸢尾花数据集150样本*9棵树一共42个叶子节点
'''
[[1. 0. 1. ... 0. 0. 0.]
[1. 0. 1. ... 0. 0. 0.]
[1. 0. 1. ... 0. 0. 0.]
...
[0. 1. 0. ... 0. 0. 1.]
[0. 1. 0. ... 0. 0. 1.]
[0. 1. 0. ... 0. 0. 1.]]
'''

