jupyterhub(多用户平台) 安装配置、安装问题解决、用户验证问题
jupyterhub 安装、安装问题解决、用户验证问题
一,基础环境
腾讯云centos7 + anaconda3(python3.8.8)
注意:最好是带有网的环境,不带外网的电脑离线安装jupyterhub安装很费劲,github源码、whl等均失败。
二,下载软件
-
安装jupyterhub
pip install jupyterhub -i XXX 有网可以使用清华源/没网找自己公司镜像源注意:使用conda安装会很慢,偶尔会失败,不知道为什么,目前自动安装jupyterhub1.5.0,切记版本不同,后面配置参数有很大区别,不要看见别人博客的参数设置,就自己copy使用,不要问我为什么知道,都是泪。
-
安装nodejs
# 是否sudo 自己决定 sudo yum install nodejs sudo npm install -g configurable-http-proxy(jupyterhub默认代理) -
测试软件
jupyterhub -h configurable-http-proxy -h # 不报错就OK,报错有和我一样的错误的看下面的错误解决,不一样就只能看百度 -
启动服务
# 生成配置文件 jupyterhub --generate-config # 应该生成在当前文件夹下, # 服务启动 -- 启动时注意自己配置文件的位置 /etc下行,不是root,在/home下也行 jupyterhub -f=/etc/jupyterhub/jupyterhub_config.py --no-ssl # 后台服务启动 nohup jupyterhub -f=/etc/jupyterhub/jupyterhub_config.py --no-ssl >> xxx.log 2>&1 &
三,准备配置文件
** 注意: 接下来的配置参数是符合jupyterhub 1.5.0 版本的,不同版本有所区别,想要准确参数去查对应版 本官方文档 https://jupyterhub.readthedocs.io/en/stable/ 这是jupyterhub 1.5.0
# ------------------------------------------------------------------------------
# 这只是我目前测试的配置,并不适合所用人
# ------------------------------------------------------------------------------
# 设置每个用户的 book类型 和 工作目录(创建.ipynb文件自动保存的地方)
c.Spawner.notebook_dir = '~'
c.Spawner.default_url = '/lab'
c.Spawner.args = ['--allow-root']
# configurable_http_proxy 代理设置
c.ConfigurableHTTPProxy.should_start = True #允许hub启动代理 可以不写,默认的,为False 就需要自己去 启动configurable-http-proxy
c.ConfigurableHTTPProxy.api_url = 'http://localhost:8001' # proxy与hub与代理通讯,这应该是默认值不行也行
# 对外登录设置的ip
c.JupyterHub.ip = '0.0.0.0'
c.JupyterHub.port = 80
c.PAMAuthenticator.encoding = 'utf8'
# 其他设置 cookie file and sqlite file,这个写着了,不写我没试有啥影响
c.JupyterHub.cookie_secret_file = '/etc/jupyterhub/jupyterhub_cookie_secret'
c.JupyterHub.db_url = '/etc/jupyterhub/jupyterhub.sqlite'
c.JupyterHub.pid_file = '/etc/jupyterhub/jupyterhub.pid'
# 用户名单设置,默认身份验证方式PAM与NUIX系统用户管理层一致,root用户可以添加用户test1,test2等等,非root用户,sudo useradd test1/test2 不起作用,目前我不知道sudo useradd 和 root下 useradd本质区别*(没有特意学过linux,一切只靠用时百度)
c.Authenticator.allowed_users = ['test1','test2']
c.Authenticator.admin_users = {'root'}
### 如果没有root权限,公司服务器,员工一般都没有,可以先设置下面两句进行测试,允许任何用户和密码登录,若想自己设置身份验证,也可以自己修改 PAMAuthenticator和SimpleLocalProcessSpawner这两个类,这两个类代码特简单,代码放到文章下面
c.JupyterHub.authenticator_class = 'jupyterhub.auth.DummyAuthenticator'
c.JupyterHub.spawner_class = 'jupyterhub.spawner.SimpleLocalProcessSpawner'
# 如上面不好使,请 pip install jupyterhub-dummyauthenticator
# pip install jupyterhub-simplelocalprocessspawner
# 应该jupyterhub 安装时就自带了这两个类 就在jupyterhub安装目录下,auth.py和spawner.py文件里
# 为jupyterhub 添加额外服务,用于处理闲置用户进程。使用时不好使安装一下:pip install jupyterhub-ilde-culler
c.JupyterHub.services = [
{
'name': 'idle-culler',
'command': ['python3', '-m', 'jupyterhub_idle_culler', '--timeout=3600'],
'admin':True # 1.5.0 需要服务管理员权限,去kill 部分闲置的进程notebook, 2.0版本已经改了,可以只赋给 idel-culler 部分特定权限,roles
}
]
四,安装时报错解决
-
configurable-http-proxy 安装不报错,测试 configurable-http-proxy -h 报错(安装中,我就一个安装错误,)错误图公司服务器就没有截屏(提示的 "unexpect indentifier ")
解决:应该时nodejs 版本问题,默认下载的时6.17.1吧,升级一下版本就好了
(1)如果时云服务器(有网),
npm install -g n n table(生成到稳定版) n latest(升级到最新版)(2) 公司服务器(没外网),就下载安装包离线安装
nodejs官网 https://nodejs.org/dist/ 找到自己需要的node版本,下载后上传到linux. 解压 tar -zxvf node-v1xxx.tar.gz 配置软连接 ln -s /文件路径/node-v1.xxx/bin/node /usr/local/bin ln -s /文件路径/node-v1.xxx/bin/npm /usr/local/bin 执行 node -v 命令看是否可用 -
jupyterhub command not found 或 服务启动报错 no file or dir "jupyterhub-singleuser" 等问题
解决:有时候安装完,jupyterhub 和插件 没有自动创建软连接,需要自己创建
```shell
ln -s /xx/anaconda3/bin/jupyterhub /usr/local/bin
ln -s /xx/anaconda3/bin/jupyterlab /usr/local/bin
ln -s /xx/anaconda3/bin/jupyterhub-singleuser /usr/local/bin
```
-
启动中端口占用问题,如下图
![]()
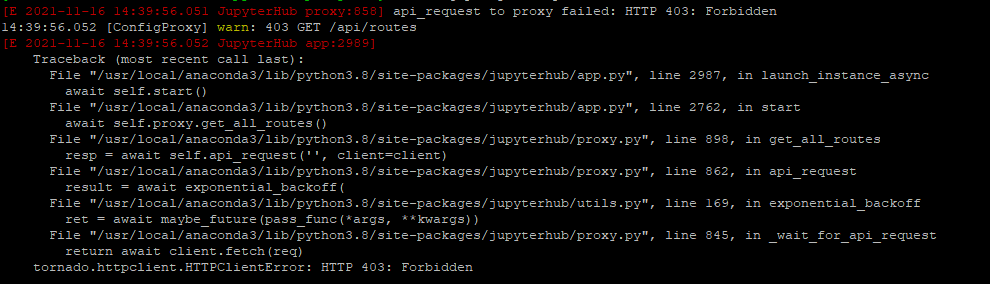
解决:Jupyterhub 启动服务时,会使用好几个端口,服务意外停止时,有的端口未关闭,关闭端口
```shell
# 查看端口
lsof -i:80
lsof -i:8001
lsof -i:8081
# 关闭对应端口进程
kill -9 xxx(pid)
```
- 身份验证问题,(没有root权限,sudo useradd 创建的用户不好使)如图
![]()
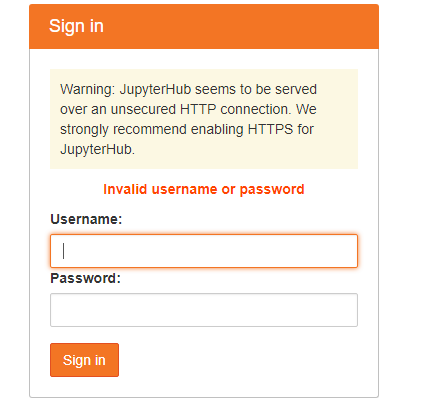
解决 1. 使用dummpyauthenticator 不建立验证
2. 自己使用sqlite 或mysql 创建用户表,修改源码进行验证(这个我还没写,下一步写)
-
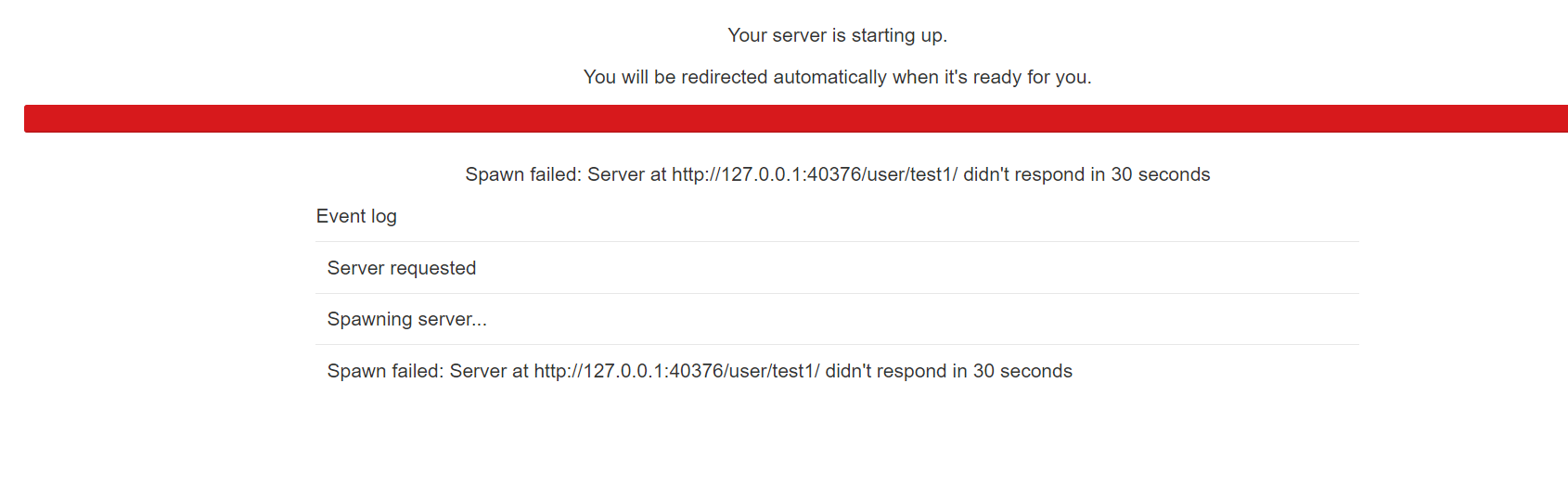
使用自定义身份验证类和自定义spawner类时,能登陆但生不成singlejupyter进程问题,如下图:
![]()
解决:# 配置文件添加(不保证肯定解决此类问题,文件夹权限问题也可能导致此类问题) c.Spawner.args = ['--allow-root'] -
其他问题 。。。想不起来了
五,配置参数、jupyterhub命令、身份验证代码附录
-
所有配置参数附录
下面附上1.5.0版本 所有的配置参数 和juputerhub 命令的参数, 按照自己想要的参数,去查找 #------- Configuration file for jupyterhub. #------------------------------------------------------------------------------ # Application(SingletonConfigurable) configuration #------------------------------------------------------------------------------ ## This is an application. ## The date format used by logging formatters for %(asctime)s # Default: '%Y-%m-%d %H:%M:%S' # c.Application.log_datefmt = '%Y-%m-%d %H:%M:%S' ## The Logging format template # Default: '[%(name)s]%(highlevel)s %(message)s' # c.Application.log_format = '[%(name)s]%(highlevel)s %(message)s' ## Set the log level by value or name. # Choices: any of [0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL'] # Default: 30 # c.Application.log_level = 30 ## Instead of starting the Application, dump configuration to stdout # Default: False # c.Application.show_config = False ## Instead of starting the Application, dump configuration to stdout (as JSON) # Default: False # c.Application.show_config_json = False #------------------------------------------------------------------------------ # JupyterHub(Application) configuration #------------------------------------------------------------------------------ ## An Application for starting a Multi-User Jupyter Notebook server. ## Maximum number of concurrent servers that can be active at a time. # # Setting this can limit the total resources your users can consume. # # An active server is any server that's not fully stopped. It is considered # active from the time it has been requested until the time that it has # completely stopped. # # If this many user servers are active, users will not be able to launch new # servers until a server is shutdown. Spawn requests will be rejected with a 429 # error asking them to try again. # # If set to 0, no limit is enforced. # Default: 0 # c.JupyterHub.active_server_limit = 0 ## Duration (in seconds) to determine the number of active users. # Default: 1800 # c.JupyterHub.active_user_window = 1800 ## Resolution (in seconds) for updating activity # # If activity is registered that is less than activity_resolution seconds more # recent than the current value, the new value will be ignored. # # This avoids too many writes to the Hub database. # Default: 30 # c.JupyterHub.activity_resolution = 30 ## Grant admin users permission to access single-user servers. # # Users should be properly informed if this is enabled. # Default: False # c.JupyterHub.admin_access = False ## DEPRECATED since version 0.7.2, use Authenticator.admin_users instead. # Default: set() # c.JupyterHub.admin_users = set() ## Allow named single-user servers per user # Default: False # c.JupyterHub.allow_named_servers = False ## Answer yes to any questions (e.g. confirm overwrite) # Default: False # c.JupyterHub.answer_yes = False ## PENDING DEPRECATION: consider using services # # Dict of token:username to be loaded into the database. # # Allows ahead-of-time generation of API tokens for use by externally managed services, # which authenticate as JupyterHub users. # # Consider using services for general services that talk to the # JupyterHub API. # Default: {} # c.JupyterHub.api_tokens = {} ## Authentication for prometheus metrics # Default: True # c.JupyterHub.authenticate_prometheus = True ## Class for authenticating users. # # This should be a subclass of :class:`jupyterhub.auth.Authenticator` # # with an :meth:`authenticate` method that: # # - is a coroutine (asyncio or tornado) # - returns username on success, None on failure # - takes two arguments: (handler, data), # where `handler` is the calling web.RequestHandler, # and `data` is the POST form data from the login page. # # .. versionchanged:: 1.0 # authenticators may be registered via entry points, # e.g. `c.JupyterHub.authenticator_class = 'pam'` # # Currently installed: # - default: jupyterhub.auth.PAMAuthenticator # - dummy: jupyterhub.auth.DummyAuthenticator # - pam: jupyterhub.auth.PAMAuthenticator # Default: 'jupyterhub.auth.PAMAuthenticator' # c.JupyterHub.authenticator_class = 'jupyterhub.auth.PAMAuthenticator' ## The base URL of the entire application. # # Add this to the beginning of all JupyterHub URLs. # Use base_url to run JupyterHub within an existing website. # # .. deprecated: 0.9 # Use JupyterHub.bind_url # Default: '/' # c.JupyterHub.base_url = '/' ## The public facing URL of the whole JupyterHub application. # # This is the address on which the proxy will bind. # Sets protocol, ip, base_url # Default: 'http://:8000' # c.JupyterHub.bind_url = 'http://:8000' ## Whether to shutdown the proxy when the Hub shuts down. # # Disable if you want to be able to teardown the Hub while leaving the # proxy running. # # Only valid if the proxy was starting by the Hub process. # # If both this and cleanup_servers are False, sending SIGINT to the Hub will # only shutdown the Hub, leaving everything else running. # # The Hub should be able to resume from database state. # Default: True # c.JupyterHub.cleanup_proxy = True ## Whether to shutdown single-user servers when the Hub shuts down. # # Disable if you want to be able to teardown the Hub while leaving the # single-user servers running. # # If both this and cleanup_proxy are False, sending SIGINT to the Hub will # only shutdown the Hub, leaving everything else running. # # The Hub should be able to resume from database state. # Default: True # c.JupyterHub.cleanup_servers = True ## Maximum number of concurrent users that can be spawning at a time. # # Spawning lots of servers at the same time can cause performance problems for # the Hub or the underlying spawning system. Set this limit to prevent bursts of # logins from attempting to spawn too many servers at the same time. # # This does not limit the number of total running servers. See # active_server_limit for that. # # If more than this many users attempt to spawn at a time, their requests will # be rejected with a 429 error asking them to try again. Users will have to wait # for some of the spawning services to finish starting before they can start # their own. # # If set to 0, no limit is enforced. # Default: 100 # c.JupyterHub.concurrent_spawn_limit = 100 ## The config file to load # Default: 'jupyterhub_config.py' # c.JupyterHub.config_file = 'jupyterhub_config.py' ## DEPRECATED: does nothing # Default: False # c.JupyterHub.confirm_no_ssl = False ## Number of days for a login cookie to be valid. # Default is two weeks. # Default: 14 # c.JupyterHub.cookie_max_age_days = 14 ## The cookie secret to use to encrypt cookies. # # Loaded from the JPY_COOKIE_SECRET env variable by default. # # Should be exactly 256 bits (32 bytes). # Default: traitlets.Undefined # c.JupyterHub.cookie_secret = traitlets.Undefined ## File in which to store the cookie secret. # Default: 'jupyterhub_cookie_secret' # c.JupyterHub.cookie_secret_file = 'jupyterhub_cookie_secret' ## The location of jupyterhub data files (e.g. /usr/local/share/jupyterhub) # Default: '$HOME/checkouts/readthedocs.org/user_builds/jupyterhub/checkouts/stable/share/jupyterhub' # c.JupyterHub.data_files_path = '/home/docs/checkouts/readthedocs.org/user_builds/jupyterhub/checkouts/stable/share/jupyterhub' ## Include any kwargs to pass to the database connection. # See sqlalchemy.create_engine for details. # Default: {} # c.JupyterHub.db_kwargs = {} ## url for the database. e.g. `sqlite:///jupyterhub.sqlite` # Default: 'sqlite:///jupyterhub.sqlite' # c.JupyterHub.db_url = 'sqlite:///jupyterhub.sqlite' ## log all database transactions. This has A LOT of output # Default: False # c.JupyterHub.debug_db = False ## DEPRECATED since version 0.8: Use ConfigurableHTTPProxy.debug # Default: False # c.JupyterHub.debug_proxy = False ## If named servers are enabled, default name of server to spawn or open, e.g. by # user-redirect. # Default: '' # c.JupyterHub.default_server_name = '' ## The default URL for users when they arrive (e.g. when user directs to "/") # # By default, redirects users to their own server. # # Can be a Unicode string (e.g. '/hub/home') or a callable based on the handler # object: # # :: # # def default_url_fn(handler): # user = handler.current_user # if user and user.admin: # return '/hub/admin' # return '/hub/home' # # c.JupyterHub.default_url = default_url_fn # Default: traitlets.Undefined # c.JupyterHub.default_url = traitlets.Undefined ## Dict authority:dict(files). Specify the key, cert, and/or # ca file for an authority. This is useful for externally managed # proxies that wish to use internal_ssl. # # The files dict has this format (you must specify at least a cert):: # # { # 'key': '/path/to/key.key', # 'cert': '/path/to/cert.crt', # 'ca': '/path/to/ca.crt' # } # # The authorities you can override: 'hub-ca', 'notebooks-ca', # 'proxy-api-ca', 'proxy-client-ca', and 'services-ca'. # # Use with internal_ssl # Default: {} # c.JupyterHub.external_ssl_authorities = {} ## Register extra tornado Handlers for jupyterhub. # # Should be of the form ``("<regex>", Handler)`` # # The Hub prefix will be added, so `/my-page` will be served at `/hub/my-page`. # Default: [] # c.JupyterHub.extra_handlers = [] ## DEPRECATED: use output redirection instead, e.g. # # jupyterhub &>> /var/log/jupyterhub.log # Default: '' # c.JupyterHub.extra_log_file = '' ## Extra log handlers to set on JupyterHub logger # Default: [] # c.JupyterHub.extra_log_handlers = [] ## Generate certs used for internal ssl # Default: False # c.JupyterHub.generate_certs = False ## Generate default config file # Default: False # c.JupyterHub.generate_config = False ## The URL on which the Hub will listen. This is a private URL for internal # communication. Typically set in combination with hub_connect_url. If a unix # socket, hub_connect_url **must** also be set. # # For example: # # "http://127.0.0.1:8081" # "unix+http://%2Fsrv%2Fjupyterhub%2Fjupyterhub.sock" # # .. versionadded:: 0.9 # Default: '' # c.JupyterHub.hub_bind_url = '' ## The ip or hostname for proxies and spawners to use # for connecting to the Hub. # # Use when the bind address (`hub_ip`) is 0.0.0.0, :: or otherwise different # from the connect address. # # Default: when `hub_ip` is 0.0.0.0 or ::, use `socket.gethostname()`, # otherwise use `hub_ip`. # # Note: Some spawners or proxy implementations might not support hostnames. Check your # spawner or proxy documentation to see if they have extra requirements. # # .. versionadded:: 0.8 # Default: '' # c.JupyterHub.hub_connect_ip = '' ## DEPRECATED # # Use hub_connect_url # # .. versionadded:: 0.8 # # .. deprecated:: 0.9 # Use hub_connect_url # Default: 0 # c.JupyterHub.hub_connect_port = 0 ## The URL for connecting to the Hub. Spawners, services, and the proxy will use # this URL to talk to the Hub. # # Only needs to be specified if the default hub URL is not connectable (e.g. # using a unix+http:// bind url). # # .. seealso:: # JupyterHub.hub_connect_ip # JupyterHub.hub_bind_url # # .. versionadded:: 0.9 # Default: '' # c.JupyterHub.hub_connect_url = '' ## The ip address for the Hub process to *bind* to. # # By default, the hub listens on localhost only. This address must be accessible from # the proxy and user servers. You may need to set this to a public ip or '' for all # interfaces if the proxy or user servers are in containers or on a different host. # # See `hub_connect_ip` for cases where the bind and connect address should differ, # or `hub_bind_url` for setting the full bind URL. # Default: '127.0.0.1' # c.JupyterHub.hub_ip = '127.0.0.1' ## The internal port for the Hub process. # # This is the internal port of the hub itself. It should never be accessed directly. # See JupyterHub.port for the public port to use when accessing jupyterhub. # It is rare that this port should be set except in cases of port conflict. # # See also `hub_ip` for the ip and `hub_bind_url` for setting the full # bind URL. # Default: 8081 # c.JupyterHub.hub_port = 8081 ## The routing prefix for the Hub itself. # # Override to send only a subset of traffic to the Hub. Default is to use the # Hub as the default route for all requests. # # This is necessary for normal jupyterhub operation, as the Hub must receive # requests for e.g. `/user/:name` when the user's server is not running. # # However, some deployments using only the JupyterHub API may want to handle # these events themselves, in which case they can register their own default # target with the proxy and set e.g. `hub_routespec = /hub/` to serve only the # hub's own pages, or even `/hub/api/` for api-only operation. # # Note: hub_routespec must include the base_url, if any. # # .. versionadded:: 1.4 # Default: '/' # c.JupyterHub.hub_routespec = '/' ## Trigger implicit spawns after this many seconds. # # When a user visits a URL for a server that's not running, # they are shown a page indicating that the requested server # is not running with a button to spawn the server. # # Setting this to a positive value will redirect the user # after this many seconds, effectively clicking this button # automatically for the users, # automatically beginning the spawn process. # # Warning: this can result in errors and surprising behavior # when sharing access URLs to actual servers, # since the wrong server is likely to be started. # Default: 0 # c.JupyterHub.implicit_spawn_seconds = 0 ## Timeout (in seconds) to wait for spawners to initialize # # Checking if spawners are healthy can take a long time if many spawners are # active at hub start time. # # If it takes longer than this timeout to check, init_spawner will be left to # complete in the background and the http server is allowed to start. # # A timeout of -1 means wait forever, which can mean a slow startup of the Hub # but ensures that the Hub is fully consistent by the time it starts responding # to requests. This matches the behavior of jupyterhub 1.0. # # .. versionadded: 1.1.0 # Default: 10 # c.JupyterHub.init_spawners_timeout = 10 ## The location to store certificates automatically created by # JupyterHub. # # Use with internal_ssl # Default: 'internal-ssl' # c.JupyterHub.internal_certs_location = 'internal-ssl' ## Enable SSL for all internal communication # # This enables end-to-end encryption between all JupyterHub components. # JupyterHub will automatically create the necessary certificate # authority and sign notebook certificates as they're created. # Default: False # c.JupyterHub.internal_ssl = False ## The public facing ip of the whole JupyterHub application # (specifically referred to as the proxy). # # This is the address on which the proxy will listen. The default is to # listen on all interfaces. This is the only address through which JupyterHub # should be accessed by users. # # .. deprecated: 0.9 # Use JupyterHub.bind_url # Default: '' # c.JupyterHub.ip = '' ## Supply extra arguments that will be passed to Jinja environment. # Default: {} # c.JupyterHub.jinja_environment_options = {} ## Interval (in seconds) at which to update last-activity timestamps. # Default: 300 # c.JupyterHub.last_activity_interval = 300 ## Dict of 'group': ['usernames'] to load at startup. # # This strictly *adds* groups and users to groups. # # Loading one set of groups, then starting JupyterHub again with a different # set will not remove users or groups from previous launches. # That must be done through the API. # Default: {} # c.JupyterHub.load_groups = {} ## The date format used by logging formatters for %(asctime)s # See also: Application.log_datefmt # c.JupyterHub.log_datefmt = '%Y-%m-%d %H:%M:%S' ## The Logging format template # See also: Application.log_format # c.JupyterHub.log_format = '[%(name)s]%(highlevel)s %(message)s' ## Set the log level by value or name. # See also: Application.log_level # c.JupyterHub.log_level = 30 ## Specify path to a logo image to override the Jupyter logo in the banner. # Default: '' # c.JupyterHub.logo_file = '' ## Maximum number of concurrent named servers that can be created by a user at a # time. # # Setting this can limit the total resources a user can consume. # # If set to 0, no limit is enforced. # Default: 0 # c.JupyterHub.named_server_limit_per_user = 0 ## Expiry (in seconds) of OAuth access tokens. # # The default is to expire when the cookie storing them expires, # according to `cookie_max_age_days` config. # # These are the tokens stored in cookies when you visit # a single-user server or service. # When they expire, you must re-authenticate with the Hub, # even if your Hub authentication is still valid. # If your Hub authentication is valid, # logging in may be a transparent redirect as you refresh the page. # # This does not affect JupyterHub API tokens in general, # which do not expire by default. # Only tokens issued during the oauth flow # accessing services and single-user servers are affected. # # .. versionadded:: 1.4 # OAuth token expires_in was not previously configurable. # .. versionchanged:: 1.4 # Default now uses cookie_max_age_days so that oauth tokens # which are generally stored in cookies, # expire when the cookies storing them expire. # Previously, it was one hour. # Default: 0 # c.JupyterHub.oauth_token_expires_in = 0 ## File to write PID # Useful for daemonizing JupyterHub. # Default: '' # c.JupyterHub.pid_file = '' ## The public facing port of the proxy. # # This is the port on which the proxy will listen. # This is the only port through which JupyterHub # should be accessed by users. # # .. deprecated: 0.9 # Use JupyterHub.bind_url # Default: 8000 # c.JupyterHub.port = 8000 ## DEPRECATED since version 0.8 : Use ConfigurableHTTPProxy.api_url # Default: '' # c.JupyterHub.proxy_api_ip = '' ## DEPRECATED since version 0.8 : Use ConfigurableHTTPProxy.api_url # Default: 0 # c.JupyterHub.proxy_api_port = 0 ## DEPRECATED since version 0.8: Use ConfigurableHTTPProxy.auth_token # Default: '' # c.JupyterHub.proxy_auth_token = '' ## DEPRECATED since version 0.8: Use ConfigurableHTTPProxy.check_running_interval # Default: 5 # c.JupyterHub.proxy_check_interval = 5 ## The class to use for configuring the JupyterHub proxy. # # Should be a subclass of :class:`jupyterhub.proxy.Proxy`. # # .. versionchanged:: 1.0 # proxies may be registered via entry points, # e.g. `c.JupyterHub.proxy_class = 'traefik'` # # Currently installed: # - configurable-http-proxy: jupyterhub.proxy.ConfigurableHTTPProxy # - default: jupyterhub.proxy.ConfigurableHTTPProxy # Default: 'jupyterhub.proxy.ConfigurableHTTPProxy' # c.JupyterHub.proxy_class = 'jupyterhub.proxy.ConfigurableHTTPProxy' ## DEPRECATED since version 0.8. Use ConfigurableHTTPProxy.command # Default: [] # c.JupyterHub.proxy_cmd = [] ## Recreate all certificates used within JupyterHub on restart. # # Note: enabling this feature requires restarting all notebook servers. # # Use with internal_ssl # Default: False # c.JupyterHub.recreate_internal_certs = False ## Redirect user to server (if running), instead of control panel. # Default: True # c.JupyterHub.redirect_to_server = True ## Purge and reset the database. # Default: False # c.JupyterHub.reset_db = False ## Interval (in seconds) at which to check connectivity of services with web # endpoints. # Default: 60 # c.JupyterHub.service_check_interval = 60 ## Dict of token:servicename to be loaded into the database. # # Allows ahead-of-time generation of API tokens for use by externally # managed services. # Default: {} # c.JupyterHub.service_tokens = {} ## List of service specification dictionaries. # # A service # # For instance:: # # services = [ # { # 'name': 'cull_idle', # 'command': ['/path/to/cull_idle_servers.py'], # }, # { # 'name': 'formgrader', # 'url': 'http://127.0.0.1:1234', # 'api_token': 'super-secret', # 'environment': # } # ] # Default: [] # c.JupyterHub.services = [] ## Instead of starting the Application, dump configuration to stdout # See also: Application.show_config # c.JupyterHub.show_config = False ## Instead of starting the Application, dump configuration to stdout (as JSON) # See also: Application.show_config_json # c.JupyterHub.show_config_json = False ## Shuts down all user servers on logout # Default: False # c.JupyterHub.shutdown_on_logout = False ## The class to use for spawning single-user servers. # # Should be a subclass of :class:`jupyterhub.spawner.Spawner`. # # .. versionchanged:: 1.0 # spawners may be registered via entry points, # e.g. `c.JupyterHub.spawner_class = 'localprocess'` # # Currently installed: # - default: jupyterhub.spawner.LocalProcessSpawner # - localprocess: jupyterhub.spawner.LocalProcessSpawner # - simple: jupyterhub.spawner.SimpleLocalProcessSpawner # Default: 'jupyterhub.spawner.LocalProcessSpawner' # c.JupyterHub.spawner_class = 'jupyterhub.spawner.LocalProcessSpawner' ## Path to SSL certificate file for the public facing interface of the proxy # # When setting this, you should also set ssl_key # Default: '' # c.JupyterHub.ssl_cert = '' ## Path to SSL key file for the public facing interface of the proxy # # When setting this, you should also set ssl_cert # Default: '' # c.JupyterHub.ssl_key = '' ## Host to send statsd metrics to. An empty string (the default) disables sending # metrics. # Default: '' # c.JupyterHub.statsd_host = '' ## Port on which to send statsd metrics about the hub # Default: 8125 # c.JupyterHub.statsd_port = 8125 ## Prefix to use for all metrics sent by jupyterhub to statsd # Default: 'jupyterhub' # c.JupyterHub.statsd_prefix = 'jupyterhub' ## Run single-user servers on subdomains of this host. # # This should be the full `https://hub.domain.tld[:port]`. # # Provides additional cross-site protections for javascript served by # single-user servers. # # Requires `<username>.hub.domain.tld` to resolve to the same host as # `hub.domain.tld`. # # In general, this is most easily achieved with wildcard DNS. # # When using SSL (i.e. always) this also requires a wildcard SSL # certificate. # Default: '' # c.JupyterHub.subdomain_host = '' ## Paths to search for jinja templates, before using the default templates. # Default: [] # c.JupyterHub.template_paths = [] ## Extra variables to be passed into jinja templates # Default: {} # c.JupyterHub.template_vars = {} ## Extra settings overrides to pass to the tornado application. # Default: {} # c.JupyterHub.tornado_settings = {} ## Trust user-provided tokens (via JupyterHub.service_tokens) # to have good entropy. # # If you are not inserting additional tokens via configuration file, # this flag has no effect. # # In JupyterHub 0.8, internally generated tokens do not # pass through additional hashing because the hashing is costly # and does not increase the entropy of already-good UUIDs. # # User-provided tokens, on the other hand, are not trusted to have good entropy by default, # and are passed through many rounds of hashing to stretch the entropy of the key # (i.e. user-provided tokens are treated as passwords instead of random keys). # These keys are more costly to check. # # If your inserted tokens are generated by a good-quality mechanism, # e.g. `openssl rand -hex 32`, then you can set this flag to True # to reduce the cost of checking authentication tokens. # Default: False # c.JupyterHub.trust_user_provided_tokens = False ## Names to include in the subject alternative name. # # These names will be used for server name verification. This is useful # if JupyterHub is being run behind a reverse proxy or services using ssl # are on different hosts. # # Use with internal_ssl # Default: [] # c.JupyterHub.trusted_alt_names = [] ## Downstream proxy IP addresses to trust. # # This sets the list of IP addresses that are trusted and skipped when processing # the `X-Forwarded-For` header. For example, if an external proxy is used for TLS # termination, its IP address should be added to this list to ensure the correct # client IP addresses are recorded in the logs instead of the proxy server's IP # address. # Default: [] # c.JupyterHub.trusted_downstream_ips = [] ## Upgrade the database automatically on start. # # Only safe if database is regularly backed up. # Only SQLite databases will be backed up to a local file automatically. # Default: False # c.JupyterHub.upgrade_db = False ## Return 503 rather than 424 when request comes in for a non-running server. # # Prior to JupyterHub 2.0, this returns a 503 when any request comes in for a # user server that is currently not running. By default, JupyterHub 2.0 will # return a 424 - this makes operational metric dashboards more useful. # # JupyterLab < 3.2 expected the 503 to know if the user server is no longer # running, and prompted the user to start their server. Set this config to true # to retain the old behavior, so JupyterLab < 3.2 can continue to show the # appropriate UI when the user server is stopped. # # This option will default to False in JupyterHub 2.0, and be removed in a # future release. # Default: True # c.JupyterHub.use_legacy_stopped_server_status_code = True ## Callable to affect behavior of /user-redirect/ # # Receives 4 parameters: 1. path - URL path that was provided after /user- # redirect/ 2. request - A Tornado HTTPServerRequest representing the current # request. 3. user - The currently authenticated user. 4. base_url - The # base_url of the current hub, for relative redirects # # It should return the new URL to redirect to, or None to preserve current # behavior. # Default: None # c.JupyterHub.user_redirect_hook = None #------------------------------------------------------------------------------ # Spawner(LoggingConfigurable) configuration #------------------------------------------------------------------------------ ## Base class for spawning single-user notebook servers. # # Subclass this, and override the following methods: # # - load_state # - get_state # - start # - stop # - poll # # As JupyterHub supports multiple users, an instance of the Spawner subclass # is created for each user. If there are 20 JupyterHub users, there will be 20 # instances of the subclass. ## Extra arguments to be passed to the single-user server. # # Some spawners allow shell-style expansion here, allowing you to use # environment variables here. Most, including the default, do not. Consult the # documentation for your spawner to verify! # Default: [] # c.Spawner.args = [] ## An optional hook function that you can implement to pass `auth_state` to the # spawner after it has been initialized but before it starts. The `auth_state` # dictionary may be set by the `.authenticate()` method of the authenticator. # This hook enables you to pass some or all of that information to your spawner. # # Example:: # # def userdata_hook(spawner, auth_state): # spawner.userdata = auth_state["userdata"] # # c.Spawner.auth_state_hook = userdata_hook # Default: None # c.Spawner.auth_state_hook = None ## The command used for starting the single-user server. # # Provide either a string or a list containing the path to the startup script # command. Extra arguments, other than this path, should be provided via `args`. # # This is usually set if you want to start the single-user server in a different # python environment (with virtualenv/conda) than JupyterHub itself. # # Some spawners allow shell-style expansion here, allowing you to use # environment variables. Most, including the default, do not. Consult the # documentation for your spawner to verify! # Default: ['jupyterhub-singleuser'] # c.Spawner.cmd = ['jupyterhub-singleuser'] ## Maximum number of consecutive failures to allow before shutting down # JupyterHub. # # This helps JupyterHub recover from a certain class of problem preventing # launch in contexts where the Hub is automatically restarted (e.g. systemd, # docker, kubernetes). # # A limit of 0 means no limit and consecutive failures will not be tracked. # Default: 0 # c.Spawner.consecutive_failure_limit = 0 ## Minimum number of cpu-cores a single-user notebook server is guaranteed to # have available. # # If this value is set to 0.5, allows use of 50% of one CPU. If this value is # set to 2, allows use of up to 2 CPUs. # # **This is a configuration setting. Your spawner must implement support for the # limit to work.** The default spawner, `LocalProcessSpawner`, does **not** # implement this support. A custom spawner **must** add support for this setting # for it to be enforced. # Default: None # c.Spawner.cpu_guarantee = None ## Maximum number of cpu-cores a single-user notebook server is allowed to use. # # If this value is set to 0.5, allows use of 50% of one CPU. If this value is # set to 2, allows use of up to 2 CPUs. # # The single-user notebook server will never be scheduled by the kernel to use # more cpu-cores than this. There is no guarantee that it can access this many # cpu-cores. # # **This is a configuration setting. Your spawner must implement support for the # limit to work.** The default spawner, `LocalProcessSpawner`, does **not** # implement this support. A custom spawner **must** add support for this setting # for it to be enforced. # Default: None # c.Spawner.cpu_limit = None ## Enable debug-logging of the single-user server # Default: False # c.Spawner.debug = False ## The URL the single-user server should start in. # # `{username}` will be expanded to the user's username # # Example uses: # # - You can set `notebook_dir` to `/` and `default_url` to `/tree/home/{username}` to allow people to # navigate the whole filesystem from their notebook server, but still start in their home directory. # - Start with `/notebooks` instead of `/tree` if `default_url` points to a notebook instead of a directory. # - You can set this to `/lab` to have JupyterLab start by default, rather than Jupyter Notebook. # Default: '' # c.Spawner.default_url = '' ## Disable per-user configuration of single-user servers. # # When starting the user's single-user server, any config file found in the # user's $HOME directory will be ignored. # # Note: a user could circumvent this if the user modifies their Python # environment, such as when they have their own conda environments / virtualenvs # / containers. # Default: False # c.Spawner.disable_user_config = False ## List of environment variables for the single-user server to inherit from the # JupyterHub process. # # This list is used to ensure that sensitive information in the JupyterHub # process's environment (such as `CONFIGPROXY_AUTH_TOKEN`) is not passed to the # single-user server's process. # Default: ['PATH', 'PYTHONPATH', 'CONDA_ROOT', 'CONDA_DEFAULT_ENV', 'VIRTUAL_ENV', 'LANG', 'LC_ALL', 'JUPYTERHUB_SINGLEUSER_APP'] # c.Spawner.env_keep = ['PATH', 'PYTHONPATH', 'CONDA_ROOT', 'CONDA_DEFAULT_ENV', 'VIRTUAL_ENV', 'LANG', 'LC_ALL', 'JUPYTERHUB_SINGLEUSER_APP'] ## Extra environment variables to set for the single-user server's process. # # Environment variables that end up in the single-user server's process come from 3 sources: # - This `environment` configurable # - The JupyterHub process' environment variables that are listed in `env_keep` # - Variables to establish contact between the single-user notebook and the hub (such as JUPYTERHUB_API_TOKEN) # # The `environment` configurable should be set by JupyterHub administrators to # add installation specific environment variables. It is a dict where the key is # the name of the environment variable, and the value can be a string or a # callable. If it is a callable, it will be called with one parameter (the # spawner instance), and should return a string fairly quickly (no blocking # operations please!). # # Note that the spawner class' interface is not guaranteed to be exactly same # across upgrades, so if you are using the callable take care to verify it # continues to work after upgrades! # # .. versionchanged:: 1.2 # environment from this configuration has highest priority, # allowing override of 'default' env variables, # such as JUPYTERHUB_API_URL. # Default: {} # c.Spawner.environment = {} ## Timeout (in seconds) before giving up on a spawned HTTP server # # Once a server has successfully been spawned, this is the amount of time we # wait before assuming that the server is unable to accept connections. # Default: 30 # c.Spawner.http_timeout = 30 ## The URL the single-user server should connect to the Hub. # # If the Hub URL set in your JupyterHub config is not reachable from spawned # notebooks, you can set differnt URL by this config. # # Is None if you don't need to change the URL. # Default: None # c.Spawner.hub_connect_url = None ## The IP address (or hostname) the single-user server should listen on. # # The JupyterHub proxy implementation should be able to send packets to this # interface. # Default: '' # c.Spawner.ip = '' ## Minimum number of bytes a single-user notebook server is guaranteed to have # available. # # Allows the following suffixes: # - K -> Kilobytes # - M -> Megabytes # - G -> Gigabytes # - T -> Terabytes # # **This is a configuration setting. Your spawner must implement support for the # limit to work.** The default spawner, `LocalProcessSpawner`, does **not** # implement this support. A custom spawner **must** add support for this setting # for it to be enforced. # Default: None # c.Spawner.mem_guarantee = None ## Maximum number of bytes a single-user notebook server is allowed to use. # # Allows the following suffixes: # - K -> Kilobytes # - M -> Megabytes # - G -> Gigabytes # - T -> Terabytes # # If the single user server tries to allocate more memory than this, it will # fail. There is no guarantee that the single-user notebook server will be able # to allocate this much memory - only that it can not allocate more than this. # # **This is a configuration setting. Your spawner must implement support for the # limit to work.** The default spawner, `LocalProcessSpawner`, does **not** # implement this support. A custom spawner **must** add support for this setting # for it to be enforced. # Default: None # c.Spawner.mem_limit = None ## Path to the notebook directory for the single-user server. # # The user sees a file listing of this directory when the notebook interface is # started. The current interface does not easily allow browsing beyond the # subdirectories in this directory's tree. # # `~` will be expanded to the home directory of the user, and {username} will be # replaced with the name of the user. # # Note that this does *not* prevent users from accessing files outside of this # path! They can do so with many other means. # Default: '' # c.Spawner.notebook_dir = '' ## An HTML form for options a user can specify on launching their server. # # The surrounding `<form>` element and the submit button are already provided. # # For example: # # .. code:: html # # Set your key: # <input name="key" val="default_key"></input> # <br> # Choose a letter: # <select name="letter" multiple="true"> # <option value="A">The letter A</option> # <option value="B">The letter B</option> # </select> # # The data from this form submission will be passed on to your spawner in # `self.user_options` # # Instead of a form snippet string, this could also be a callable that takes as # one parameter the current spawner instance and returns a string. The callable # will be called asynchronously if it returns a future, rather than a str. Note # that the interface of the spawner class is not deemed stable across versions, # so using this functionality might cause your JupyterHub upgrades to break. # Default: traitlets.Undefined # c.Spawner.options_form = traitlets.Undefined ## Interpret HTTP form data # # Form data will always arrive as a dict of lists of strings. Override this # function to understand single-values, numbers, etc. # # This should coerce form data into the structure expected by self.user_options, # which must be a dict, and should be JSON-serializeable, though it can contain # bytes in addition to standard JSON data types. # # This method should not have any side effects. Any handling of `user_options` # should be done in `.start()` to ensure consistent behavior across servers # spawned via the API and form submission page. # # Instances will receive this data on self.user_options, after passing through # this function, prior to `Spawner.start`. # # .. versionchanged:: 1.0 # user_options are persisted in the JupyterHub database to be reused # on subsequent spawns if no options are given. # user_options is serialized to JSON as part of this persistence # (with additional support for bytes in case of uploaded file data), # and any non-bytes non-jsonable values will be replaced with None # if the user_options are re-used. # Default: traitlets.Undefined # c.Spawner.options_from_form = traitlets.Undefined ## Interval (in seconds) on which to poll the spawner for single-user server's # status. # # At every poll interval, each spawner's `.poll` method is called, which checks # if the single-user server is still running. If it isn't running, then # JupyterHub modifies its own state accordingly and removes appropriate routes # from the configurable proxy. # Default: 30 # c.Spawner.poll_interval = 30 ## The port for single-user servers to listen on. # # Defaults to `0`, which uses a randomly allocated port number each time. # # If set to a non-zero value, all Spawners will use the same port, which only # makes sense if each server is on a different address, e.g. in containers. # # New in version 0.7. # Default: 0 # c.Spawner.port = 0 ## An optional hook function that you can implement to do work after the spawner # stops. # # This can be set independent of any concrete spawner implementation. # Default: None # c.Spawner.post_stop_hook = None ## An optional hook function that you can implement to do some bootstrapping work # before the spawner starts. For example, create a directory for your user or # load initial content. # # This can be set independent of any concrete spawner implementation. # # This maybe a coroutine. # # Example:: # # from subprocess import check_call # def my_hook(spawner): # username = spawner.user.name # check_call(['./examples/bootstrap-script/bootstrap.sh', username]) # # c.Spawner.pre_spawn_hook = my_hook # Default: None # c.Spawner.pre_spawn_hook = None ## List of SSL alt names # # May be set in config if all spawners should have the same value(s), # or set at runtime by Spawner that know their names. # Default: [] # c.Spawner.ssl_alt_names = [] ## Whether to include DNS:localhost, IP:127.0.0.1 in alt names # Default: True # c.Spawner.ssl_alt_names_include_local = True ## Timeout (in seconds) before giving up on starting of single-user server. # # This is the timeout for start to return, not the timeout for the server to # respond. Callers of spawner.start will assume that startup has failed if it # takes longer than this. start should return when the server process is started # and its location is known. # Default: 60 # c.Spawner.start_timeout = 60 #------------------------------------------------------------------------------ # Authenticator(LoggingConfigurable) configuration #------------------------------------------------------------------------------ ## Base class for implementing an authentication provider for JupyterHub ## Set of users that will have admin rights on this JupyterHub. # # Admin users have extra privileges: # - Use the admin panel to see list of users logged in # - Add / remove users in some authenticators # - Restart / halt the hub # - Start / stop users' single-user servers # - Can access each individual users' single-user server (if configured) # # Admin access should be treated the same way root access is. # # Defaults to an empty set, in which case no user has admin access. # Default: set() # c.Authenticator.admin_users = set() ## Set of usernames that are allowed to log in. # # Use this with supported authenticators to restrict which users can log in. # This is an additional list that further restricts users, beyond whatever # restrictions the authenticator has in place. # # If empty, does not perform any additional restriction. # # .. versionchanged:: 1.2 # `Authenticator.whitelist` renamed to `allowed_users` # Default: set() # c.Authenticator.allowed_users = set() ## The max age (in seconds) of authentication info # before forcing a refresh of user auth info. # # Refreshing auth info allows, e.g. requesting/re-validating auth # tokens. # # See :meth:`.refresh_user` for what happens when user auth info is refreshed # (nothing by default). # Default: 300 # c.Authenticator.auth_refresh_age = 300 ## Automatically begin the login process # # rather than starting with a "Login with..." link at `/hub/login` # # To work, `.login_url()` must give a URL other than the default `/hub/login`, # such as an oauth handler or another automatic login handler, # registered with `.get_handlers()`. # # .. versionadded:: 0.8 # Default: False # c.Authenticator.auto_login = False ## Automatically begin login process for OAuth2 authorization requests # # When another application is using JupyterHub as OAuth2 provider, it sends # users to `/hub/api/oauth2/authorize`. If the user isn't logged in already, and # auto_login is not set, the user will be dumped on the hub's home page, without # any context on what to do next. # # Setting this to true will automatically redirect users to login if they aren't # logged in *only* on the `/hub/api/oauth2/authorize` endpoint. # # .. versionadded:: 1.5 # Default: False # c.Authenticator.auto_login_oauth2_authorize = False ## Set of usernames that are not allowed to log in. # # Use this with supported authenticators to restrict which users can not log in. # This is an additional block list that further restricts users, beyond whatever # restrictions the authenticator has in place. # # If empty, does not perform any additional restriction. # # .. versionadded: 0.9 # # .. versionchanged:: 1.2 # `Authenticator.blacklist` renamed to `blocked_users` # Default: set() # c.Authenticator.blocked_users = set() ## Delete any users from the database that do not pass validation # # When JupyterHub starts, `.add_user` will be called # on each user in the database to verify that all users are still valid. # # If `delete_invalid_users` is True, # any users that do not pass validation will be deleted from the database. # Use this if users might be deleted from an external system, # such as local user accounts. # # If False (default), invalid users remain in the Hub's database # and a warning will be issued. # This is the default to avoid data loss due to config changes. # Default: False # c.Authenticator.delete_invalid_users = False ## Enable persisting auth_state (if available). # # auth_state will be encrypted and stored in the Hub's database. # This can include things like authentication tokens, etc. # to be passed to Spawners as environment variables. # # Encrypting auth_state requires the cryptography package. # # Additionally, the JUPYTERHUB_CRYPT_KEY environment variable must # contain one (or more, separated by ;) 32B encryption keys. # These can be either base64 or hex-encoded. # # If encryption is unavailable, auth_state cannot be persisted. # # New in JupyterHub 0.8 # Default: False # c.Authenticator.enable_auth_state = False ## An optional hook function that you can implement to do some bootstrapping work # during authentication. For example, loading user account details from an # external system. # # This function is called after the user has passed all authentication checks # and is ready to successfully authenticate. This function must return the # authentication dict reguardless of changes to it. # # This maybe a coroutine. # # .. versionadded: 1.0 # # Example:: # # import os, pwd # def my_hook(authenticator, handler, authentication): # user_data = pwd.getpwnam(authentication['name']) # spawn_data = { # 'pw_data': user_data # 'gid_list': os.getgrouplist(authentication['name'], user_data.pw_gid) # } # # if authentication['auth_state'] is None: # authentication['auth_state'] = {} # authentication['auth_state']['spawn_data'] = spawn_data # # return authentication # # c.Authenticator.post_auth_hook = my_hook # Default: None # c.Authenticator.post_auth_hook = None ## Force refresh of auth prior to spawn. # # This forces :meth:`.refresh_user` to be called prior to launching # a server, to ensure that auth state is up-to-date. # # This can be important when e.g. auth tokens that may have expired # are passed to the spawner via environment variables from auth_state. # # If refresh_user cannot refresh the user auth data, # launch will fail until the user logs in again. # Default: False # c.Authenticator.refresh_pre_spawn = False ## Dictionary mapping authenticator usernames to JupyterHub users. # # Primarily used to normalize OAuth user names to local users. # Default: {} # c.Authenticator.username_map = {} ## Regular expression pattern that all valid usernames must match. # # If a username does not match the pattern specified here, authentication will # not be attempted. # # If not set, allow any username. # Default: '' # c.Authenticator.username_pattern = '' ## Deprecated, use `Authenticator.allowed_users` # Default: set() # c.Authenticator.whitelist = set() #------------------------------------------------------------------------------ # CryptKeeper(SingletonConfigurable) configuration #------------------------------------------------------------------------------ ## Encapsulate encryption configuration # # Use via the encryption_config singleton below. # Default: [] # c.CryptKeeper.keys = [] ## The number of threads to allocate for encryption # Default: 2 # c.CryptKeeper.n_threads = 2 #------------------------------------------------------------------------------ # Pagination(Configurable) configuration #------------------------------------------------------------------------------ ## Default number of entries per page for paginated results. # Default: 100 # c.Pagination.default_per_page = 100 ## Maximum number of entries per page for paginated results. # Default: 250 # c.Pagination.max_per_page = 250 -
jupyterhub 命令附录
# -----------------------jupyterhub 命令帮助---------------------------------------- JupyterHub help command output This section contains the output of the command jupyterhub --help-all. Start a multi-user Jupyter Notebook server Spawns a configurable-http-proxy and multi-user Hub, which authenticates users and spawns single-user Notebook servers on behalf of users. Subcommands =========== Subcommands are launched as `jupyterhub cmd [args]`. For information on using subcommand 'cmd', do: `jupyterhub cmd -h`. token Generate an API token for a user upgrade-db Upgrade your JupyterHub state database to the current version. Options ======= The options below are convenience aliases to configurable class-options, as listed in the "Equivalent to" description-line of the aliases. To see all configurable class-options for some <cmd>, use: <cmd> --help-all --debug set log level to logging.DEBUG (maximize logging output) Equivalent to: [--Application.log_level=10] --generate-config generate default config file Equivalent to: [--JupyterHub.generate_config=True] --generate-certs generate certificates used for internal ssl Equivalent to: [--JupyterHub.generate_certs=True] --no-db disable persisting state database to disk Equivalent to: [--JupyterHub.db_url=sqlite:///:memory:] --upgrade-db Automatically upgrade the database if needed on startup. Only safe if the database has been backed up. Only SQLite database files will be backed up automatically. Equivalent to: [--JupyterHub.upgrade_db=True] --no-ssl [DEPRECATED in 0.7: does nothing] Equivalent to: [--JupyterHub.confirm_no_ssl=True] --base-url=<URLPrefix> The base URL of the entire application. Add this to the beginning of all JupyterHub URLs. Use base_url to run JupyterHub within an existing website. .. deprecated: 0.9 Use JupyterHub.bind_url Default: '/' Equivalent to: [--JupyterHub.base_url] -y=<Bool> Answer yes to any questions (e.g. confirm overwrite) Default: False Equivalent to: [--JupyterHub.answer_yes] --ssl-key=<Unicode> Path to SSL key file for the public facing interface of the proxy When setting this, you should also set ssl_cert Default: '' Equivalent to: [--JupyterHub.ssl_key] --ssl-cert=<Unicode> Path to SSL certificate file for the public facing interface of the proxy When setting this, you should also set ssl_key Default: '' Equivalent to: [--JupyterHub.ssl_cert] --url=<Unicode> The public facing URL of the whole JupyterHub application. This is the address on which the proxy will bind. Sets protocol, ip, base_url Default: 'http://:8000' Equivalent to: [--JupyterHub.bind_url] --ip=<Unicode> The public facing ip of the whole JupyterHub application (specifically referred to as the proxy). This is the address on which the proxy will listen. The default is to listen on all interfaces. This is the only address through which JupyterHub should be accessed by users. .. deprecated: 0.9 Use JupyterHub.bind_url Default: '' Equivalent to: [--JupyterHub.ip] --port=<Int> The public facing port of the proxy. This is the port on which the proxy will listen. This is the only port through which JupyterHub should be accessed by users. .. deprecated: 0.9 Use JupyterHub.bind_url Default: 8000 Equivalent to: [--JupyterHub.port] --pid-file=<Unicode> File to write PID Useful for daemonizing JupyterHub. Default: '' Equivalent to: [--JupyterHub.pid_file] --log-file=<Unicode> DEPRECATED: use output redirection instead, e.g. jupyterhub &>> /var/log/jupyterhub.log Default: '' Equivalent to: [--JupyterHub.extra_log_file] --log-level=<Enum> Set the log level by value or name. Choices: any of [0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL'] Default: 30 Equivalent to: [--Application.log_level] -f=<Unicode> The config file to load Default: 'jupyterhub_config.py' Equivalent to: [--JupyterHub.config_file] --config=<Unicode> The config file to load Default: 'jupyterhub_config.py' Equivalent to: [--JupyterHub.config_file] --db=<Unicode> url for the database. e.g. `sqlite:///jupyterhub.sqlite` Default: 'sqlite:///jupyterhub.sqlite' Equivalent to: [--JupyterHub.db_url] Class options ============= The command-line option below sets the respective configurable class-parameter: --Class.parameter=value This line is evaluated in Python, so simple expressions are allowed. For instance, to set `C.a=[0,1,2]`, you may type this: --C.a='range(3)' Application(SingletonConfigurable) options ------------------------------------------ --Application.log_datefmt=<Unicode> The date format used by logging formatters for %(asctime)s Default: '%Y-%m-%d %H:%M:%S' --Application.log_format=<Unicode> The Logging format template Default: '[%(name)s]%(highlevel)s %(message)s' --Application.log_level=<Enum> Set the log level by value or name. Choices: any of [0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL'] Default: 30 --Application.show_config=<Bool> Instead of starting the Application, dump configuration to stdout Default: False --Application.show_config_json=<Bool> Instead of starting the Application, dump configuration to stdout (as JSON) Default: False JupyterHub(Application) options ------------------------------- --JupyterHub.active_server_limit=<Int> Maximum number of concurrent servers that can be active at a time. Setting this can limit the total resources your users can consume. An active server is any server that's not fully stopped. It is considered active from the time it has been requested until the time that it has completely stopped. If this many user servers are active, users will not be able to launch new servers until a server is shutdown. Spawn requests will be rejected with a 429 error asking them to try again. If set to 0, no limit is enforced. Default: 0 --JupyterHub.active_user_window=<Int> Duration (in seconds) to determine the number of active users. Default: 1800 --JupyterHub.activity_resolution=<Int> Resolution (in seconds) for updating activity If activity is registered that is less than activity_resolution seconds more recent than the current value, the new value will be ignored. This avoids too many writes to the Hub database. Default: 30 --JupyterHub.admin_access=<Bool> Grant admin users permission to access single-user servers. Users should be properly informed if this is enabled. Default: False --JupyterHub.admin_users=<set-item-1>... DEPRECATED since version 0.7.2, use Authenticator.admin_users instead. Default: set() --JupyterHub.allow_named_servers=<Bool> Allow named single-user servers per user Default: False --JupyterHub.answer_yes=<Bool> Answer yes to any questions (e.g. confirm overwrite) Default: False --JupyterHub.api_tokens=<key-1>=<value-1>... PENDING DEPRECATION: consider using services Dict of token:username to be loaded into the database. Allows ahead-of-time generation of API tokens for use by externally managed services, which authenticate as JupyterHub users. Consider using services for general services that talk to the JupyterHub API. Default: {} --JupyterHub.authenticate_prometheus=<Bool> Authentication for prometheus metrics Default: True --JupyterHub.authenticator_class=<EntryPointType> Class for authenticating users. This should be a subclass of :class:`jupyterhub.auth.Authenticator` with an :meth:`authenticate` method that: - is a coroutine (asyncio or tornado) - returns username on success, None on failure - takes two arguments: (handler, data), where `handler` is the calling web.RequestHandler, and `data` is the POST form data from the login page. .. versionchanged:: 1.0 authenticators may be registered via entry points, e.g. `c.JupyterHub.authenticator_class = 'pam'` Currently installed: - default: jupyterhub.auth.PAMAuthenticator - dummy: jupyterhub.auth.DummyAuthenticator - pam: jupyterhub.auth.PAMAuthenticator Default: 'jupyterhub.auth.PAMAuthenticator' --JupyterHub.base_url=<URLPrefix> The base URL of the entire application. Add this to the beginning of all JupyterHub URLs. Use base_url to run JupyterHub within an existing website. .. deprecated: 0.9 Use JupyterHub.bind_url Default: '/' --JupyterHub.bind_url=<Unicode> The public facing URL of the whole JupyterHub application. This is the address on which the proxy will bind. Sets protocol, ip, base_url Default: 'http://:8000' --JupyterHub.cleanup_proxy=<Bool> Whether to shutdown the proxy when the Hub shuts down. Disable if you want to be able to teardown the Hub while leaving the proxy running. Only valid if the proxy was starting by the Hub process. If both this and cleanup_servers are False, sending SIGINT to the Hub will only shutdown the Hub, leaving everything else running. The Hub should be able to resume from database state. Default: True --JupyterHub.cleanup_servers=<Bool> Whether to shutdown single-user servers when the Hub shuts down. Disable if you want to be able to teardown the Hub while leaving the single-user servers running. If both this and cleanup_proxy are False, sending SIGINT to the Hub will only shutdown the Hub, leaving everything else running. The Hub should be able to resume from database state. Default: True --JupyterHub.concurrent_spawn_limit=<Int> Maximum number of concurrent users that can be spawning at a time. Spawning lots of servers at the same time can cause performance problems for the Hub or the underlying spawning system. Set this limit to prevent bursts of logins from attempting to spawn too many servers at the same time. This does not limit the number of total running servers. See active_server_limit for that. If more than this many users attempt to spawn at a time, their requests will be rejected with a 429 error asking them to try again. Users will have to wait for some of the spawning services to finish starting before they can start their own. If set to 0, no limit is enforced. Default: 100 --JupyterHub.config_file=<Unicode> The config file to load Default: 'jupyterhub_config.py' --JupyterHub.confirm_no_ssl=<Bool> DEPRECATED: does nothing Default: False --JupyterHub.cookie_max_age_days=<Float> Number of days for a login cookie to be valid. Default is two weeks. Default: 14 --JupyterHub.cookie_secret=<Union> The cookie secret to use to encrypt cookies. Loaded from the JPY_COOKIE_SECRET env variable by default. Should be exactly 256 bits (32 bytes). Default: traitlets.Undefined --JupyterHub.cookie_secret_file=<Unicode> File in which to store the cookie secret. Default: 'jupyterhub_cookie_secret' --JupyterHub.data_files_path=<Unicode> The location of jupyterhub data files (e.g. /usr/local/share/jupyterhub) Default: '$HOME/checkouts/readthedocs.org/user_builds/jupyterhub/... --JupyterHub.db_kwargs=<key-1>=<value-1>... Include any kwargs to pass to the database connection. See sqlalchemy.create_engine for details. Default: {} --JupyterHub.db_url=<Unicode> url for the database. e.g. `sqlite:///jupyterhub.sqlite` Default: 'sqlite:///jupyterhub.sqlite' --JupyterHub.debug_db=<Bool> log all database transactions. This has A LOT of output Default: False --JupyterHub.debug_proxy=<Bool> DEPRECATED since version 0.8: Use ConfigurableHTTPProxy.debug Default: False --JupyterHub.default_server_name=<Unicode> If named servers are enabled, default name of server to spawn or open, e.g. by user-redirect. Default: '' --JupyterHub.default_url=<Union> The default URL for users when they arrive (e.g. when user directs to "/") By default, redirects users to their own server. Can be a Unicode string (e.g. '/hub/home') or a callable based on the handler object: :: def default_url_fn(handler): user = handler.current_user if user and user.admin: return '/hub/admin' return '/hub/home' c.JupyterHub.default_url = default_url_fn Default: traitlets.Undefined --JupyterHub.external_ssl_authorities=<key-1>=<value-1>... Dict authority:dict(files). Specify the key, cert, and/or ca file for an authority. This is useful for externally managed proxies that wish to use internal_ssl. The files dict has this format (you must specify at least a cert):: { 'key': '/path/to/key.key', 'cert': '/path/to/cert.crt', 'ca': '/path/to/ca.crt' } The authorities you can override: 'hub-ca', 'notebooks-ca', 'proxy-api-ca', 'proxy-client-ca', and 'services-ca'. Use with internal_ssl Default: {} --JupyterHub.extra_handlers=<list-item-1>... Register extra tornado Handlers for jupyterhub. Should be of the form ``("<regex>", Handler)`` The Hub prefix will be added, so `/my-page` will be served at `/hub/my- page`. Default: [] --JupyterHub.extra_log_file=<Unicode> DEPRECATED: use output redirection instead, e.g. jupyterhub &>> /var/log/jupyterhub.log Default: '' --JupyterHub.extra_log_handlers=<list-item-1>... Extra log handlers to set on JupyterHub logger Default: [] --JupyterHub.generate_certs=<Bool> Generate certs used for internal ssl Default: False --JupyterHub.generate_config=<Bool> Generate default config file Default: False --JupyterHub.hub_bind_url=<Unicode> The URL on which the Hub will listen. This is a private URL for internal communication. Typically set in combination with hub_connect_url. If a unix socket, hub_connect_url **must** also be set. For example: "http://127.0.0.1:8081" "unix+http://%2Fsrv%2Fjupyterhub%2Fjupyterhub.sock" .. versionadded:: 0.9 Default: '' --JupyterHub.hub_connect_ip=<Unicode> The ip or hostname for proxies and spawners to use for connecting to the Hub. Use when the bind address (`hub_ip`) is 0.0.0.0, :: or otherwise different from the connect address. Default: when `hub_ip` is 0.0.0.0 or ::, use `socket.gethostname()`, otherwise use `hub_ip`. Note: Some spawners or proxy implementations might not support hostnames. Check your spawner or proxy documentation to see if they have extra requirements. .. versionadded:: 0.8 Default: '' --JupyterHub.hub_connect_port=<Int> DEPRECATED Use hub_connect_url .. versionadded:: 0.8 .. deprecated:: 0.9 Use hub_connect_url Default: 0 --JupyterHub.hub_connect_url=<Unicode> The URL for connecting to the Hub. Spawners, services, and the proxy will use this URL to talk to the Hub. Only needs to be specified if the default hub URL is not connectable (e.g. using a unix+http:// bind url). .. seealso:: JupyterHub.hub_connect_ip JupyterHub.hub_bind_url .. versionadded:: 0.9 Default: '' --JupyterHub.hub_ip=<Unicode> The ip address for the Hub process to *bind* to. By default, the hub listens on localhost only. This address must be accessible from the proxy and user servers. You may need to set this to a public ip or '' for all interfaces if the proxy or user servers are in containers or on a different host. See `hub_connect_ip` for cases where the bind and connect address should differ, or `hub_bind_url` for setting the full bind URL. Default: '127.0.0.1' --JupyterHub.hub_port=<Int> The internal port for the Hub process. This is the internal port of the hub itself. It should never be accessed directly. See JupyterHub.port for the public port to use when accessing jupyterhub. It is rare that this port should be set except in cases of port conflict. See also `hub_ip` for the ip and `hub_bind_url` for setting the full bind URL. Default: 8081 --JupyterHub.hub_routespec=<Unicode> The routing prefix for the Hub itself. Override to send only a subset of traffic to the Hub. Default is to use the Hub as the default route for all requests. This is necessary for normal jupyterhub operation, as the Hub must receive requests for e.g. `/user/:name` when the user's server is not running. However, some deployments using only the JupyterHub API may want to handle these events themselves, in which case they can register their own default target with the proxy and set e.g. `hub_routespec = /hub/` to serve only the hub's own pages, or even `/hub/api/` for api-only operation. Note: hub_routespec must include the base_url, if any. .. versionadded:: 1.4 Default: '/' --JupyterHub.implicit_spawn_seconds=<Float> Trigger implicit spawns after this many seconds. When a user visits a URL for a server that's not running, they are shown a page indicating that the requested server is not running with a button to spawn the server. Setting this to a positive value will redirect the user after this many seconds, effectively clicking this button automatically for the users, automatically beginning the spawn process. Warning: this can result in errors and surprising behavior when sharing access URLs to actual servers, since the wrong server is likely to be started. Default: 0 --JupyterHub.init_spawners_timeout=<Int> Timeout (in seconds) to wait for spawners to initialize Checking if spawners are healthy can take a long time if many spawners are active at hub start time. If it takes longer than this timeout to check, init_spawner will be left to complete in the background and the http server is allowed to start. A timeout of -1 means wait forever, which can mean a slow startup of the Hub but ensures that the Hub is fully consistent by the time it starts responding to requests. This matches the behavior of jupyterhub 1.0. .. versionadded: 1.1.0 Default: 10 --JupyterHub.internal_certs_location=<Unicode> The location to store certificates automatically created by JupyterHub. Use with internal_ssl Default: 'internal-ssl' --JupyterHub.internal_ssl=<Bool> Enable SSL for all internal communication This enables end-to-end encryption between all JupyterHub components. JupyterHub will automatically create the necessary certificate authority and sign notebook certificates as they're created. Default: False --JupyterHub.ip=<Unicode> The public facing ip of the whole JupyterHub application (specifically referred to as the proxy). This is the address on which the proxy will listen. The default is to listen on all interfaces. This is the only address through which JupyterHub should be accessed by users. .. deprecated: 0.9 Use JupyterHub.bind_url Default: '' --JupyterHub.jinja_environment_options=<key-1>=<value-1>... Supply extra arguments that will be passed to Jinja environment. Default: {} --JupyterHub.last_activity_interval=<Int> Interval (in seconds) at which to update last-activity timestamps. Default: 300 --JupyterHub.load_groups=<key-1>=<value-1>... Dict of 'group': ['usernames'] to load at startup. This strictly *adds* groups and users to groups. Loading one set of groups, then starting JupyterHub again with a different set will not remove users or groups from previous launches. That must be done through the API. Default: {} --JupyterHub.log_datefmt=<Unicode> The date format used by logging formatters for %(asctime)s Default: '%Y-%m-%d %H:%M:%S' --JupyterHub.log_format=<Unicode> The Logging format template Default: '[%(name)s]%(highlevel)s %(message)s' --JupyterHub.log_level=<Enum> Set the log level by value or name. Choices: any of [0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL'] Default: 30 --JupyterHub.logo_file=<Unicode> Specify path to a logo image to override the Jupyter logo in the banner. Default: '' --JupyterHub.named_server_limit_per_user=<Int> Maximum number of concurrent named servers that can be created by a user at a time. Setting this can limit the total resources a user can consume. If set to 0, no limit is enforced. Default: 0 --JupyterHub.oauth_token_expires_in=<Int> Expiry (in seconds) of OAuth access tokens. The default is to expire when the cookie storing them expires, according to `cookie_max_age_days` config. These are the tokens stored in cookies when you visit a single-user server or service. When they expire, you must re-authenticate with the Hub, even if your Hub authentication is still valid. If your Hub authentication is valid, logging in may be a transparent redirect as you refresh the page. This does not affect JupyterHub API tokens in general, which do not expire by default. Only tokens issued during the oauth flow accessing services and single-user servers are affected. .. versionadded:: 1.4 OAuth token expires_in was not previously configurable. .. versionchanged:: 1.4 Default now uses cookie_max_age_days so that oauth tokens which are generally stored in cookies, expire when the cookies storing them expire. Previously, it was one hour. Default: 0 --JupyterHub.pid_file=<Unicode> File to write PID Useful for daemonizing JupyterHub. Default: '' --JupyterHub.port=<Int> The public facing port of the proxy. This is the port on which the proxy will listen. This is the only port through which JupyterHub should be accessed by users. .. deprecated: 0.9 Use JupyterHub.bind_url Default: 8000 --JupyterHub.proxy_api_ip=<Unicode> DEPRECATED since version 0.8 : Use ConfigurableHTTPProxy.api_url Default: '' --JupyterHub.proxy_api_port=<Int> DEPRECATED since version 0.8 : Use ConfigurableHTTPProxy.api_url Default: 0 --JupyterHub.proxy_auth_token=<Unicode> DEPRECATED since version 0.8: Use ConfigurableHTTPProxy.auth_token Default: '' --JupyterHub.proxy_check_interval=<Int> DEPRECATED since version 0.8: Use ConfigurableHTTPProxy.check_running_interval Default: 5 --JupyterHub.proxy_class=<EntryPointType> The class to use for configuring the JupyterHub proxy. Should be a subclass of :class:`jupyterhub.proxy.Proxy`. .. versionchanged:: 1.0 proxies may be registered via entry points, e.g. `c.JupyterHub.proxy_class = 'traefik'` Currently installed: - configurable-http-proxy: jupyterhub.proxy.ConfigurableHTTPProxy - default: jupyterhub.proxy.ConfigurableHTTPProxy Default: 'jupyterhub.proxy.ConfigurableHTTPProxy' --JupyterHub.proxy_cmd=<command-item-1>... DEPRECATED since version 0.8. Use ConfigurableHTTPProxy.command Default: [] --JupyterHub.recreate_internal_certs=<Bool> Recreate all certificates used within JupyterHub on restart. Note: enabling this feature requires restarting all notebook servers. Use with internal_ssl Default: False --JupyterHub.redirect_to_server=<Bool> Redirect user to server (if running), instead of control panel. Default: True --JupyterHub.reset_db=<Bool> Purge and reset the database. Default: False --JupyterHub.service_check_interval=<Int> Interval (in seconds) at which to check connectivity of services with web endpoints. Default: 60 --JupyterHub.service_tokens=<key-1>=<value-1>... Dict of token:servicename to be loaded into the database. Allows ahead-of-time generation of API tokens for use by externally managed services. Default: {} --JupyterHub.services=<list-item-1>... List of service specification dictionaries. A service For instance:: services = [ { 'name': 'cull_idle', 'command': ['/path/to/cull_idle_servers.py'], }, { 'name': 'formgrader', 'url': 'http://127.0.0.1:1234', 'api_token': 'super-secret', 'environment': } ] Default: [] --JupyterHub.show_config=<Bool> Instead of starting the Application, dump configuration to stdout Default: False --JupyterHub.show_config_json=<Bool> Instead of starting the Application, dump configuration to stdout (as JSON) Default: False --JupyterHub.shutdown_on_logout=<Bool> Shuts down all user servers on logout Default: False --JupyterHub.spawner_class=<EntryPointType> The class to use for spawning single-user servers. Should be a subclass of :class:`jupyterhub.spawner.Spawner`. .. versionchanged:: 1.0 spawners may be registered via entry points, e.g. `c.JupyterHub.spawner_class = 'localprocess'` Currently installed: - default: jupyterhub.spawner.LocalProcessSpawner - localprocess: jupyterhub.spawner.LocalProcessSpawner - simple: jupyterhub.spawner.SimpleLocalProcessSpawner Default: 'jupyterhub.spawner.LocalProcessSpawner' --JupyterHub.ssl_cert=<Unicode> Path to SSL certificate file for the public facing interface of the proxy When setting this, you should also set ssl_key Default: '' --JupyterHub.ssl_key=<Unicode> Path to SSL key file for the public facing interface of the proxy When setting this, you should also set ssl_cert Default: '' --JupyterHub.statsd_host=<Unicode> Host to send statsd metrics to. An empty string (the default) disables sending metrics. Default: '' --JupyterHub.statsd_port=<Int> Port on which to send statsd metrics about the hub Default: 8125 --JupyterHub.statsd_prefix=<Unicode> Prefix to use for all metrics sent by jupyterhub to statsd Default: 'jupyterhub' --JupyterHub.subdomain_host=<Unicode> Run single-user servers on subdomains of this host. This should be the full `https://hub.domain.tld[:port]`. Provides additional cross-site protections for javascript served by single-user servers. Requires `<username>.hub.domain.tld` to resolve to the same host as `hub.domain.tld`. In general, this is most easily achieved with wildcard DNS. When using SSL (i.e. always) this also requires a wildcard SSL certificate. Default: '' --JupyterHub.template_paths=<list-item-1>... Paths to search for jinja templates, before using the default templates. Default: [] --JupyterHub.template_vars=<key-1>=<value-1>... Extra variables to be passed into jinja templates Default: {} --JupyterHub.tornado_settings=<key-1>=<value-1>... Extra settings overrides to pass to the tornado application. Default: {} --JupyterHub.trust_user_provided_tokens=<Bool> Trust user-provided tokens (via JupyterHub.service_tokens) to have good entropy. If you are not inserting additional tokens via configuration file, this flag has no effect. In JupyterHub 0.8, internally generated tokens do not pass through additional hashing because the hashing is costly and does not increase the entropy of already-good UUIDs. User-provided tokens, on the other hand, are not trusted to have good entropy by default, and are passed through many rounds of hashing to stretch the entropy of the key (i.e. user-provided tokens are treated as passwords instead of random keys). These keys are more costly to check. If your inserted tokens are generated by a good-quality mechanism, e.g. `openssl rand -hex 32`, then you can set this flag to True to reduce the cost of checking authentication tokens. Default: False --JupyterHub.trusted_alt_names=<list-item-1>... Names to include in the subject alternative name. These names will be used for server name verification. This is useful if JupyterHub is being run behind a reverse proxy or services using ssl are on different hosts. Use with internal_ssl Default: [] --JupyterHub.trusted_downstream_ips=<list-item-1>... Downstream proxy IP addresses to trust. This sets the list of IP addresses that are trusted and skipped when processing the `X-Forwarded-For` header. For example, if an external proxy is used for TLS termination, its IP address should be added to this list to ensure the correct client IP addresses are recorded in the logs instead of the proxy server's IP address. Default: [] --JupyterHub.upgrade_db=<Bool> Upgrade the database automatically on start. Only safe if database is regularly backed up. Only SQLite databases will be backed up to a local file automatically. Default: False --JupyterHub.use_legacy_stopped_server_status_code=<Bool> Return 503 rather than 424 when request comes in for a non-running server. Prior to JupyterHub 2.0, this returns a 503 when any request comes in for a user server that is currently not running. By default, JupyterHub 2.0 will return a 424 - this makes operational metric dashboards more useful. JupyterLab < 3.2 expected the 503 to know if the user server is no longer running, and prompted the user to start their server. Set this config to true to retain the old behavior, so JupyterLab < 3.2 can continue to show the appropriate UI when the user server is stopped. This option will default to False in JupyterHub 2.0, and be removed in a future release. Default: True --JupyterHub.user_redirect_hook=<Callable> Callable to affect behavior of /user-redirect/ Receives 4 parameters: 1. path - URL path that was provided after /user- redirect/ 2. request - A Tornado HTTPServerRequest representing the current request. 3. user - The currently authenticated user. 4. base_url - The base_url of the current hub, for relative redirects It should return the new URL to redirect to, or None to preserve current behavior. Default: None Spawner(LoggingConfigurable) options ------------------------------------ --Spawner.args=<list-item-1>... Extra arguments to be passed to the single-user server. Some spawners allow shell-style expansion here, allowing you to use environment variables here. Most, including the default, do not. Consult the documentation for your spawner to verify! Default: [] --Spawner.auth_state_hook=<Any> An optional hook function that you can implement to pass `auth_state` to the spawner after it has been initialized but before it starts. The `auth_state` dictionary may be set by the `.authenticate()` method of the authenticator. This hook enables you to pass some or all of that information to your spawner. Example:: def userdata_hook(spawner, auth_state): spawner.userdata = auth_state["userdata"] c.Spawner.auth_state_hook = userdata_hook Default: None --Spawner.cmd=<command-item-1>... The command used for starting the single-user server. Provide either a string or a list containing the path to the startup script command. Extra arguments, other than this path, should be provided via `args`. This is usually set if you want to start the single-user server in a different python environment (with virtualenv/conda) than JupyterHub itself. Some spawners allow shell-style expansion here, allowing you to use environment variables. Most, including the default, do not. Consult the documentation for your spawner to verify! Default: ['jupyterhub-singleuser'] --Spawner.consecutive_failure_limit=<Int> Maximum number of consecutive failures to allow before shutting down JupyterHub. This helps JupyterHub recover from a certain class of problem preventing launch in contexts where the Hub is automatically restarted (e.g. systemd, docker, kubernetes). A limit of 0 means no limit and consecutive failures will not be tracked. Default: 0 --Spawner.cpu_guarantee=<Float> Minimum number of cpu-cores a single-user notebook server is guaranteed to have available. If this value is set to 0.5, allows use of 50% of one CPU. If this value is set to 2, allows use of up to 2 CPUs. **This is a configuration setting. Your spawner must implement support for the limit to work.** The default spawner, `LocalProcessSpawner`, does **not** implement this support. A custom spawner **must** add support for this setting for it to be enforced. Default: None --Spawner.cpu_limit=<Float> Maximum number of cpu-cores a single-user notebook server is allowed to use. If this value is set to 0.5, allows use of 50% of one CPU. If this value is set to 2, allows use of up to 2 CPUs. The single-user notebook server will never be scheduled by the kernel to use more cpu-cores than this. There is no guarantee that it can access this many cpu-cores. **This is a configuration setting. Your spawner must implement support for the limit to work.** The default spawner, `LocalProcessSpawner`, does **not** implement this support. A custom spawner **must** add support for this setting for it to be enforced. Default: None --Spawner.debug=<Bool> Enable debug-logging of the single-user server Default: False --Spawner.default_url=<Unicode> The URL the single-user server should start in. `{username}` will be expanded to the user's username Example uses: - You can set `notebook_dir` to `/` and `default_url` to `/tree/home/{username}` to allow people to navigate the whole filesystem from their notebook server, but still start in their home directory. - Start with `/notebooks` instead of `/tree` if `default_url` points to a notebook instead of a directory. - You can set this to `/lab` to have JupyterLab start by default, rather than Jupyter Notebook. Default: '' --Spawner.disable_user_config=<Bool> Disable per-user configuration of single-user servers. When starting the user's single-user server, any config file found in the user's $HOME directory will be ignored. Note: a user could circumvent this if the user modifies their Python environment, such as when they have their own conda environments / virtualenvs / containers. Default: False --Spawner.env_keep=<list-item-1>... List of environment variables for the single-user server to inherit from the JupyterHub process. This list is used to ensure that sensitive information in the JupyterHub process's environment (such as `CONFIGPROXY_AUTH_TOKEN`) is not passed to the single-user server's process. Default: ['PATH', 'PYTHONPATH', 'CONDA_ROOT', 'CONDA_DEFAULT_ENV', 'VI... --Spawner.environment=<key-1>=<value-1>... Extra environment variables to set for the single-user server's process. Environment variables that end up in the single-user server's process come from 3 sources: - This `environment` configurable - The JupyterHub process' environment variables that are listed in `env_keep` - Variables to establish contact between the single-user notebook and the hub (such as JUPYTERHUB_API_TOKEN) The `environment` configurable should be set by JupyterHub administrators to add installation specific environment variables. It is a dict where the key is the name of the environment variable, and the value can be a string or a callable. If it is a callable, it will be called with one parameter (the spawner instance), and should return a string fairly quickly (no blocking operations please!). Note that the spawner class' interface is not guaranteed to be exactly same across upgrades, so if you are using the callable take care to verify it continues to work after upgrades! .. versionchanged:: 1.2 environment from this configuration has highest priority, allowing override of 'default' env variables, such as JUPYTERHUB_API_URL. Default: {} --Spawner.http_timeout=<Int> Timeout (in seconds) before giving up on a spawned HTTP server Once a server has successfully been spawned, this is the amount of time we wait before assuming that the server is unable to accept connections. Default: 30 --Spawner.hub_connect_url=<Unicode> The URL the single-user server should connect to the Hub. If the Hub URL set in your JupyterHub config is not reachable from spawned notebooks, you can set differnt URL by this config. Is None if you don't need to change the URL. Default: None --Spawner.ip=<Unicode> The IP address (or hostname) the single-user server should listen on. The JupyterHub proxy implementation should be able to send packets to this interface. Default: '' --Spawner.mem_guarantee=<ByteSpecification> Minimum number of bytes a single-user notebook server is guaranteed to have available. Allows the following suffixes: - K -> Kilobytes - M -> Megabytes - G -> Gigabytes - T -> Terabytes **This is a configuration setting. Your spawner must implement support for the limit to work.** The default spawner, `LocalProcessSpawner`, does **not** implement this support. A custom spawner **must** add support for this setting for it to be enforced. Default: None --Spawner.mem_limit=<ByteSpecification> Maximum number of bytes a single-user notebook server is allowed to use. Allows the following suffixes: - K -> Kilobytes - M -> Megabytes - G -> Gigabytes - T -> Terabytes If the single user server tries to allocate more memory than this, it will fail. There is no guarantee that the single-user notebook server will be able to allocate this much memory - only that it can not allocate more than this. **This is a configuration setting. Your spawner must implement support for the limit to work.** The default spawner, `LocalProcessSpawner`, does **not** implement this support. A custom spawner **must** add support for this setting for it to be enforced. Default: None --Spawner.notebook_dir=<Unicode> Path to the notebook directory for the single-user server. The user sees a file listing of this directory when the notebook interface is started. The current interface does not easily allow browsing beyond the subdirectories in this directory's tree. `~` will be expanded to the home directory of the user, and {username} will be replaced with the name of the user. Note that this does *not* prevent users from accessing files outside of this path! They can do so with many other means. Default: '' --Spawner.options_form=<Union> An HTML form for options a user can specify on launching their server. The surrounding `<form>` element and the submit button are already provided. For example: .. code:: html Set your key: <input name="key" val="default_key"></input> <br> Choose a letter: <select name="letter" multiple="true"> <option value="A">The letter A</option> <option value="B">The letter B</option> </select> The data from this form submission will be passed on to your spawner in `self.user_options` Instead of a form snippet string, this could also be a callable that takes as one parameter the current spawner instance and returns a string. The callable will be called asynchronously if it returns a future, rather than a str. Note that the interface of the spawner class is not deemed stable across versions, so using this functionality might cause your JupyterHub upgrades to break. Default: traitlets.Undefined --Spawner.options_from_form=<Callable> Interpret HTTP form data Form data will always arrive as a dict of lists of strings. Override this function to understand single-values, numbers, etc. This should coerce form data into the structure expected by self.user_options, which must be a dict, and should be JSON-serializeable, though it can contain bytes in addition to standard JSON data types. This method should not have any side effects. Any handling of `user_options` should be done in `.start()` to ensure consistent behavior across servers spawned via the API and form submission page. Instances will receive this data on self.user_options, after passing through this function, prior to `Spawner.start`. .. versionchanged:: 1.0 user_options are persisted in the JupyterHub database to be reused on subsequent spawns if no options are given. user_options is serialized to JSON as part of this persistence (with additional support for bytes in case of uploaded file data), and any non-bytes non-jsonable values will be replaced with None if the user_options are re-used. Default: traitlets.Undefined --Spawner.poll_interval=<Int> Interval (in seconds) on which to poll the spawner for single-user server's status. At every poll interval, each spawner's `.poll` method is called, which checks if the single-user server is still running. If it isn't running, then JupyterHub modifies its own state accordingly and removes appropriate routes from the configurable proxy. Default: 30 --Spawner.port=<Int> The port for single-user servers to listen on. Defaults to `0`, which uses a randomly allocated port number each time. If set to a non-zero value, all Spawners will use the same port, which only makes sense if each server is on a different address, e.g. in containers. New in version 0.7. Default: 0 --Spawner.post_stop_hook=<Any> An optional hook function that you can implement to do work after the spawner stops. This can be set independent of any concrete spawner implementation. Default: None --Spawner.pre_spawn_hook=<Any> An optional hook function that you can implement to do some bootstrapping work before the spawner starts. For example, create a directory for your user or load initial content. This can be set independent of any concrete spawner implementation. This maybe a coroutine. Example:: from subprocess import check_call def my_hook(spawner): username = spawner.user.name check_call(['./examples/bootstrap-script/bootstrap.sh', username]) c.Spawner.pre_spawn_hook = my_hook Default: None --Spawner.ssl_alt_names=<list-item-1>... List of SSL alt names May be set in config if all spawners should have the same value(s), or set at runtime by Spawner that know their names. Default: [] --Spawner.ssl_alt_names_include_local=<Bool> Whether to include DNS:localhost, IP:127.0.0.1 in alt names Default: True --Spawner.start_timeout=<Int> Timeout (in seconds) before giving up on starting of single-user server. This is the timeout for start to return, not the timeout for the server to respond. Callers of spawner.start will assume that startup has failed if it takes longer than this. start should return when the server process is started and its location is known. Default: 60 Authenticator(LoggingConfigurable) options ------------------------------------------ --Authenticator.admin_users=<set-item-1>... Set of users that will have admin rights on this JupyterHub. Admin users have extra privileges: - Use the admin panel to see list of users logged in - Add / remove users in some authenticators - Restart / halt the hub - Start / stop users' single-user servers - Can access each individual users' single-user server (if configured) Admin access should be treated the same way root access is. Defaults to an empty set, in which case no user has admin access. Default: set() --Authenticator.allowed_users=<set-item-1>... Set of usernames that are allowed to log in. Use this with supported authenticators to restrict which users can log in. This is an additional list that further restricts users, beyond whatever restrictions the authenticator has in place. If empty, does not perform any additional restriction. .. versionchanged:: 1.2 `Authenticator.whitelist` renamed to `allowed_users` Default: set() --Authenticator.auth_refresh_age=<Int> The max age (in seconds) of authentication info before forcing a refresh of user auth info. Refreshing auth info allows, e.g. requesting/re-validating auth tokens. See :meth:`.refresh_user` for what happens when user auth info is refreshed (nothing by default). Default: 300 --Authenticator.auto_login=<Bool> Automatically begin the login process rather than starting with a "Login with..." link at `/hub/login` To work, `.login_url()` must give a URL other than the default `/hub/login`, such as an oauth handler or another automatic login handler, registered with `.get_handlers()`. .. versionadded:: 0.8 Default: False --Authenticator.auto_login_oauth2_authorize=<Bool> Automatically begin login process for OAuth2 authorization requests When another application is using JupyterHub as OAuth2 provider, it sends users to `/hub/api/oauth2/authorize`. If the user isn't logged in already, and auto_login is not set, the user will be dumped on the hub's home page, without any context on what to do next. Setting this to true will automatically redirect users to login if they aren't logged in *only* on the `/hub/api/oauth2/authorize` endpoint. .. versionadded:: 1.5 Default: False --Authenticator.blocked_users=<set-item-1>... Set of usernames that are not allowed to log in. Use this with supported authenticators to restrict which users can not log in. This is an additional block list that further restricts users, beyond whatever restrictions the authenticator has in place. If empty, does not perform any additional restriction. .. versionadded: 0.9 .. versionchanged:: 1.2 `Authenticator.blacklist` renamed to `blocked_users` Default: set() --Authenticator.delete_invalid_users=<Bool> Delete any users from the database that do not pass validation When JupyterHub starts, `.add_user` will be called on each user in the database to verify that all users are still valid. If `delete_invalid_users` is True, any users that do not pass validation will be deleted from the database. Use this if users might be deleted from an external system, such as local user accounts. If False (default), invalid users remain in the Hub's database and a warning will be issued. This is the default to avoid data loss due to config changes. Default: False --Authenticator.enable_auth_state=<Bool> Enable persisting auth_state (if available). auth_state will be encrypted and stored in the Hub's database. This can include things like authentication tokens, etc. to be passed to Spawners as environment variables. Encrypting auth_state requires the cryptography package. Additionally, the JUPYTERHUB_CRYPT_KEY environment variable must contain one (or more, separated by ;) 32B encryption keys. These can be either base64 or hex-encoded. If encryption is unavailable, auth_state cannot be persisted. New in JupyterHub 0.8 Default: False --Authenticator.post_auth_hook=<Any> An optional hook function that you can implement to do some bootstrapping work during authentication. For example, loading user account details from an external system. This function is called after the user has passed all authentication check and is ready to successfully authenticate. This function must return the authentication dict reguardless of changes to it. This maybe a coroutine. .. versionadded: 1.0 Example:: import os, pwd def my_hook(authenticator, handler, authentication): user_data = pwd.getpwnam(authentication['name']) spawn_data = { 'pw_data': user_data 'gid_list': os.getgrouplist(authentication['name'], user_data.pw_gid) } if authentication['auth_state'] is None: authentication['auth_state'] = {} authentication['auth_state']['spawn_data'] = spawn_data return authentication c.Authenticator.post_auth_hook = my_hook Default: None --Authenticator.refresh_pre_spawn=<Bool> Force refresh of auth prior to spawn. This forces :meth:`.refresh_user` to be called prior to launching a server, to ensure that auth state is up-to-date. This can be important when e.g. auth tokens that may have expired are passed to the spawner via environment variables from auth_state. If refresh_user cannot refresh the user auth data, launch will fail until the user logs in again. Default: False --Authenticator.username_map=<key-1>=<value-1>... Dictionary mapping authenticator usernames to JupyterHub users. Primarily used to normalize OAuth user names to local users. Default: {} --Authenticator.username_pattern=<Unicode> Regular expression pattern that all valid usernames must match. If a username does not match the pattern specified here, authentication will not be attempted. If not set, allow any username. Default: '' --Authenticator.whitelist=<set-item-1>... Deprecated, use `Authenticator.allowed_users` Default: set() CryptKeeper(SingletonConfigurable) options ------------------------------------------ --CryptKeeper.keys=<list-item-1>... Default: [] --CryptKeeper.n_threads=<Int> The number of threads to allocate for encryption Default: 2 Pagination(Configurable) options -------------------------------- --Pagination.default_per_page=<Int> Default number of entries per page for paginated results. Default: 100 --Pagination.max_per_page=<Int> Maximum number of entries per page for paginated results. Default: 250 -
dummyauthenticator和SimpleLocalProcessSpawner代码附录
# dummyauthenticator 源码 class DummyAuthenticator(Authenticator): """Dummy Authenticator for testing By default, any username + password is allowed If a non-empty password is set, any username will be allowed if it logs in with that password. .. versionadded:: 1.0 """ password = Unicode( config=True, help=""" Set a global password for all users wanting to log in. This allows users with any username to log in with the same static password. """, ) async def authenticate(self, handler, data): """Checks against a global password if it's been set. If not, allow any user/pass combo""" if self.password: # 根据前端的表单请求数据(username,password)与配置里的password对比,成功返回用 # 户名(username),用于下步生成Jupyterlab进程命名 if data['password'] == self.password: return data['username'] return None return data['username']# SimpleLocalProcessSpawner 源码 class SimpleLocalProcessSpawner(LocalProcessSpawner): """ A version of LocalProcessSpawner that doesn't require users to exist on the system beforehand. Only use this for testing. Note: DO NOT USE THIS FOR PRODUCTION USE CASES! It is very insecure, and provides absolutely no isolation between different users! """ home_dir_template = Unicode( '/tmp/{username}', # 此处设置jupyterlab 工作目录,可修改,username应该是authenticator的返回结果 config=True, help=""" Template to expand to set the user home. {username} is expanded to the jupyterhub username. """, ) home_dir = Unicode(help="The home directory for the user") @default('home_dir') def _default_home_dir(self): return self.home_dir_template.format(username=self.user.name) def make_preexec_fn(self, name): home = self.home_dir def preexec(): try: os.makedirs(home, 0o755, exist_ok=True) os.chdir(home) except Exception as e: self.log.exception("Error in preexec for %s", name) return preexec def user_env(self, env): env['USER'] = self.user.name env['HOME'] = self.home_dir env['SHELL'] = '/bin/bash' return env def move_certs(self, paths): """No-op for installing certs.""" return paths

 浙公网安备 33010602011771号
浙公网安备 33010602011771号