

Aleax prize (开放域聊天系统比赛)2018冠军论文阅读笔记
原文地址:https://m.media-amazon.com/images/G/01/mobile-apps/dex/alexa/alexaprize/assets/pdf/2018/Gunrock.pdf
Abstract
Gunrock是一种社交机器人,旨在让用户参与开放域的对话。我们使用大规模的用户交互数据来迭代地改进了我们的机器人,使其更具能力和人性化。在2018年Alexa奖的半决赛期间,我们的系统进行了40,000多次对话。我们开发了一个上下文感知的分层对话框管理器,以处理各种用户行为,例如主题切换和问题解答。此外,我们设计了一个健壮的三步自然语言理解模块,其中包括句子分割和自动语音识别(ASR)错误校正等技术。此外,我们通过添加韵律语音合成来改善系统的人像性。
1 Introdiction
对话系统研究中的一大挑战是培训和测试具有大量用户的对话系统。大多数研究人员以前在众包平台上通过付费给参与者以模拟用户来培训和评估他们的系统[27]。但是,以这种方式训练和评估的系统在直接部署为实际产品时会产生不稳定的结果。亚马逊Alexa prize提供了一个吸引大量志愿用户与社交对话系统互动的平台。在45天的评估期内,我们平均每天获得500多次对话。在整个开发过程中,我们总共收集了487,314次会话。我们的系统需要处理大量的不同用户。由于人类已经习惯了彼此的交流方式,因此大多数用户可能会将其人与人之间的交流行为方式和期望转移到与系统的交互中。因此,模仿是提高会话系统性能的一种可能方法。Gunrock模仿自然的人与人之间的对话,并具有涵盖各种社会话题的能力,这些话题可以就特定和流行的话题进行深入的交流。
一、新的三相自然语言理解通道
我们在开放领域的口语理解,对话管理和语言生成方面做出了许多贡献。开放域口语理解中的两个主要挑战包括ASR(自动语音识别)错误和实体歧义。我们设计了一种新颖的三相自然语言理解(NLU)管道来解决这些障碍。尽管用户可以一口气说出几个句子,但ASR可以对句子进行解码,但不能像文本输入一样提供标点符号。我们的NLU首先将复杂的输入分解为较小的部分,以降低理解的复杂性。然后,在这些小片段上执行各种NLP技术以提取信息,包括命名实体,对话意图和情感。最后,我们还利用上下文和语音信息来解决共同引用,ASR错误和实体歧义。
二、分层对话管理器
们还设计了一个基于堆栈的分层对话管理器,以处理用户之间的多种对话。对话管理器首先使用从NLU获得的信息,对用户请求哪个主题(例如电影)做出高层决策。然后,系统激活处理该主题的特定于域的主题对话框模块。在每个主题对话框模块中,我们都有一个预定义的对话流,用于使用户参与更详细和全面的对话。为了适应各种用户行为并保持对话的连贯性,系统可以随时跳入和跳出,以回答事实和个人问题。此外,可以使用在不同域特定主题对话框模块之间创建的隧道来容纳用户的意图切换。
三、应用SSML使语句更类人
为了创建更生动的类人互动,我们使用Amazon的语音合成标记语言(SSML)(例如“ aha”)创建了韵律效果库。通过用户访谈,我们发现人们对这些韵律效果和感叹词认为该系统听起来更自然。
2 Related Work
端到端的方式提高了对话性能。但是,这些方法都存在不连贯和不通用的问题[29]。为了解决这些问题,一些研究将基于规则的方法与端到端的方法相结合[19]。还有一些学者利用个人的技巧和知识图谱[6]。这种方法的组合增强了用户体验并延长了对话时间,但是,它们在适应新领域时不灵活,并且无法有效地处理与意见相关的请求。我们的Gunrock采用了最新的实践,并强调动态的用户对话。该系统充分利用跨不同域和隧道的连接数据集,在主题对话模块之间无缝转换。从用户收集的数据除了用于NLU和自然语言生成(NLG)之外,我们还使用这些数据集训练了模型。
3 Architecture
我们利用了Amazon Conversational Bot Toolkit建立系统架构。该工具包提供了一个zero-effort的扩展框架,使开发人员可以专注于构建用户友好的机器人。基于事件驱动的系统在AWS Lambda function(亚马逊云服务器)之上实现,当用户向机器人发送请求时将触发该系统。 Cobot基础设施还具有一个状态管理器界面,该界面将用户数据和对话框状态信息都存储到DynamoDB(数据库)。我们还利用Redis(远程字典服务)和Amazon新发布的图形数据库Neptune来构建内部系统的知识库。在本节中,我们重点讨论每个系统组件。
3.1 System Overview
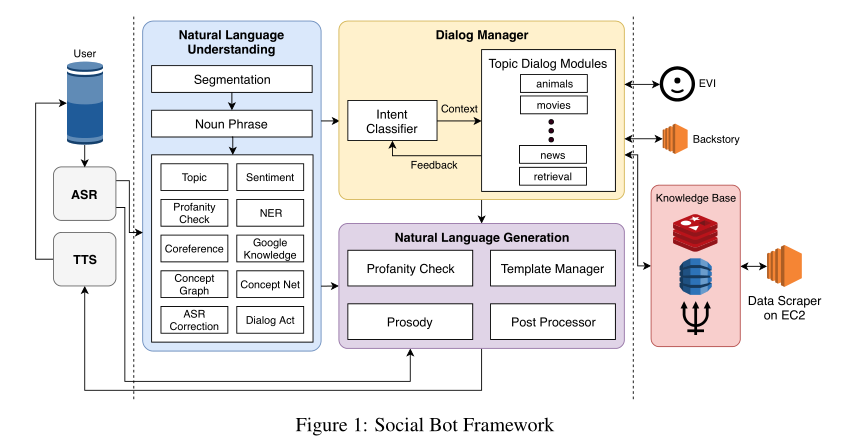
图1描述了bot对话系统框架。通过亚马逊提供的ASR提供用户话语,利用TTS由文本转换成语音。因此我们的系统主要处理文本的输入和输出。由于某些情况可能会产生较长的延迟。例如,如果我们检测到ASR结果中的置信度得分较低,则会生成提示,要求用户直接重复或澄清。通过ASR之后,用户输入将由多个NLU组件处理,例如Amazon工具包服务和对话行为检测器。我们使用Amazon Offensive Speech Classifier工具包来检测令人反感的内容。如果内容显示出不良的迹象,我们会告知用户该主题的不适当之处,并建议其他主题继续对话。
NLU流程涉及三个步骤。首先,将输入语音分为多个句子,然后检测名词短语。最后,名词短语将由图1所示的几个NLP组件进一步分析。在3.3节中,我们将详细讨论NLU组件。在对话框管理器中,意图分类器用于将不同的用户意图定向到相应的主题对话框模块。它们涵盖了几个特定的主题,包括电影,运动,动物等。
每个主题对话框模块都有其自己的对话框流,使用户可以灵活地进行更深入的对话。所有主题对话框模块都使用Amazon的EVI服务来回答事实问题,并通过背景故事来回答与Bot角色相关的问题,例如您最喜欢的颜色是什么?此外,我们使用Amazon EC2实例11从不同来源抓取数据并将其存储在我们的知识库中。来自NLU的所有信息以及上下文信息都用于确定适当的主题对话框模块,该模块调用NLG生成响应。 NLG系统使用模板管理器来集中系统的响应模板。为了确保响应的适当性,我们包括亵渎检查程序以提取响应的内容。 NLG中还包括一个后处理器,用于修改原始主题对话框模块的响应。最后,我们使用Amazon SSML格式化响应的韵律。在以下小节中,我们将详细描述主要的系统块。
3.2 Automatic Speech Recognition
在用户语音通过NLU之前,我们的系统会根据ASR总体置信度得分和每个单词的置信度得分来预设输入语音,以解决和处理ASR错误。我们根据置信度得分范围定义三个ASR错误响应:
•临界范围:如果总体置信度得分和每个单词的置信度得分低于0.1,系统将直接中断整个管道,并要求用户重复或重述其话语或要求。
•警告范围:如果总体置信度得分低于0.4但不在临界范围内,则允许其通过ASR校正,这将在3.3.5节中讨论。
•安全范围:对于其他情况,我们将其定义为安全范围并直接使用ASR结果。我们还会处理用户的意料之外的意图,例如投诉或不完整的话语。在这种情况下,我们意识到仅提供信息作为响应会导致不良的用户体验
3.3 Nature Language Understanding
Alexa Skills Kit(ASK)[12]为NLU提供了话题分类,情绪分析,亵渎检查和NER(命名实体识别)。我们添加了一个句子分割模型,将用户的输入分成语义单元,并对每个语义单元执行NLU。提取名词短语后,我们实现了(命名)实体识别,共同引用,ASR校正和对话行为检测,以支持语言理解。我们按照NLU管道的顺序介绍每种模型的技术细节(第3.1节)。
3.3.1 Sentence Segmentation
我们训练了一种分割模型,以将语音分成具有完整语义含义的较小片段。我们使用康奈尔电影语料库[5]训练了序列模型[24],该序列包含304,713个对话轮和23,760个手动标记的语音(7月29日至7月31日)作为验证集。通过为句子中的中断添加特殊标记来对数据进行预处理。例如,“Alexa that is cool what do you think of the Avengers”被细为
“Alexa <BRK> that is cool <BRK>what do you think of the Avengers <BRK>”
3.3.2 Noun Phrase Extraction(名词短语提取)
我们使用了Stanford CoreNLP选区解析器[15]从输入句子中提取名词短语和局部名词短语(解析树的叶级)。我们过滤了一些停用词(例如全部),并将其余词视为其他NLU模块和选择策略的关键字。在以后的工作中,我们计划使用依赖性解析器来识别主语和宾语,以防出现多个名词短语。
3.3.3 Entity Recognition(实体识别)
•Google知识图谱12:我们使用Google知识图查询名词短语以生成详细描述,置信度得分并将结果缓存到Redis。我们还将描述映射到我们拥有的模块。例如,名词短语“古墓丽影”的标签“视频游戏系列”具有很高的置信度,因此我们可以将其映射到我们的游戏模块。此外,我们提取了多个标签以消除名词短语的歧义(例如“古墓丽影”也可以是电影)。因此,当存在多个具有高置信度得分的标签时,考虑上下文。
•Microsoft概念图13:我们还使用Microsoft概念图对名词短语进行分类。与Google知识图相比,它提供了更通用的类别,可用于分配模块。
•ASR校正:除了使用知识图来获取实体之外,我们还使用ASR校正器,这将在3.3.5节中详细介绍。这对于同音词(听起来相同但拼写不同的词)非常重要。模糊搜索将更可能打出具有相似拼写的词组,但由于语音识别,可能导致选择不正确。使用语音查找匹配项可以提高特定域中NER的准确性。
该部分将以上三种技术并行应用
3.3.4 Coreference Resolution(共指解析:在一短文本内多个表达段指向现实世界中的同一个实体)
Stanford CoreNLP和NeuralCoref 14的最新模型已针对非会话数据进行了训练,因此无法很好地用于回指解析中的对话。
因此,我们将来自请求和NERs的名词短语以及来自系统响应的详细描述存储到用户属性中根据用户指的是什么(例如,人或事件,男性还是女性),我们提供相应的共同推荐解决方案。根据请求,我们分别将来自用户的名词短语和来自我们的响应的NER优先考虑。在以后的工作中,我们计划考虑更多的上下文,并训练一个模型,该模型可以在定义好的优先级之外的选定单词列表中进行确认。
ASR错误对NLU质量有很大影响。 ASK通过合并每个单词的置信度得分和语言模型生成的得分,从而提供总体ASR置信度得分。总体分数表明正确识别整个话语的可能性。但是,当置信度得分较低时,有两种类型的误报可能会触发错误处理,以表示ASR错误。第一个是在训练数据中不经常看到提到的单词时,因此单词的权重较低。误报的另一个实例是同音词,即使用户重复他们的请求,ASR也无法捕获。因此我使用double metaphone算法。我们还根据观察结果在具有某些模式的单词上添加了三级编码如果来自ASR的总体置信度低于某个阈值(设置为0.4),我们通过将名词短语的变音位代码与知识库的变音位代码进行匹配来提出候选词。
3.3.6 Dialog Act Prediction
NLU中的每个分段语句都与一个对话行为相关联。对话行为是给定对话上下文即意见,陈述的对话中的功能。我们训练了LSTM和CNN模型来预测对话行为。前者使用2层的Bi-LSTM模型,使用fastText进行预训练,输入层大小为300,隐藏层大小为500。后者使用2层的CNN模型,也使用fastText进行预训练,卷积核大小为3x3 将其应用在 SWDA数据集(经过处理)上 。我们还在预训时通过练嵌入ELMo [17]和递归卷积神经网络模型[13]来优化模型。
3.3.7 Topic Expansion
除了要求用户共享更多信息并将信息存储在我们的数据库中作为学习过程之外,我们还可以讨论类似的话题。例如,如果用户想谈论汽车,我们可以从ConceptNet检索不同汽车类型的列表(例如Volvo)。因此,在询问了用户喜欢的汽车类型并对对话行为分类的输入进行评论之后(例如,如果用户正在讲故事,观点或提出问题),我们可以扩展到Volvo并从我们的信息库中提取相关信息。、
3.4 Dialog Management
我们创建了一个两级分层对话框管理器来处理用户的对话。高级系统将利用NLU的输出为每个用户请求选择最佳主题对话框模块。之后,低级系统将激活此主题对话框模块以生成响应。
3.4.1 High-Level System Dialog Management
系统首先根据NLU输出识别用户意图,然后与每个子模块的反馈相结合,高级对话管理器决定哪个子模块应处理用户话语。
Intent Classifier(意图分类器):我们基于通用Alexa奖品聊天数据集(CAPC)定义了三个级别的用户意图,CAPC是2017年Alexa奖竞赛中收集的匿名人机对话数据集。我们首先处理社交聊天域系统的请求,例如“播放音乐”,“设置温度”,“开灯”等。对于这些请求,由于我们的社交机器人无法执行任务,因此系统会向用户解释如何退出社交模式,以便他们随后可以使用Alexa内置功能。
Dialog Module Selector(对话框模块选择器):我们的对话模块选择器首先选择一个主题对话模块,该模块负责响应意图分类器检测到的主题意图。为了保持响应的一致性,选定的模块在生成响应后会向系统提供一个称为“ propose_continue”的信号。如果将其设置为“继续”,我们将为用户的下一次发声选择此模块。如果将其设置为“ UNCLEAR”,则仅当我们无法检测到任何其他主题时才选择此模块。如果将其设置为“停止”,则表示它无法处理用户的其他请求,我们的系统不会在下一轮选择此模块。
3.4.2 Low Level Dialog Management
我们构建了两个API,分别是Backstory和EVI,以回答有关聊天机器人的一般事实和背景问题。
•Backstory: 这项服务旨在检索对与聊天机器人的背景和偏好有关的问题的答案,例如“您最喜欢的运动是什么”。我们使用Google的通用句子编码器[4]嵌入用户的问题和我们预先定义的问题。然后,我们获取与该问题相对应的答案,该问题与用户的问题的余弦距离最接近,作为响应。对于每个问题,“背景故事”模块还可以处理用户的进一步请求,例如“您为什么喜欢篮球?”。
•EVI:亚马逊提供的服务。它可以回答一些事实性问题,例如“勒布朗·詹姆斯(Lebron James)多大?”。如果没有相应答案,EVI将返回“我对此没有意见”或“我不知道”。另外,由于有时它会直接返回Alexa技能链接,因此我们对结果进行后处理,而不是直接返回。
3.5 Knowledge Base
我们的知识库由按主题存储在DynamoDB表中的统一数据集组成。数据集来自Reddit,Twitter时刻,辩论意见,IMDB,Spotify等。通过检测匹配的实体将数据集统一在知识图中。我们利用亚马逊的图形数据库Neptune建立实体与Gremlin查询语言23之间的关系以遍历它们。
• Factual Content
Reddit:我们每天从各种子Reddit中收集大量事件。检索到的子目录包括:科学,技术,政治,令人振奋的新闻,新闻,世界新闻,商业新闻,财经新闻,体育,娱乐,时尚新闻,健康,音乐新闻,TIL,ShowerThoughts,旅行。
Twitter:Gunrock中的Twitter时刻旨在帮助用户实时了解世界上正在谈论的话题。随着事件的发生,Gunrock能够谈论电影,书籍,政治,音乐,名人等。
常规信息:有关电影和音乐的常规信息,我们使用IMDB数据库转储“ One Million Playlist dataset”数据集。 该数据集使Gunrock能够过渡到播放列表中的相关艺术家,并了解流行歌曲和艺术家。我们还利用TMDB API和Goodreads API分别检测电影和书名。
•关于意见内容
– Twitter Opinions 我们在Twitter Moment中附带了意见。 Gunrock有机会参与实时事件,使对话更加有趣和有趣。
–Debate Opinions Gunrock尝试使用通用句子编码器将陈述和意见与71,000多个主题和460,000个意见进行匹配[4]。当辩论主题识别的置信度很高,并且在普遍意见共识下,Gunrock将直接回答主题或用户意见。对于观点分歧在40-60分之间的有争议主题,我们要求用户发表意见,并解释说Gunrock仍在形成自己的观点。这提供了一个机会,可以轻而易举地解决两极分化的问题,同时在整个用户之间积累共识。
我们使用OpenIE(开放域知识抽取工具) [1]来统一我们的知识图。它可以自动从纯文本中提取源实体和目标实体之间的二进制关系。这些关系在图形数据库中抽象,并且实体之间的所有事件都存储在DynamoDB中。使用V ADER情感[8](基于规则的情感识别方法)为每个事件分配一个情感分数,这是处理推文和Reddit帖子的理想选择。该情感分数用作知识图的遍历权重。
3.6 Natural Language Generation (NLG)
我们系统的自然语言生成模块是基于模板的。它选择一个手动设计的模板,并使用对话框管理器从知识库中检索到的信息填充特定的位置。模板管理器模块避免重复响应,并生成具有多种表面形式的响应。
我们使用OpenIE [1]来统一我们的知识图。它可以自动从纯文本中提取源实体和目标实体之间的二进制关系。这些关系在图形数据库中抽象,并且实体之间的所有事件都存储在DynamoDB中。使用V ADER情感[8]为每个事件分配一个情感分数,这是处理推文和Reddit帖子的理想选择。该情感分数用作知识图的遍历权重。
3.6.1 Template Manager
模板管理器模块存储并解析系统使用的响应模板。它集中了系统中多个并行对话流组件(例如电影和音乐)中的所有响应模板,确保没有为响应选择重复的模板,并允许按模块指定动态地形成模板。使用模板管理器的主要目标之一是避免重复的响应。我们为每个模板设计了多种表面形式,并且模板管理器确保它们是随机选择的,并且不会在对话中重复出现。这是通过将使用的模板作为哈希存储在每个用户的哈希表中来完成的。例如,我们的电影模块提供了电影有趣的事实,这是通过将从模块数据库中提取的事实填充到我们预先定义的响应模板中来完成的。
3.6.2 Prosody Synthesis
我们的系统利用Amazon Alexa的语音合成系统进行语音合成。我们使用Amazon SSML格式来增强我们的模板,例如在读取电话号码或正确发音同形异义词和首字母缩写词时。另外,我们在10处添加填充符(例如“ whoops”和“ uh-oh”)以及诸如“ Okey dokey ”的标记更像人。我们还会插入暂停符来分解长句子,使它们听起来更自然,并在开玩笑之前添加它们,以建立用户的期望。
4 An Example Dialog

表1给出了一个模拟的示例对话。为了吸引用户,我们的系统以有趣的内容为中心对事实,经验和观点进行了交织。事实向用户提供了有趣的信息。此外,用户可以与我们的机器人交流意见和经验。我们认为拥有观点和经验对于使机器人人性化至关重要。我们还发现确认对于用户参与很重要。对话可以被认为是信息交换的过程,只有当说话者和听者相互理解时,对话才会发生。确认会向用户发送信号,表明该机器人可以理解,并且还充当隐式接地,使用户很容易检测到该机器人被误解了。为了延长对话时间,我们将系统设计为混合计划。如果用户正在请求特定主题或提出问题,我们确保做出适当答复。如果用户对当前主题感兴趣,则系统将继续深入研究。同时,我们的系统也可以采取主动。如果用户没有明确的意图或可采取的行动,则我们的系统将提出一个主题或提出相关问题。
5 Conclusion
我们在口语检测,对话管理和韵律语音合成方面做出了许多贡献。具体来说,我们提出了一个三相口语理解管道来处理开放域口语理解。分层对话管理器,利用对话上下文来实现灵活的对话流,从而无缝地将事实和观点交织在一起;韵律语音合成器通过对音调的调整和填充词插入来构建更自然的响应。
6 Future Work
一、引入推荐系统:我们希望在几个方面改进我们的系统。我们的目标是根据不同用户的个人资料(例如性别,个性和主题兴趣)来改进建议主题的选择,从而为每个用户创建一种适应性和独特的对话体验。为了进一步增强每个用户的独特对话体验,我们将构建一个强大的推荐系统,以针对即将到来的事件或有趣的内容针对不同用户的兴趣提供建议。
二、加入强化学习:我们还计划使用强化学习为子模块选择和对话内容规划训练更好的对话策略。我们希望在用户要求特定目标的帮助(例如,推荐合适的餐厅或旅游景点)时,通过社交交流和面向任务的对话来更好地处理案件。
三、辩论子系统:我们还将构建一个数据驱动的意见回答和主题辩论子系统,这将使我们能够与用户就热门主题进行适当的主观讨论。
四、在线学习:我们还将探索在线学习技术,以使我们的系统从与用户的对话数据中自动学习,尤其是在系统不熟悉的主题上

