

目的
用势函数的概念来确定判别函数和划分类别界面。
基本思想
假设要划分属于两种类别ω1和ω2的模式样本,这些样本可看成是分布在n维模式空间中的点xk。
把属于ω1的点比拟为某种能源点,在点上,电位达到峰值。
随着与该点距离的增大,电位分布迅速减小,即把样本xk附近空间x点上的电位分布,看成是一个势函数K(x, xk)。
对于属于ω1的样本集群,其附近空间会形成一个“高地”,这些样本点所处的位置就是“山头”。
同理,用电位的几何分布来看待属于ω2的模式样本,在其附近空间就形成“凹地”。
只要在两类电位分布之间选择合适的等高线,就可以认为是模式分类的判别函数。
3.9.1 判别函数的产生
模式分类的判别函数可由分布在模式空间中的许多样本向量{xk, k=1,2,…且  }的势函数产生。
}的势函数产生。
任意一个样本所产生的势函数以K(x, xk)表征,则判别函数d(x)可由势函数序列K(x, x1), K(x, x2),…来构成,序列中的这些势函数相应于在训练过程中输入机器的训练模式样本x1,x2,…。
在训练状态,模式样本逐个输入分类器,分类器就连续计算相应的势函数,在第k步迭代时的积累位势决定于在该步前所有的单独势函数的累加。
以K(x)表示积累位势函数,若加入的训练样本xk+1是错误分类,则积累函数需要修改,若是正确分类,则不变。
从势函数可以看出,积累位势起着判别函数的作用 当xk+1属于ω1时,Kk(xk+1)>0;当xk+1属于ω2时,Kk(xk+1)<0,则积累位势不做任何修改就可用作判别函数。
由于一个模式样本的错误分类可造成积累位势在训练时的变化,因此势函数算法提供了确定ω1和ω2两类判别函数的迭代过程。
3.9.2 势函数的选择
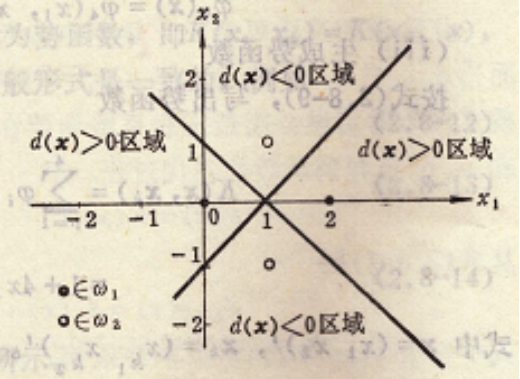
选择势函数的条件:一般来说,若两个n维向量x和xk的函数K(x, xk)同时满足下列三个条件,则可作为势函数。
(1)K(x, xk)= K(xk, x),并且当且仅当x=xk时达到最大值;
(2)当向量x与xk的距离趋于无穷时,K(x, xk)趋于零;
(3)K(x, xk)是光滑函数,且是x与xk之间距离的单调下降函数。

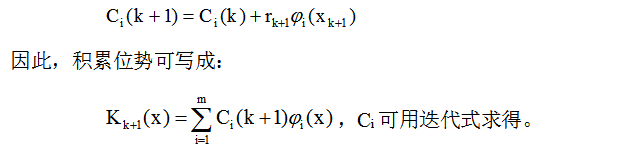


势函数法
实例1:用第一类势函数的算法进行分类






实例2:用第二类势函数的算法进行分类

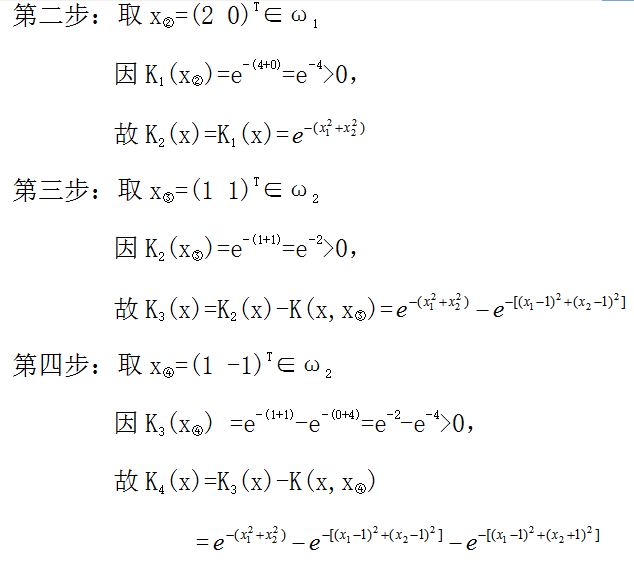


讨论
用第二类势函数,当训练样本维数和数目都较高时,需要计算和存储的指数项较多。 正因为势函数由许多新项组成,因此有很强的分类能力。


本文来自博客园,作者:Charlie_ODD,转载请注明原文链接:https://www.cnblogs.com/chihaoyuIsnotHere/p/9790506.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· 地球OL攻略 —— 某应届生求职总结