

1- 线性回归
2 - 逻辑回归
3 - 线性判别分析
4 - 决策树
5 - 随机森林算法
6 - SVM
7 - 朴素贝叶斯
8 - K最近邻算法
9 - K均值算法
10-Adaboost 算法
11--马尔可夫
1- 线性回归
预测建模主要关注的是如何最小化模型的误差,或是如何在一个可解释性代价的基础上做出最为准确的预测。线性回归所表示的是描述一条直线的方程,通过输入变量的特定权重系数(B)来找出输入变量(x)和输出变量(y)之间最适合的映射关系。
例如:y = B0 + B1 * x
给定输入x,我们可以预测出y的值。线性回归学习算法的目标是找到系数B0和B1的值。
2 - 逻辑回归
用于解决二元分类问题(有两个类值的问题)。逻辑回归的函数图像看起来是一个大的S形,并将任何值转换至0到1的区间。这种形式非常有用,因为我们可以用一个规则把逻辑函数的值转化成0和1(例如,如果函数值小于0.5,则输出1),从而预测类别。当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。


这个模型需要满足两个条件 大于等于0,小于等于1
大于等于0 的模型可以选择 绝对值,平方值,这里用 指数函数,一定大于0
小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了




3 - 线性判别分析
LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“投影后类内方差最小,类间方差最大”。什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
可能还是有点抽象,我们先看看最简单的情况。假设我们有两类数据 分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
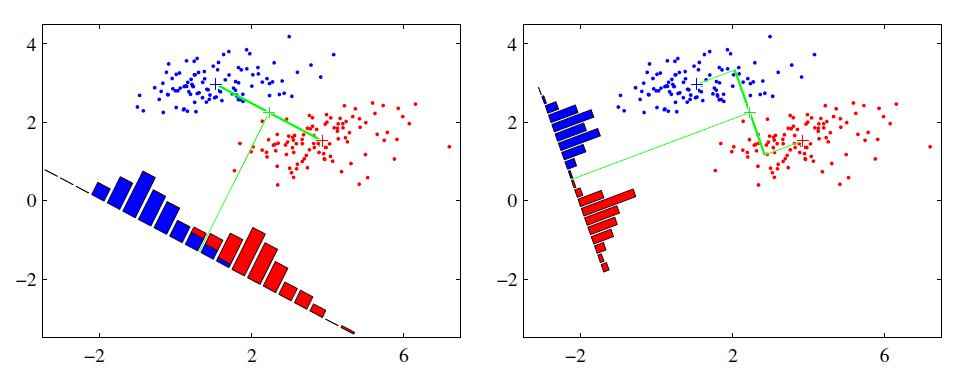
上图中提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,我们的数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
4 - 决策树
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。

5. 随机森林
在源数据中随机选取数据,组成几个子集

S 矩阵是源数据,有 1-N 条数据,A B C 是feature,最后一列C是类别

由 S 随机生成 M 个子矩阵

这 M 个子集得到 M 个决策树
将新数据投入到这 M 个树中,得到 M 个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果

6 - SVM
support vector machine
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好

将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1

点到面的距离根据图中的公式计算

所以得到 total margin 的表达式如下,目标是最大化这个 margin,就需要最小化分母,于是变成了一个优化问题



a 和 w0 代入超平面的方程就是 support vector machine
7 - 朴素贝叶斯
举个在 NLP 的应用
给一段文字,返回情感分类,这段文字的态度是positive,还是negative

为了解决这个问题,可以只看其中的一些单词

这段文字,将仅由一些单词和它们的计数代表

原始问题是:给你一句话,它属于哪一类
通过 bayes rules 变成一个比较简单容易求得的问题

问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率
栗子:单词 love 在 positive 的情况下出现的概率是 0.1,在 negative 的情况下出现的概率是 0.001

8 - K最近邻算法
k nearest neighbours
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类
栗子:要区分 猫 和 狗,通过 claws 和 sound 两个feature来判断的话,圆形和三角形是已知分类的了,那么这个 star 代表的是哪一类呢

k=3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个star就是属于猫

k近邻算法是非常特殊的,可以被认为是没有模型的算法,为了和其他算法统一,可以认为训练数据集就是模型本身
9 - K均值算法
想要将一组数据,分为三类,粉色数值大,黄色数值小
最开心先初始化,这里面选了最简单的 3,2,1 作为各类的初始值
剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别

分好类后,计算每一类的平均值,作为新一轮的中心点

几轮之后,分组不再变化了,就可以停止了


10-Adaboost 算法
adaboost 是 bosting 的方法之一
bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度

adaboost 的栗子,手写识别中,在画板上可以抓取到很多 features,例如 始点的方向,始点和终点的距离等等

training 的时候,会得到每个 feature 的 weight,例如 2 和 3 的开头部分很像,这个 feature 对分类起到的作用很小,它的权重也就会较小

而这个 alpha 角 就具有很强的识别性,这个 feature 的权重就会较大,最后的预测结果是综合考虑这些 feature 的结果

11-马尔可夫
Markov Chains 由 state 和 transitions 组成
栗子,根据这一句话 ‘the quick brown fox jumps over the lazy dog’,要得到 markov chain
步骤,先给每一个单词设定成一个状态,然后计算状态间转换的概率

这是一句话计算出来的概率,当你用大量文本去做统计的时候,会得到更大的状态转移矩阵,例如 the 后面可以连接的单词,及相应的概率

生活中,键盘输入法的备选结果也是一样的原理,模型会更高级

你应该使用哪种机器学习算法?
这在很大程度上依赖于可用数据的性质和数量以及每一个特定用例中你的训练目标。不要使用最复杂的算法,除非其结果值得付出昂贵的开销和资源。这里给出了一些最常见的算法,按使用简单程度排序。
1. 决策树(Decision Tree):在进行逐步应答过程中,典型的决策树分析会使用分层变量或决策节点,例如,可将一个给定用户分类成信用可靠或不可靠。
优点:擅长对人、地点、事物的一系列不同特征、品质、特性进行评估
场景举例:基于规则的信用评估、赛马结果预测
2. 支持向量机(Support Vector Machine):基于超平面(hyperplane),支持向量机可以对数据群进行分类。
优点:支持向量机擅长在变量 X 与其它变量之间进行二元分类操作,无论其关系是否是线性的
场景举例:新闻分类、手写识别
3. 回归(Regression):回归可以勾画出因变量与一个或多个因变量之间的状态关系。在这个例子中,将垃圾邮件和非垃圾邮件进行了区分。
优点:回归可用于识别变量之间的连续关系,即便这个关系不是非常明显
场景举例:路面交通流量分析、邮件过滤
4. 朴素贝叶斯分类(Naive Bayes Classification):朴素贝叶斯分类器用于计算可能条件的分支概率。每个独立的特征都是「朴素」或条件独立的,因此它们不会影响别的对象。例如,在一个装有共 5 个黄色和红色小球的罐子里,连续拿到两个黄色小球的概率是多少?从图中最上方分支可见,前后抓取两个黄色小球的概率为 1/10。朴素贝叶斯分类器可以计算多个特征的联合条件概率。
优点:对于在小数据集上有显著特征的相关对象,朴素贝叶斯方法可对其进行快速分类
场景举例:情感分析、消费者分类
5. 隐马尔可夫模型(Hidden Markov model):显马尔可夫过程是完全确定性的——一个给定的状态经常会伴随另一个状态。交通信号灯就是一个例子。相反,隐马尔可夫模型通过分析可见数据来计算隐藏状态的发生。随后,借助隐藏状态分析,隐马尔可夫模型可以估计可能的未来观察模式。在本例中,高或低气压的概率(这是隐藏状态)可用于预测晴天、雨天、多云天的概率。
优点:容许数据的变化性,适用于识别(recognition)和预测操作
场景举例:面部表情分析、气象预测
6. 随机森林(Random forest):随机森林算法通过使用多个带有随机选取的数据子集的树(tree)改善了决策树的精确性。本例在基因表达层面上考察了大量与乳腺癌复发相关的基因,并计算出复发风险。
优点:随机森林方法被证明对大规模数据集和存在大量且有时不相关特征的项(item)来说很有用
场景举例:用户流失分析、风险评估
7. 循环神经网络(Recurrent neural network):在任意神经网络中,每个神经元都通过 1 个或多个隐藏层来将很多输入转换成单个输出。循环神经网络(RNN)会将值进一步逐层传递,让逐层学习成为可能。换句话说,RNN 存在某种形式的记忆,允许先前的输出去影响后面的输入。
优点:循环神经网络在存在大量有序信息时具有预测能力
场景举例:图像分类与字幕添加、政治情感分析
8. 长短期记忆(Long short-term memory,LSTM)与门控循环单元神经网络(gated recurrent unit nerual network):早期的 RNN 形式是会存在损耗的。尽管这些早期循环神经网络只允许留存少量的早期信息,新近的长短期记忆(LSTM)与门控循环单元(GRU)神经网络都有长期与短期的记忆。换句话说,这些新近的 RNN 拥有更好的控制记忆的能力,允许保留早先的值或是当有必要处理很多系列步骤时重置这些值,这避免了「梯度衰减」或逐层传递的值的最终 degradation。LSTM 与 GRU 网络使得我们可以使用被称为「门(gate)」的记忆模块或结构来控制记忆,这种门可以在合适的时候传递或重置值。
优点:长短期记忆和门控循环单元神经网络具备与其它循环神经网络一样的优点,但因为它们有更好的记忆能力,所以更常被使用
场景举例:自然语言处理、翻译
9. 卷积神经网络(convolutional neural network):卷积是指来自后续层的权重的融合,可用于标记输出层。
优点:当存在非常大型的数据集、大量特征和复杂的分类任务时,卷积神经网络是非常有用的
场景举例:图像识别、文本转语音、药物发现
本文来自博客园,作者:Charlie_ODD,转载请注明原文链接:https://www.cnblogs.com/chihaoyuIsnotHere/p/9530899.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界