

在我们机器学习或者训练深度神经网络的时候经常会出现欠拟合和过拟合这两个问题,但是,一开始我们的模型往往是欠拟合的,也正是因为如此才有了优化的空间,我们需要不断的调整算法来使得模型的表达能拿更强。但是优化到了一定程度就需要解决过拟合的问题了,这个问题也在学术界讨论的比较多。
首先就是我们在进行模型训练的时候会出现模型不能够很好地拟合数据的情况,这个时候就需要我们来判断究竟现在的模型是欠拟合还是过拟合,那么怎么来判断这两者的情况呢?有两种方法:
首先看一下三种误差:
- training error
- cross validation(验证) error
- test error
1)学习曲线(learning curves)
学习曲线就是比较 j_train 和 j_cv。如下图所示,为一般的学习曲线,蓝色的线表示训练集上的误差 j_train, 粉色的线表示验证集上的误差 j_cv,横轴表示训练集合的大小。
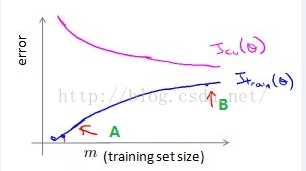
刚开始处于 “A” 点,表示当训练数据很小时,很容易时训练集上的误差非常小,此时处于过拟合状态。随着训练数据的增加,训练数据上的误差 J_train 越来越大,而验证集上的误差 J_cv 越来越小,J_train 和 J_cv 越来越接近但始终保持 J_cv > J_train.
2)交叉验证(cross-validation)
这里首先解释一下bias和variance的概念。模型的Error = Bias + Variance,Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
我们可以根据j_cv 与 j_train两个来判断是处于欠拟合还是过拟合。
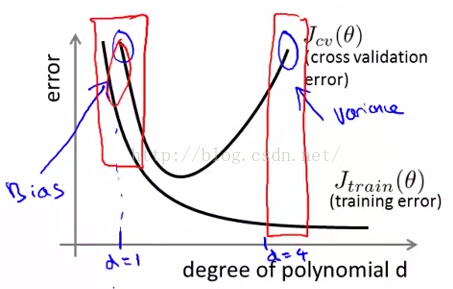
当观察到 J_cv 很大时,可能处在途中蓝色圆圈中的两个位置,虽然观察到的现象很相似(J_cv都很大),但这两个位置的状态是非常不同的,处理方法也完全不同。
- 当cross validation error (Jcv) 跟training error(Jtrain)差不多,且Jtrain较大时,即图中标出的bias,此时 high bias low variance,当前模型更可能存在欠拟合。
- 当Jcv >> Jtrain且Jtrain较小时,即图中标出的variance时,此时 low bias high variance,当前模型更可能存在过拟合。
1. 欠拟合
首先欠拟合就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据,例如下面的例子:

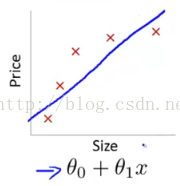
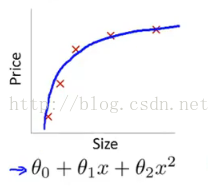
左图表示size与prize关系的数据,中间的图就是出现欠拟合的模型,不能够很好地拟合数据,如果在中间的图的模型后面再加一个二次项,就可以很好地拟合图中的数据了,如右面的图所示。
解决方法:
1)添加其他特征项,有时候我们模型出现欠拟合的时候是因为特征项不够导致的,可以添加其他特征项来很好地解决。例如,“组合”、“泛化”、“相关性”三类特征是特征添加的重要手段,无论在什么场景,都可以照葫芦画瓢,总会得到意想不到的效果。除上面的特征之外,“上下文特征”、“平台特征”等等,都可以作为特征添加的首选项。
2)添加多项式特征,这个在机器学习算法里面用的很普遍,例如将线性模型通过添加二次项或者三次项使模型泛化能力更强。例如上面的图片的例子。
3)减少正则化参数,正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
2. 过拟合
通俗一点地来说过拟合就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差。例如下面的例子。

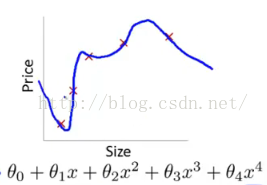
上面左图表示size和prize的关系,我们学习到的模型曲线如右图所示,虽然在训练的时候模型可以很好地匹配数据,但是很显然过度扭曲了曲线,不是真实的size与prize曲线。
解决方法:
1)重新清洗数据,导致过拟合的一个原因也有可能是数据不纯导致的,如果出现了过拟合就需要我们重新清洗数据。
2)增大数据的训练量,还有一个原因就是我们用于训练的数据量太小导致的,训练数据占总数据的比例过小。
3)采用正则化方法。正则化方法包括L0正则、L1正则和L2正则,而正则一般是在目标函数之后加上对于的范数。但是在机器学习中一般使用L2正则,下面看具体的原因。
L0范数是指向量中非0的元素的个数。L1范数是指向量中各个元素绝对值之和,也叫“稀疏规则算子”(Lasso regularization)。两者都可以实现稀疏性,既然L0可以实现稀疏,为什么不用L0,而要用L1呢?个人理解一是因为L0范数很难优化求解(NP难问题),二是L1范数是L0范数的最优凸近似,而且它比L0范数要容易优化求解。所以大家才把目光和万千宠爱转于L1范数。
L2范数是指向量各元素的平方和然后求平方根。可以使得W的每个元素都很小,都接近于0,但与L1范数不同,它不会让它等于0,而是接近于0。L2正则项起到使得参数w变小加剧的效果,但是为什么可以防止过拟合呢?一个通俗的理解便是:更小的参数值w意味着模型的复杂度更低,对训练数据的拟合刚刚好(奥卡姆剃刀),不会过分拟合训练数据,从而使得不会过拟合,以提高模型的泛化能力。还有就是看到有人说L2范数有助于处理 condition number不好的情况下矩阵求逆很困难的问题(具体这儿我也不是太理解)。
4)采用dropout方法。这个方法在神经网络里面很常用。dropout方法是ImageNet中提出的一种方法,通俗一点讲就是dropout方法在训练的时候让神经元以一定的概率不工作。具体看下图:
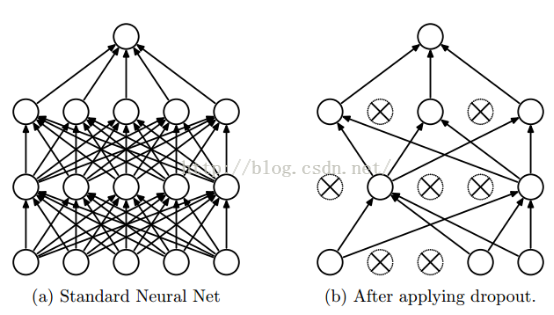
如上图所示,左边a图是没用用dropout方法的标准神经网络,右边b图是在训练过程中使用了dropout方法的神经网络,即在训练时候以一定的概率p来跳过一定的神经元。
本文来自博客园,作者:Charlie_ODD,转载请注明原文链接:https://www.cnblogs.com/chihaoyuIsnotHere/p/9506374.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· 地球OL攻略 —— 某应届生求职总结