

---恢复内容开始---
一、大数据时代的现状
据统计,YouTube上每分钟就会增加500多小时的视频,面对如此海量的数据,如何高效的存储与处理它们就成了当前最大的挑战。
但在这个对硬件要求越来越高的时代,CPU却似乎并不这么给力了。自2013年以来,处理器频率的增长速度逐渐放缓了,目前CPU的频率主要分布在3~4GHz。实际上CPU与频率是于能耗密切相关的,我们之前可以通过加电压来提升频率,但当能耗太大,散热问题就无法解决了,所以频率就逐渐稳定下来了,而Intel与AMD等大制造商也将目标转向了多核芯片,目前普通桌面PC也达到了4~8核。
随着集成电路上的晶体管数据量越来越多,功耗的增加以及过热问题,使得在集成电路上增加更多的晶体管变得更加困难,摩尔定律所预言的指数增长必定放缓。因此,摩尔定律失效。
当前和未来五年,微处理器技术朝着多核方向发展,充分利用摩尔定律带来的芯片面积,放置多个微处理器内核,以及采用更加先进的技术降低功耗。
当然,多核并行计算不仅仅可以使用CPU,而且还可以使用GPU(图形处理器),一个GPU有多大上千个核心,可以同时运行上千个线程。那怎么利用GPU做并行计算呢?可以使用英伟达的CUDA库。
什么时候用并行计算?
多核CPU——计算密集型任务:尽量使用并行计算,可以提高任务执行效率。计算密集型任务会持续地将CPU占满,此时有越多CPU来分担任务,计算速度就会越快,这种情况才是并行程序的用武之地。
什么是并行计算
并行计算是相对于串行计算而言,比如一个矩阵相乘的例子,下面给出串行程序的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | void matrixMultiplication(int a[][SIZE], int b[][SIZE]){ int i,j,k; for(i = 0; i < c_row; i++) { for(j = 0; j < c_col; j++) { for(k = 0; k < a_col; k++) { c[i][j] += a[i][k] * b[k][j]; } } }} |
在上面的程序中,程序编译运行之后以一个进程(注意区分进程和线程这两个概念)的方式是按照for循环迭代顺序执行。那怎么并行矩阵相乘的代码呢?这里需要使用高级语言级别的并行库,常见的并行库有opemp,pthread,MPI,CUDA等,这些并行库一般都支持C/C++,程序员可以直接调用并行库的函数而不需要实现底层的CPU多核调用。下面给出opemmp版本的矩阵相乘程序。

void matrixMultiplication(int a[][SIZE], int b[][SIZE]) { int i,j,k; #pragma omp parallel shared(a,b,c) private(i,j,k) { #pragma omp for schedule(dynamic) for(i = 0; i < c_row; i++) { for(j = 0; j < c_col; j++) { for(k = 0; k < a_col; k++) { c[i][j] += a[i][k] * b[k][j]; } } } } }
opemmp在没有改动原本代码的基础上实现了矩阵相乘的并行化,实现的办法仅仅是添加了两条openmp编译制导语句,在程序运行到并行代码时,程序的主线程会启动多线程把任务分成n份(n=CPU核心数),然后在多核心上同时计算,最后主线程得到结果。当然除了多线程,程序也可以启动多进程进行并行计算,关于多进程,Linux下的fork()想必很多人都有了解,而mpich是目前很流行的多进程消息传递库。并行化看起来很简单不是么,但是,要设计高效能解决复杂问题的并行程序可不那么容易。
并行程序的评价指标
评价并行计算程序效率,不单单从并行程序的执行时间来考虑,而是从与串行程序的对比来去评价。最常用的指标是加速比(speedup)
加速比=串行执行时间/并行执行时间
还有效率
效率=加速比/处理器个数
以及成本
成本=并行执行时间×所用处理器的数目
举个例子:用N个处理器计算N个数的和(N为2的整数次幂)
- 串行计算需要
O(N)的时间 - 并行方法:每个处理器获得一个数,两个处理器之一将其叠加,递归上述步骤。需要
O(logN)的时间 - 加速比
S = O(N/logN) - 成本
C = O(N*logN)
并行程序设计模型/技术
- 数据并行(Data Parallel)模型:将相同的操作同时作用于不同数据,只需要简单地指明执行什么并行操作以及并行操作对象。该模型反映在图一中即是,并行同时在主线程中拿取数据进行处理,并线程执行相同的操作,然后计算完成后合并结果。各个并行线程在执行时互不干扰。
- 消息传递(Message Passing)模型:各个并行执行部分之间传递消息,相互通讯。消息传递模型的并行线程在执行时会传递数据,可能一个线程运行到一半的时候,它所占用的数据或处理结果就要交给另一个线程处理,这样,在设计并行程序时会给我们带来一定麻烦。该模型一般是分布式内存并行计算机所采用方法,但是也可以适用于共享式内存的并行计算机。
目前常见的并行编程技术包括:MPI、OPENMP、OPENCL、OPENGL、CUDA。下面了解一下这些常见并行编程技术的基础概念:

(1)MPI
MPI(Message Passing Interface)是一种广泛采用的基于消息传递的并行编程技术。MPI消息传递接口是一种编程接口标准,而不是一种具体的编程语言。简而言之,MPI标准定义了一组具有可移植性的编程接口。各个厂商或组织遵循这些标准实现自己的MPI软件包,典型的实现包括开放源代码的MPICH、LAM MPI以及不开放源代码的Intel MPI。由于MPI提供了统一的编程接口,程序员只需要设计好并行算法,使用相应的MPI库就可以实现基于消息传递的并行计算。MPI支持多种操作系统,包括大多数的类UNIX和Windows系统。
(2)OpenMP
OpenMP用于共享内存并行系统的多线程程序设计的一套指导性的编译处理方案(Compiler Directive)。OpenMP支持的编程语言包括C语言、C++和Fortran;而支持OpenMp的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。
OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的#pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些#pragma,或者编译器不支持OpenMP时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
(3)OpenCL
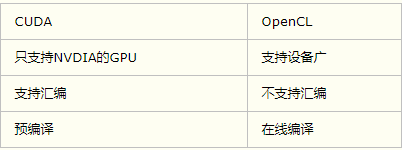
OpenCL(Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
OpenCL是一个为异构平台编写程序的框架,此异构平台可由CPU,GPU或其他类型的处理器组成。OpenCL由一门用于编写kernels (在OpenCL设备上运行的函数)的语言(基于C99)和一组用于定义并控制平台的API组成。OpenCL提供了基于任务分割和数据分割的并行计算机制。OpenCL类似于另外两个开放的工业标准OpenGL和OpenAL,这两个标准分别用于三维图形和计算机音频方面。OpenCL扩展了GPU用于图形生成之外的能力。OpenCL由非盈利性技术组织Khronos Group掌管。
(4)OpenGL
OpenGL(Open Graphics Library)是个定义了一个跨编程语言、跨平台的编程接口规格的专业的图形程序接口。它用于三维图象(二维的亦可),是一个功能强大,调用方便的底层图形库。
(5)CUDA
CUDA(Compute Unified Device Architecture)是一种由显卡厂商NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员现在可以使用C语言来为CUDA™架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序于是就可以在支持CUDA™的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
改用GPU处理计算密集型程序
GPU即图形处理器核心(Graphics Processing Unit),它是显卡的心脏,显卡上还有显存,GPU与显存类似与CPU与内存。
GPU与CPU有不同的设计目标,CPU需要处理所有的计算指令,所以它的单元设计得相当复杂;而GPU主要为了图形“渲染”而设计,渲染即进行数据的列处理,所以GPU天生就会为了更快速地执行复杂算术运算和几何运算的。
GPU相比与CPU有如下优势:
- 强大的浮点数计算速度。
- 大量的计算核心,可以进行大型并行计算。一个普通的GPU也有数千个计算核心。
- 强大的数据吞吐量,GPU的吞吐量是CPU的数十倍,这意味着GPU有适合的处理大数据。
GPU目前在处理深度学习上用得十分多,英伟达(NVIDIA)目前也花大精力去开发适合深度学习的GPU。现在上百层的神经网络已经很常见了,面对如此庞大的计算量,CPU可能需要运算几天,而GPU却可以在几小时内算完。
本文来自博客园,作者:Charlie_ODD,转载请注明原文链接:https://www.cnblogs.com/chihaoyuIsnotHere/p/11384731.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界
2018-08-20 欠拟合、过拟合及其解决方法
2018-08-20 机器学习的种类及其典型的任务
2018-08-20 27种神经网络模型