

CDH升级到CDP大数据集群碰到的问题解析
一、背景
2019 年,Cloudera 与 Hortonworks 合并后,彻底完成了转型。Cloudera 果断宣布,对 CDH 和 HDP 两条产品线将仅支持到 2022 年。对于两个产品高度重合的部分会做删减和融合,结果就是推出新的数据平台 CDP (Cloudera Data Platform)。2022 年后,原 CDH 和 HDP 用户会被转移到 CDP 上 。与CDH不同,CDP也将大数据相关的组件提生到了3.x版本。而改动最大的要数Hive组件了,而性能也比之前CDH引入的2.x的版本提升了很多。因此,现在数据量比较大的基金公司都已经将CDH升级到CDP列入了本年度计划之内,下面针对使用CDP的hive过程中碰到的问题进行深度解析并给出解决方法。
二、使用Hive的3.x版本碰到的问题
2.1 Hive支持引擎的异同
问题描述:CDP平台设置mr或者spark引擎执行作业会失败。
引起原因:不同于CDH支持hive on mr 和hive on spark执行引擎,通过手动配置并引入tez组件也可以支持hive on tez执行引擎。CDP对hive的执行引擎进行了限制,默认只支持hive on tez执行引擎。设置mr引擎会报错不支持。截图如下:

图2-1 设置mr引擎失败
设置hive on spark执行引擎,虽然可以设置,但是执行作业会报错,并执行失败

图2-2 设置spark引擎执行作业失败
解决方法:在向cdp大数据中平台提交作业时,只使用hive on Tez执行引擎。
2.2 连接HiveServer2实例的异同
问题描述:连接Hive的hiveserver2实例可以访问全表,但是执行复杂sql,涉及到shuffle操作时,任务执行失败。
引起原因:不同于CDH直接使用Hive的hiveserver2实例便可以操作hive。CDP需要安装Hive、TEZ和Hive on Tez三个组件。Hive on Tez就像一座桥梁一样,把Hive和TEZ两个组件连接起来。
其中Hive和Hive on Tez有各自不同的hiveserver2实例和端口,比较坑的是Hive的hiveserver2和Hive on Tez的端口在CDP上默认都是一样的,如果仅仅使用CDP默认的方式安装,安装没有问题,使用起来的时候就会报端口冲突,需要修改Hive on Tez的hiveserver2的默认端口。并且连接Hive的hiveserver2实例时,并不能使用Tez引擎,如果执行的sql是全表扫描,没以后shuffle操作,作业不会报错;当涉及shuffle操作时就需要使用执行引擎进行数据处理了,此时会报错没有可用的执行引擎或者没有处理权限。
报错截图示例如下:

图2-3直接使用Hive的示例报错示意图
因此,需要使用Hive on Tez的hivesever2实例才可以正常操作和处理Hive中的数据。而CDH中官方不支持Hive on Tez执行引擎,没有这个问题。Hive的hiveserver2实例和Hive on Tez的hiveserver2端口对比如下:
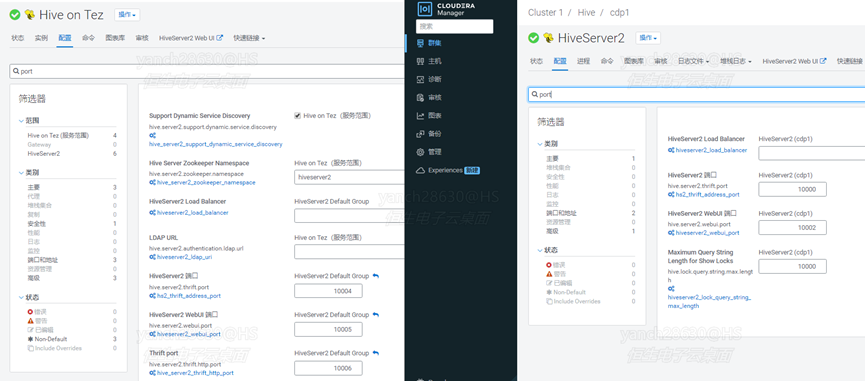
图2-4 hive和hive on tez的hiveserver2实例端口比较示意图
解决方法:连接hiveserver2实例时,使用Hive on Tez组件,不要使用Hive组件的实例。
2.3 设置Hive事物表参数的异同
问题描述:不支持修改CDP的Hive的事物表参数hive.support.concurrency和hive.txn.manager。
引起原因:不同于CDH,CDP大数据平台使用的是Hive3.x的版本,hive从3.0版本以后,默认创建的表格都是事务表并支持修改和删除功能,并且默认将事物表参数设置为固定默认值hive.support.concurrency=true;
和hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;使用Java程序连接hiveserver2,在执行sql时修改这两个参数会直接报错,不支持在sql执行时修改该参数。报错视图如下:

图2-5 修改事物表参数报错
解决方法:不要修改事物表的相关参数,直接使用默认值即可。
2.4 Hive创建表类型的异同
问题描述:Spark执行引擎不能直接操作Hive的内部事物表,通过Sparksql创建的都是外部表。
引起原因:不同于CDH,CDP大数据平台hive默认创建的是内部事物表。Sparksql是没有事物的概念,因此不能直接操作Hive的事物表。需要借助第三方工具Quoble,通过Hive的acid方式读写Hive的事务表。CDP官方提供的Quoble有缺陷,直接集成到sparksql使用,可以读写表格数据,但是无法删除表格。究其原因是因为Quoble在读写hive数据的时候通过hive的metastore开通的read锁,但是操作表格结束后,没有关闭该锁,导致表格无法删除。截图如下:

图2-6 sparksql读写表未关闭的hive读锁示意图
解决方法:在sparksql读写Hive的内部事物表时,需要集成Cloudera的jar包,同时设置spark.acid.start.local.txn=true;设置该参数相当于开启了本地事务,sparksql会在作业执行完毕之后,关闭Hive的事务锁。Spark-acid的源码截图如下:
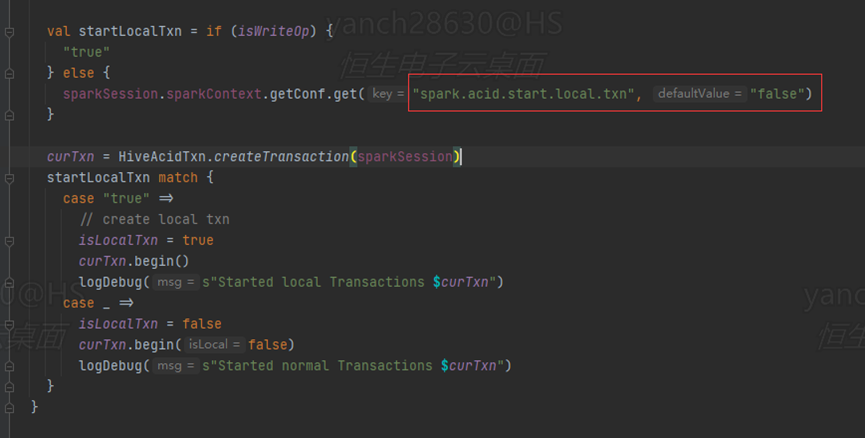
图2-7 sparksql默认未使用local事务截图
2.5 Hive设置任务执行队列的异同
问题描述:使用mapred.job.queue.name参数设置cdp的任务执行队列,不生效,yarn还是使用默认的default。
引起原因:不同于CDH使用mapred.job.queue.name参数可以设置mr或者spark的yarn任务执行队列。CDP中默认使用的TEZ执行引擎有自己独立的参数tez.queue.name来设置任务执行队列。离线计算执行任务设置队列示意图如下:
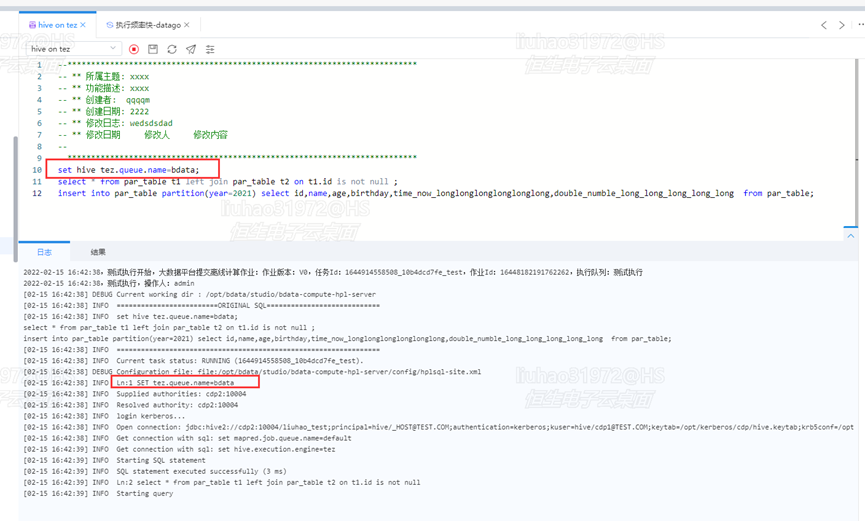
图2-8 设置tez的yarn任务执行队列示意图
观察CDP的yarn组件,任务队列设置生效示意图如下:
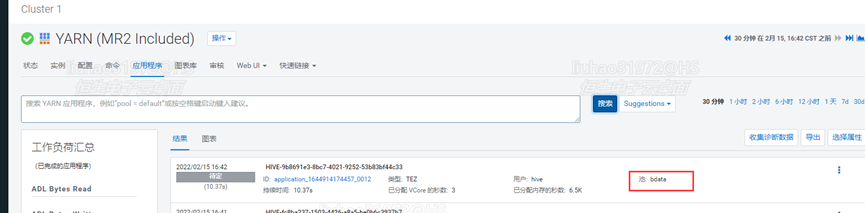
图2-9 设置tez的yarn任务执行队列示意图
解决方法:当使用hive on tez执行引擎时,使用tez特有的参数tez.queue.name来设置任务执行队列。
2.6 Hive的count函数的异同
问题描述:使用Sparksql写入的数据,Sparksql使用count函数与Hive on Tez使用count函数统计的值不一致。
引起原因:在CDP平台中使用Hive on Tez执行引擎插入的数据,该引擎会统计数据量总数的变化并实时更新记录。而通过其他引擎写入的数据则没有这个功能。Hive on Tez在执行count函数的时候没有走shuffle过程,直接从统计的结果中获取过来了统计结果。因此通过就会造成Sparksql写入的数据通过select count(*) from tableName;查出来的结果和Hive on tez查出的结果就不一样。
解决方法:根据业务场景,如果有其他作业使用了非Hive on Tez执行引擎插入了数据;在使用“select count(*) from tableName;”语法时,可以先使用“analyze table tableName compute statistics;”语法对表重新更新统计信息,这样重新统计后结果就是正确的了。
三、总结
相对CDH而言,CDP的大数据组件都有很大的改动,各个大数据组件基本上都升级到了3.0以上的版本,需要具体了解各个组件比如Hive、Hadoop、Spark等新增的新特性才能更好的使用CDP。

