

解析集群中Hive作业返回错误码释义以及解决方法
一、背景
作为大数据常用的组件Hive,其在执行作业异常时会返回一些错误码。但是,hive返回的错误概括性比较强,往往看不出来具体的信息,需要进入到集群中查看详细的yarn执行日志或者hiveserver2的日志才能定位出具体的原因。
本文针对客户生产环境中常见的Hive返回的错误码进行释义,并提出具体的解决思路和方法。
二、Hive日志的查找方法
2.1 Hive执行作业时报错查找日志方法
当作业已经提交到集群并能在yarn上看到具体的作业信息时,可以通过通过如下步骤查找作业的执行日志
- 点击集群按钮找到yarn组件,如图2-1所示;
- 然后查看yarn上正在执行的或者已经执行完毕的作业;
- 点击具体的application编号,然后查看详细的作业日志。
- 点击here查看完整的执行日志,如图2-2所示。
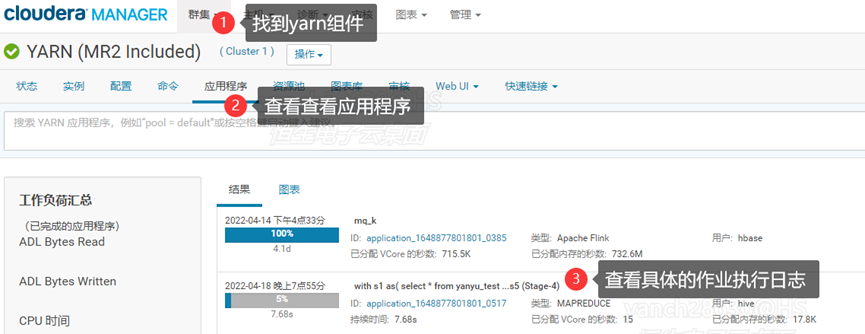
图2-1 yarn中hive执行日志定位方法
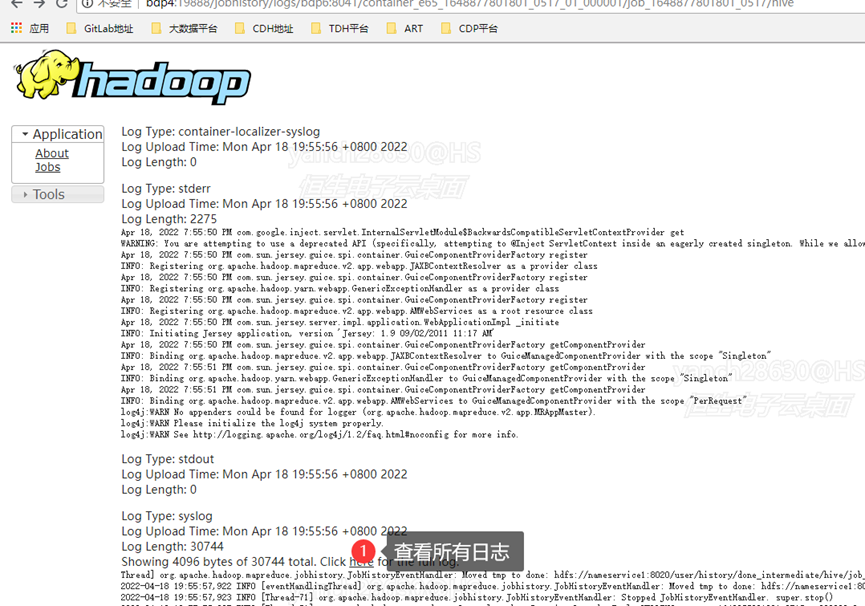
图2-2 查看详细日志方法
2.2 作业还未执行时便报错日志查找方法
如果作业还没有提交到yarn上便报错了,这时一般是由于hiveserver2的元数据信息有问题导致的,这时边需要查看hivesever2的日志了。具体步骤如下:
- 点击集群按钮,找到hive组件;
- 点击配置按钮,查看log日志目录;
- 输入配置名称log,查看hiveserver2的日志记录目录,如下图2-3所示;
- 登录到集群,下载hivesever2的日志;如下图2-4所示。
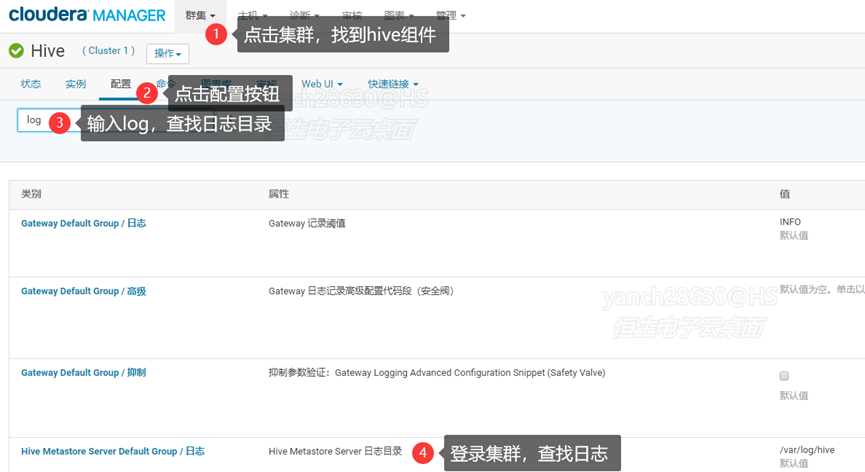
图2-3 集群定位hiveserver日志目录方法
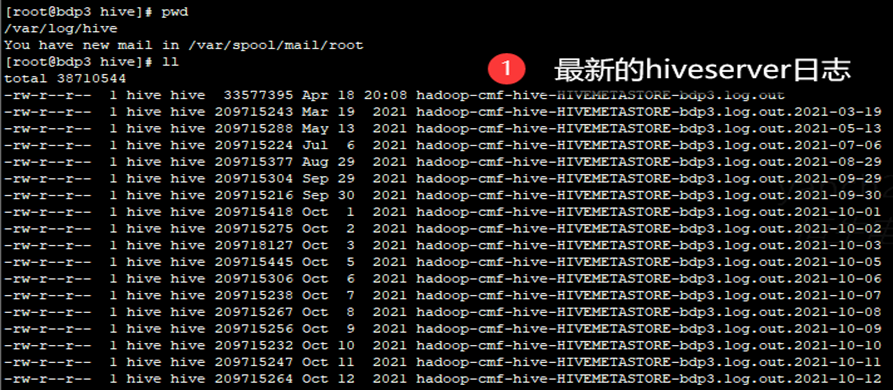
图2-4 shell中下载hiveserver2日志
三、Hive中常见错误码以及问题解决方法
3.1 Hive的错误码recode 1
当Hive返回recode 1时,作业一般还没有在yarn上执行就报错了,这种错误往往是hive的元数据出错导致的,需要查看hiveserver2的信息。示例如下:
问题描述:用户执行sql insert overwrite table hdp_dw.dwd_pty_pd_ast_df partition(pt_sys_src = 'YSS_FA_25', pt_date = '20220101' ) select xx from xxx;时报错:
FAILED:Execution Error, return code 1 from
org.apache.hadoop.hive.ql.exec.MoveTask.
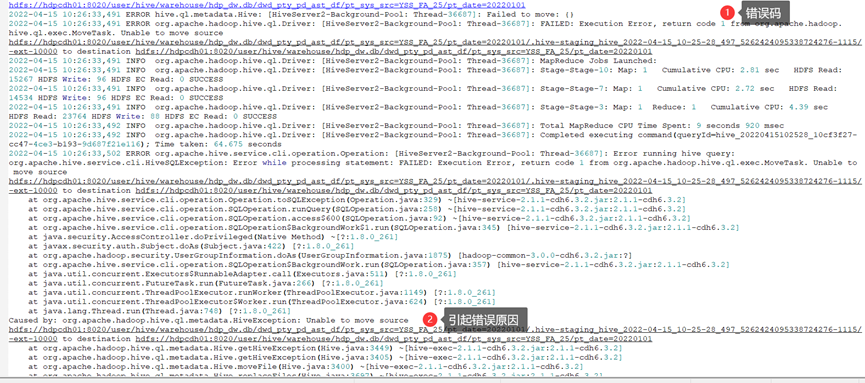
图3-1 hive返回recode 1以及引起原因截图
引起原因:使用insert overwrite table select xx from xxx;进行批处理作业时,hive会先将select出来的语句写入到临时目录中,然后将临时目录中的文件load到hive的分区表中;然后再通过重命名的方式将hive中load的文件进行重新命名,将文件放到具体的分区目录中。如果由于客户误操作,导致hive中的元数据信息出了错误:具体就是记录hdfs的目录的元数据信息删除了,但是hdfs的中文件目录没有删除。当hive作业对hdfs的临时文件进行名称修改时,已经存在一个同名的文件了,这时就会因为文件同名导致作业执行失败。
解决方法:将文件中的分区数据去掉,然后从新执行作业,问题解决。如果删除分区都不能解决问题,那就说明元数据损毁严重,已经没有修复的可能,就需要将表格删除,然后重新建表,重建元数据了。
3.2 Hive返回错误码recode 2
问题描述:用户将作业提交到yarn上执行时,作业开始执行十几分钟之后报错recode 2;因为作业已经开始执行,因此可以通过查看yarn日志,并发现报错如下:
CDH集群执行作业报错:Current usage: 106.1 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1569779921172_0010_01_000005 :
引起原因:yarn是CDH集群上的资源调度器,会根据task任务的请求,给任务分配资源(cpu和内存),而资源是放到一个叫做Container的虚拟容器中。本作业错误产生原因是因为yarn上运行的map任务作业中的Container试图使用过多的内存,而实际上分配给Container的内存不足,因而作业被yarn上的NodeManager 给kill掉了 。
解决方法:针对该作业重新设置map和reduce的容器需要的内存,一般报错提示,设置的内存高于报错提示1g即可,并且注意map的jvm虚拟机内存需要设置成map内存的0.8倍。比如该作业可以设置为:
mapreduce.map.memory.mb=4096;
mapreduce.map.java.opts=-Xmx3276M;
mapreduce.reduce.memory.mb=8192;
mapreduce.reduce.java.opts=-Xmx6554M;
如果设置调整完map和reduce的作业的内存,作业仍然报错,说明该作业中存在数据倾斜;这个时候调整内存和cpu资源就不起作用了,需要调整一下业务sql了。
3.3 Hive返回错误码recode 101
问题描述:客户现场有个作业在yarn上执行时报错:FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Java heap space。
问题原因:根据错误提示可以知道,该作业的hive的客户端进程中的内存溢出了。需要调整hive的启动内存参数。
解决方法:调整hive启动内存参数大小:export HIVE_CLIENT_OPTS="-Xmx1536m -XX:MaxDirectMemorySize=512m"。重新执行作业,作业可以正常执行了,问题解决。
四、总结
本文针对客户现场的生产环境中常见的hive的报错码进行了释义,并提出了具体的查找日志的方法与解决思路。并列举了3个例子说明了hive的错误码所代表的含义以及如何解决问题。本文重在介绍当Hive作业执行失败时,如何查找hive作业的执行日志以及如何进行错误定位。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)