


Hive的原理和基本用法
一、Hive的概述
1、Hive的定义
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL进行数据读取、写入和管理。
2、Hive的架构图
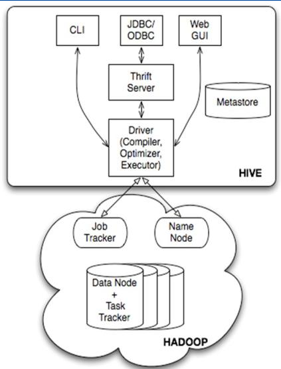
hive的各个组成部分介绍:
- 用户接口:包括 CLI、JDBC/ODBC、WebGUI。
- 元数据存储:通常是存储在关系数据库如 mysql , derby中。
- 用户接口主要由三个:CLI、JDBC/ODBC和WebGUI。其中,CLI为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
- 元数据存储:Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表所属的数据库,表的列和分区及其属性(是否为外部表),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
3、Hive与Hadoop的关系
a、Hive的数据是存放在Hadoop之上的;
b、Hive的数据分为两个部分:数据+元数据;元数据是记录数据的数据,这里记录着表名、所属的数据库、列(名/类型/index)、表类、表数据和分区及其在hadoop的目录。
c、Hive将SQL进行解析,然后开启MR任务在Hadoop上运行。
4、Hive的执行引擎
hive的执行引擎包括:MapReduce、Tez和Spark;只要通过一个参数就能够切换底层的执行引擎。
5、Hive的参数配置
1)元数据库连接配置
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://XXX:3306/databaseName?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
2)显示当前使用数据库和表结构名称配置
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
3)也可以使用set hive.cli.print.current.db = true的方式,使之在当前界面生效。
6、hive和RDBMS的关系
- 相同点:都是使用sql,都支持事务(hive用的很少)和支持insert/update/delete。
- 不同点:1)体量不同/集群规模 2)延迟/时性
二、Hive的常用命令
1、创建数据库
a、Create database if not exists test;
自己创建的数据库,默认存放在:/user/hive/warehouse/test.db目录中
b、创建数据库,同时制定目录
create database if not exists test location ‘/test/directory’;
c、创建数据库,同时添加描述信息
create database if not exists test comment ‘this is a database’ With DBPROPERTIES('creator'='me','date'='9012-12-17')
2、Hive常用的数据类型
数值类型:int bigint float double decimal
字符串类型:Stirng 90%
布尔类型: boolean:true false
日期类型:date timestamp
3、Hive的表格类型
Hive的表格分为内部表和外部表。
内部表删除时:HDFS的数据和Meta都会被删除;
外部表删除时:HDFS的数据不会被删除,只是Meta上的数据会被删除,安全起见,最好创建外部表。
a、创建外部表的格式
create external table emp_external (empno int,ename string,job string,mgr int,hiredate string,sal double, comm double,deptno int) row format DELIMITED FIELDS TERMINATED BY '\t' Location '/test/externaltable/emp';
加载数据到外部表
Load data Local inpath '/home/hadoop/data/emp.txt' into table emp;
b、创建内部表
- 只是创建表结构,不包含数据: create table emp2 like emp;
- 既创建表结构,也包含数据:create table emp3 like emp;
4、Hive的表的分区和分桶
- 分区列并不是一个“真正的”表字段,其实是HDFS上表对应的文件下的一个文件夹
create table order_partition(order_no string,event_time string) partitioned by(event_month string)ROW Format Delimited Fields terminated By '\t';
Load DATA Local inpath '/home/hadoop/data/order_created.txt' Into table order_partition PARTITION(event_month='2015-05');
- 分区表加载数据的时候一定要指定分区字段;对于分区表操作,如果你的数据是写入到HDFS中,默认SQL是查询不到的,因为元数据中没有;如果想用SQL查询,需要添加表分区
Alter table order_partition ADD if not exists Partition(event_month='2015-07');
- 多级分区:为表格指定多个分区
create table order_mulit_partition(order_no String,event_time string) Partition by(event_month String,step String) Row format Delimited Fields Terminated By '\t';
Load Data Local Inpath '/home/hadoop/data/order_mulit_partition Into Table order_mulit_partition Partition(event_month='2014-06',step='2');
- 使用分区表时,加载数据一定要指定我们的所有分区字段
Create table emp_parititon(empno int,ename string,job string,mgr int,hiredate string,sal double,comm double) Partition By(deptno int) Row Format Delimited Fields Terminated By '\t';
Insert Overwrite Table emp_partition Partition(deptno=10) select empno,ename,job,mgr,hiredate,sal,comm form emp where deptno=10;
- 动态分区
Create table emp_dynamic_partition(empno int,ename string,job string,mgr int,hiredate string, sal double,comm double) Partition by(deptno int) Row Format Delimited Fields Terminated By '\t';
Insert Overwrite Table emp_dynamic_partition Partition(deptno) select empno,ename,job,mgr,hiredate,sal comm form emp;
5、几个关键字介绍
Load Data Local Inpath 'home/hadoop/data/order_created.txt' [Overwrite] into table order_mulit_parititon Partition (event_month='2014-05',step='1')
- Load Data:加载数据
- INPATH:指定路径
- Overwrite:数据覆盖,没有的话就是追加。
6、数据导入的另外两种方式
- CTAS:表不能实现存在(create table .. as select ..)
- Insert方式:表必须事先存在,表格字段必须顺序书写,不能乱 ,否则查询时会出错,找不到该字段
Insert overwrite table emp4 select empo,job,ename,mgr hiredate,sal,comm,deptno from emp;
from emp insert into table emp4 select *;
7、分组查询时注意的事项
- where只是对单项进行限制,分组限制要使用hiving
- select 中出现的字段,如果没有出现在group by 中,则必须出现在聚合函数中
select deptno,avg(sal) avg_sal from emp group by deptno having avg_sal >2000;
8、Hive中MR的使用设置
通过设置hive中的参数可以部分限制MR的使用级别,默认Select * from table;是不用走mapReduce的;涉及到多对一的聚合函数:多进一出,则必然使用MapReduce,比如:max,min,count,sum,avg。

