
基础算法--字符串
目录
基本概念
核心思想:在每次失配时,不是把p串往后移一位,而是把p串往后移动至下一次可以和前面部分匹配的位置,这样就可以跳过大多数的失配步骤。而每次
next数组的含义及手动模拟
next数组的含义:对
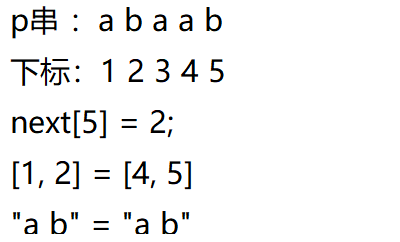
手动模拟求next数组:
对 p = “abcab”
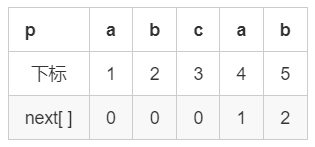
对
对
对
对
对
匹配思路
KMP主要分两步:求next数组、匹配字符串。
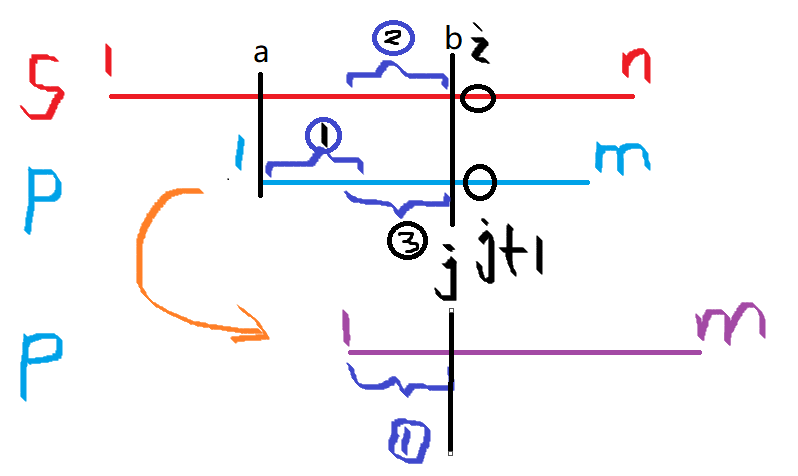
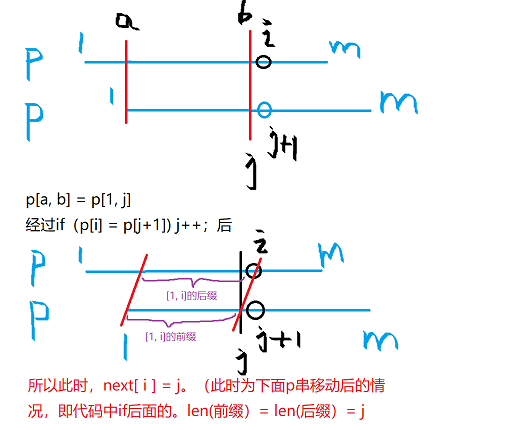
当匹配过程到上图所示时,
其中
例. KMP字符串
题目描述:
给定一个字符串
模式串
求出模式串
输入格式:
第一行输入整数
第二行输入字符串
第三行输入整数
第四行输入字符串
输出格式:
共一行,输出所有出现位置的起始下标(下标从
输入
3
aba
5
ababa
输出
0 2
数据范围
KMP
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) #define int long long using namespace std; const int N = 1e6 + 10; char p[N], s[N]; int n, m, ne[N]; void solve() { cin >> n >> s >> m >> p; ne[0] = -1; for(int i = 1, j = -1; i < n; i ++) { while(j != -1&&s[i] != s[j + 1]) j = ne[j]; if(s[i] == s[j + 1]) j ++; ne[i] = j; } for(int i = 0, j = -1; i < m; i ++) { while(j != -1&&p[i] != s[j + 1]) j = ne[j]; if(p[i] == s[j + 1]) j ++; if(j == n - 1) { cout << i - j << ' '; j = ne[j]; } } } signed main() { IOS; int _ = 1; // cin >> _; while(_ --) solve(); return _ ^ _; }
字符串哈希 Hash
我们定义一个把字符串映射到整数的函数
我们希望这个函数
为了避免冲突,
例1. 模拟散列表
题目描述:
维护一个集合,支持如下几种操作:
1.I x,插入一个数
2.Q x,询问数
现在要进行
输入格式:
第一行包含整数
接下来 I x,Q x 中的一种。
输出格式:
对于每个询问指令 Q x,输出一个询问结果,如果 Yes,否则输出 No。
每个结果占一行。
输入
5
I 1
I 2
I 3
Q 2
Q 5
输出
Yes
No
数据范围
代码
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) // #define int long long using namespace std; const int N = 3e5 + 10, null = 0x3f3f3f3f; int h[N], n; int find(int x) { int t = (x % N + N) % N; while(h[t] != null&&h[t] != x) { t ++; if(t == N) t = 0; } return t; } void solve() { string op; int x; cin >> op >> x; if(op == "I") h[find(x)] = x; else { if(h[find(x)] != null) puts("Yes"); else puts("No"); } } signed main() { IOS; memset(h, 0x3f, sizeof(h)); int _ = 1; cin >> _; while(_ --) solve(); return _ ^ _; }
代码
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) #define int long long using namespace std; const int N = 1e5 + 10; int h[N], ne[N], e[N], idx, n; void insert(int x) { int t = (x % N + N) % N; e[idx] = x; ne[idx] = h[t]; h[t] = idx ++; } bool find(int x) { int t = (x % N + N) % N; for(int i = h[t]; i != -1; i = ne[i]) if(e[i] == x) return true; return false; } void solve() { string op; int x; cin >> op >> x; if(op == "I") insert(x); else { if(find(x)) puts("Yes"); else puts("No"); } } signed main() { IOS; memset(h, -1, sizeof(h)); int _ = 1; cin >> _; while(_ --) solve(); return _ ^ _; }
例2. 字符串哈希
题目描述:
给定一个长度为
字符串中只包含大小写英文字母和数字。
输入格式:
第一行包含整数
第二行包含一个长度为
接下来
注意,字符串的位置从
输出格式:
对于每个询问输出一个结果,如果两个字符串子串完全相同则输出 Yes,否则输出 No。
每个结果占一行。
输入
8 3
aabbaabb
1 3 5 7
1 3 6 8
1 2 1 2
输出
Yes
No
Yes
数据范围
字符串哈希模板
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) // #define int long long using namespace std; typedef unsigned long long ull; const int N = 1e6 + 10; ull p[N], h[N]; char s[N]; int n, m, b = 131; ull check(int l, int r) { return h[r] - h[l - 1] * p[r - l + 1]; } void solve() { cin >> n >> m >> s + 1; p[0] = 1; for(int i = 1; i <= n; i ++) p[i] = p[i - 1] * b; for(int i = 1; i <= n; i ++) h[i] = h[i - 1] * b + s[i] - 'a' + 1; while(m --) { int a, b, c, d; cin >> a >> b >> c >> d; if(check(a, b) == check(c, d)) puts("Yes"); else puts("No"); } } signed main() { IOS; int _ = 1; // cin >> _; while(_ --) solve(); return _ ^ _; }
例3. 电源串
题目描述:
给定若干个长度 ababab 则最多有 ab 连接而成。
输入格式:
输入若干行,每行有一个字符串。特别的,字符串可能为 . 即一个半角句号,此时输入结束。
输出格式:
对于每个输入,输出一个数字,表示最多的重复子字符串数量
输入
abcd
aaaa
ababab
.
输出
1
4
3
数据范围
字符串长度
点击查看代码
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) // #define int long long using namespace std; typedef unsigned long long ull; const int N = 1e6 + 10; ull p[N], h[N]; int ne[N], n, b = 131; char s[N]; void solve() { while(~scanf("%s", s + 1)) { if(s[1] == '.') break; n = strlen(s + 1); int ans = 1, f = 1; for(int i = 1; i <= n; i ++) h[i] = h[i - 1] * b + s[i] - 'a' + 1; for(int i = 1; i <= n; i++) { f = 1; if(n % i) continue; for(int j = 0; j < n; j += i) if(h[j + i] - h[j] * p[i] != h[i]) { f = 0; break; } if(f) { cout << n / i << endl; break; } } } } signed main() { p[0] = 1; for(int i = 1; i <= 1000001; i ++) p[i] = p[i - 1] * b; IOS; int _ = 1; // cin >> _; while(_ --) solve(); return _ ^ _; }
字典树(trie树)
字典树,英文名 trie。顾名思义,就是一个像字典一样的树。
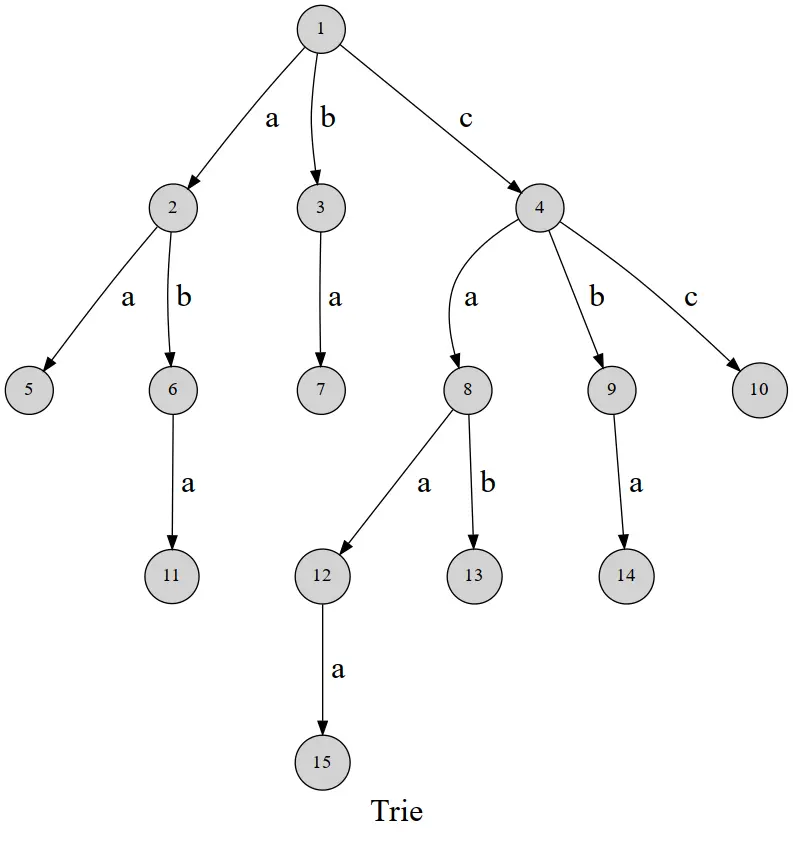
可以发现,这棵字典树用边来代表字母,而从根结点到树上某一结点的路径就代表了一个字符串。
有时需要标记插入进
例1. Trie字符串统计
题目描述:
维护一个字符串集合,支持两种操作:
1.I x 向集合中插入一个字符串
2.Q x 询问一个字符串在集合中出现了多少次。
共有
输入格式:
第一行包含整数
接下来 I x 或 Q x 中的一种。
输出格式:
对于每个询问指令 Q x,都要输出一个整数作为结果,表示
每个结果占一行。
输入
5
I abc
Q abc
Q ab
I ab
Q ab
输出
1
0
1
数据范围
点击查看代码
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) #define int long long using namespace std; const int N = 1e5 + 10, M = 26; int son[N][M]; int e[N], ne[N], h[N], cnt[N], idx; char str[N]; void insert() { int p = 0; for(int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if(!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } cnt[p] ++; } int query() { int p = 0; for(int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if(!son[p][u]) return 0; p = son[p][u]; } return cnt[p]; } void solve() { int n; cin >> n; char f; while(n --) { cin >> f >> str; if(f == 'I') insert(); else cout << query() << '\n'; } } signed main() { IOS; int _ = 1; // cin >> _; while(_ --) solve(); return _ ^ _; }
例2. 字典树
题目描述:
给定
一个字符串
输入的字符串大小敏感。例如,字符串 Fusu 和字符串 fusu 不同。
输入格式:
本题单测试点内有多组测试数据。
输入的第一行是一个整数,表示数据组数
对于每组数据,格式如下:
第一行是两个整数,分别表示模式串的个数
接下来
接下来
输出格式:
按照输入的顺序依次输出各测试数据的答案。
对于每次询问,输出一行一个整数表示答案。
输入
3
3 3
fusufusu
fusu
anguei
fusu
anguei
kkksc
5 2
fusu
Fusu
AFakeFusu
afakefusu
fusuisnotfake
Fusu
fusu
1 1
998244353
9
输出
2
1
0
1
2
1
解释
对于全部的测试点,保证
,且输入字符串的总长度不超过 。输入的字符串只含大小写字母和数字,且不含空串。
点击查看代码
#include<bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) using namespace std; const int N = 3e6 + 10, M = 80; int son[N][M], cnt[N], idx; int n, m; string s; void Insert() { int p = 0; for(int i = 0; s[i]; i ++) { int u = s[i] - '0'; if(!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; cnt[p] ++; } } int query() { int p = 0; for(int i = 0; s[i]; i ++) { int u = s[i] - '0'; if(!son[p][u]) return 0; p = son[p][u]; } return cnt[p]; } void solve() { cin >> n >> m; while(n --) { cin >> s; Insert(); } while(m --) { cin >> s; cout << query() << '\n'; } for(int i = 0; i <= idx; i ++) for(int j = 0; j < M; j ++) son[i][j] = 0; for(int i = 0; i <= idx; i ++) cnt[i] = 0; idx = 0; } signed main() { IOS; int _ = 1; cin >> _; while(_ --) solve(); return _ ^ _; }
例3. 阅读理解
题目描述:
英语老师留了
输入格式:
第一行为整数
按下来的
然后为一个整数
输出格式:
对于每个生词输出一行,统计其在哪几篇短文中出现过,并按从小到大输出短文的序号,序号不应有重复,序号之间用一个空格隔开(注意第一个序号的前面和最后一个序号的后面不应有空格)。如果该单词一直没出现过,则输出一个空行。
输入
3
9 you are a good boy ha ha o yeah
13 o my god you like bleach naruto one piece and so do i
11 but i do not think you will get all the points
5
you
i
o
all
naruto
输出
1 2 3
2 3
1 2
3
2
解释
对于
对于
每篇短文长度(含相邻单词之间的空格)
每个测试点时限
点击查看代码
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) using namespace std; const int N = 2e5 + 10; int n, m, idx; void Insert(vector<vector<int> >&son, vector<vector<bool> > &cnt, string s, int x, int y) { int p = 0; for(int i = 0; i < y; i ++) { int u = s[i] - 'a'; if(!son[p][u]) son[p][u] = ++ idx; p = son[p][u]; } cnt[p][x] = true; } void query(vector<vector<int> >&son, vector<vector<bool> > &cnt, string s, int x) { int p = 0; for(int i = 0; i < x; i ++) { int u = s[i] - 'a'; if(!son[p][u])return; p = son[p][u]; } for(int i = 1, j = 0; i <= n; i ++) if(cnt[p][i]) { if(j == 0) cout << i; else cout << ' ' << i; j ++; } } void solve() { cin >> n; vector<vector<int> > son(N, vector<int> (26, 0)); vector<vector<bool> > cnt(N, vector<bool> (n + 1, false)); for(int i = 1; i <= n; i ++) { cin >> m; while(m --) { string s; cin >> s; Insert(son, cnt, s, i, s.size()); } } cin >> m; while(m --) { string s; cin >> s; query(son, cnt, s, s.size()); cout << '\n'; } } signed main() { IOS; int _ = 1; // cin >> _; while(_ --) solve(); return _ ^ _; }
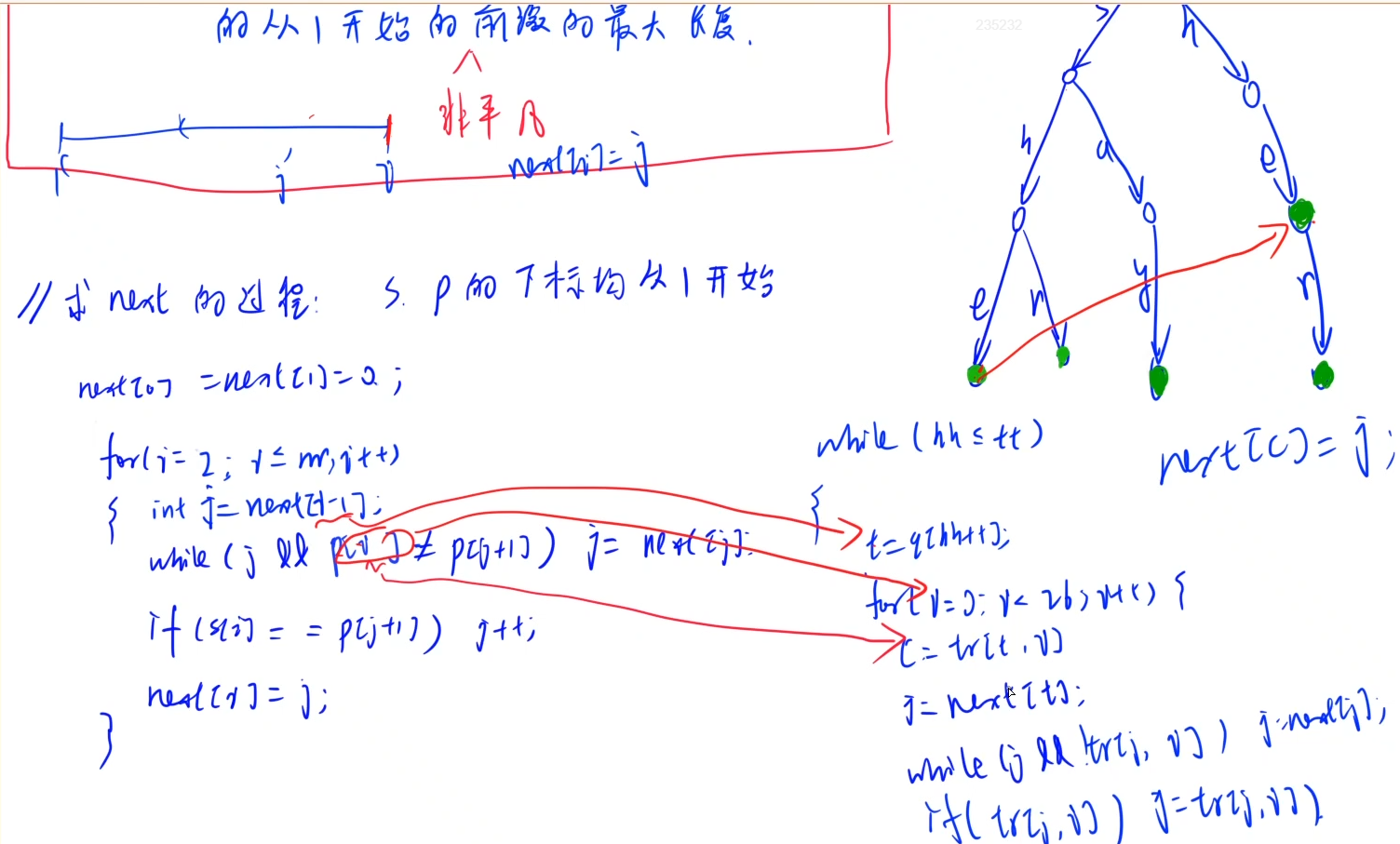
AC自动机
AC 自动机是 以 Trie 的结构为基础,结合 KMP 的思想 建立的自动机,用于解决多模式匹配等任务。Aho–Corasick(Alfred V. Aho, Margaret J. Corasick. 1975)
建立AC自动机
建立一个 AC 自动机有两个步骤:
1.基础的 Trie 结构:将所有的模式串构成一棵 Trie。
2.KMP 的思想:对 Trie 树上所有的结点构造失配指针。
然后就可以利用它进行多模式匹配了。
在AC自动机的构建过程中,用
例. 搜索关键词
题目描述:
给定
请问,其中有多少个单词在文章中出现了。
注意:每个单词不论在文章中出现多少次,仅累计
输入格式:
第一行包含整数
对于每组数据,第一行一个整数
输出格式:
对于每组数据,输出一个占一行的整数,表示有多少个单词在文章中出现。
输入
1
5
she
he
say
shr
her
yasherhs
输出
3
数据范围
AC自动机原版
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) // #define int long long using namespace std; typedef long long LL; const int N = 10010, s = 55, M = 1000010; int tr[N * s][26], cnt[N * s], idx; int q[N * s], ne[N * s]; char str[M]; void insert() { int p = 0; for(int i = 0; str[i]; i ++) { int u = str[i] - 'a'; if(!tr[p][u]) tr[p][u] = ++idx; p = tr[p][u]; } cnt[p] ++; } void build() { int hh = 0, tt = -1; for(int i = 0; i < 26; i ++) if(tr[0][i]) q[++ tt] = tr[0][i]; while(hh <= tt) { int t = q[hh ++]; for(int i = 0; i < 26; i ++) { int c = tr[t][i]; if(!c) continue; int j = ne[t]; while(j&&!tr[j][i]) j = ne[j]; if(tr[j][i]) j = tr[j][i]; ne[c] = j; q[++ tt] = c; } } } void solve() { int n, m; memset(tr, 0, sizeof tr); memset(cnt, 0, sizeof cnt); memset(ne, 0, sizeof ne); idx = 0; cin >> n; for(int i = 0; i < n; i ++) { cin >> str; insert(); } build(); cin >> str; int ans = 0; for(int i = 0, j = 0; str[i]; i ++) { int t = str[i] - 'a'; while(j&&!tr[j][t]) j = ne[j]; if(tr[j][t]) j = tr[j][t]; int p = j; while(p) { ans += cnt[p]; cnt[p] = 0; p = ne[p]; } } cout << ans << "\n"; } signed main() { IOS; int _ = 1; cin >> _; while(_ --) solve(); return _ ^ _; }
AC自动机优化版
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) // #define int long long using namespace std; const int N = 1e4 + 10, M = 1e6 + 10, S = 55; int tr[N * S][26], ne[N * S]; int cnt[N * S], q[N * S], idx; int n, m; string s; void Insert() { int p = 0; for(int i = 0; s[i]; i ++) { int u = s[i] - 'a'; if(!tr[p][u]) tr[p][u] = ++ idx; p = tr[p][u]; } cnt[p] ++; } void build() { int hh = 0, tt = -1; for(int i = 0; i < 26; i ++) if(tr[0][i]) q[++ tt] = tr[0][i]; while(hh <= tt) { int t = q[hh ++]; for(int i = 0; i < 26; i ++) { int p = tr[t][i]; if(!p) tr[t][i] = tr[ne[t]][i]; else { ne[p] = tr[ne[t]][i]; q[++ tt] = p; } } } } void solve() { cin >> n; while(n --) { cin >> s; Insert(); } build(); cin >> s; int ans = 0; for(int i = 0, j = 0; s[i]; i ++) { int t = s[i] - 'a'; j = tr[j][t]; int p = j; while(p) { ans += cnt[p]; cnt[p] = 0; p = ne[p]; } } cout << ans << '\n'; for(int i = 0; i <= idx; i ++) { ne[i] = cnt[i] = 0; for(int j = 0; j < 26; j ++) tr[i][j] = 0; } } signed main() { IOS; int _ = 1; cin >> _; while(_ --) solve(); return _ ^ _; }
manachar(马拉车)
最小表示法
最小表示法是用于解决字符串最小表示问题的方法。
循环同构:
当字符串
则称
最小表示:字符串
simple 的暴力
最小表示法
考虑对于一对字符串
不妨先考虑
过程:
例2. 循环同构
题目描述:
如果存在一个整数
现在,给定由小写字母组成的
输入格式:
输入由多个测试用例组成。第一行包含一个整数
每个测试用例的第一行包含两个整数
接下来的
下一行包含一个正整数
接下来的
输出格式:
对于每个测试用例,输出
输入
2
2 2
ab
ba
1
1 2
4 3
aab
baa
bba
bab
6
1 2
1 3
1 4
2 3
2 4
3 4
输出
Yes
Yes
No
No
No
No
Yes
点击查看代码
#include <bits/stdc++.h> #define IOS ios::sync_with_stdio(false);cin.tie(nullptr),cout.tie(nullptr) using namespace std; const int N = 1e5 + 10; int ne[N]; int x, y, n, m, q, ans; string s[N], ss[N]; string check(string s) { int n = s.size(); s = s + s; int i = 0, j = 1; while(i < n && j < n) { int k = 0; while(k < n && s[i + k] == s[j + k]) k ++; if(s[i + k] > s[j + k]) i += k + 1; else j += k + 1; if(i == j) i ++; } int k = min(i, j); return s.substr(k, n); } void solve() { cin >> n >> m; for(int i = 1; i <= n; i ++) cin >> s[i]; for(int i = 1; i <= n; i ++) ss[i] = check(s[i]); cin >> q; while(q --) { cin >> x >> y; if(ss[x] == ss[y]) puts("Yes"); else puts("No"); } } signed main() { ios::sync_with_stdio(false); cin.tie(0); int T = 1; cin >> T; while(T --) solve(); return T ^ T; }
本文作者:chfychin
本文链接:https://www.cnblogs.com/chfychin/p/17743525.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步