MySQL数据库基础
1. MySQL的概念
MySQL是管理关系数据库管理系统,包括数据的插入,查询,更新和删除,数据库模式创建和修改,数据的控制访问。
1. cmd启动mySQL: mysql -u root -p 密码是root
![]()
![]()
![]()
![]()
![]()
![]()
2. mysql端口号是3309,用户名是root,密码是我的常规密码
3. mysql80端口号是3306,用户名是root,密码是root
4. mongoDB端口号是27017
2. MySQL常用的语法
增
1. create database 数据库名 新建数据库
2. create table 表名(属性内容) 新建数据表
3. insert into 数据表名 value(val1,val2...) 插入数据
4. insert into 数据表名(key1,key2...)value(val1,val2...) 插入指定列的数据
删
1. delete from 数据表名 where key=val 或 order by limit 2 删除指定的数据
2. alter table 表名 drop column key 删除指定的列
3. truncate table 表名 删除表中的数据,保留表结构
4. delete from 表名 清空表的数据,一行一行的删除
5. drop database 数据库名 删除数据库
6. drop table 表名 删除表,完全删除
delete、truncate和drop的区别
| 区别点 | delete | truncate | drop |
| 执行速度 |
慢,delete的删除是一列一列进行, 并且记录日志,便于回滚操作 |
居中,truncate删除时会先复制 一个新的表结构,在进行删除 |
快,drop直接删除表的结构和内容 |
| 删除对象 |
可删除表的全部或者部分内容, 可以进行where条件限定,表结构、索引、约束等会被保留 |
只删除表数据,表结构、索引、 约束等会被保留 |
删除整张表和表结构, 以及表的索引、约束和触发器 |
| 数据恢复(回滚) |
可进行数据恢复(回滚操作) 属于DML(数据操作语言),支持事务回滚操作 |
不可进行回滚操作 属于DDL(数据定义语言),执行立即生效,不可数据恢复 |
不可进行回滚操作 属于DDL(数据定义语言),执行立即生效,不可数据恢复 |
| 自增初始值 | 不重置初始值,插入数据接着原表的自增值 | 重置初始值,插入数据从1开始 | - |
改
1. update 表名 set key = "" 清空某一列的数据
2. update 表名 set key = val where... 更新数据,没有设置条件该列会全部替换
3. alter table 表名 add key(属性)after/before oldKey 在数据库中指定的列后面或前面添加新的列
4. alter table 表名 modify key(new属性) 修改某一列的属性
5. alter table 表名 change oldKey newKey(属性)修改某列名
查
1. select * from 表名 查询表中的所有数据
2. select * from 表名 limit 10 查询前10条数据
3. select * from 表名 where... 查询指定条件的数据
4. select distinct key from 表名 查询表中的列(去重)
3. 常见的数据类型
1. 整数类型,整数类型不需要指定长度,如果指定长度常常配合zerofll,即向左填充0至指定长度,若要设置无符号,需要int后添加unsigned 关键字
| 整数类型 | 字节数 | 默认长度 | 无符号取值范围 | 有符号取值范围 |
| tinyint | 1 | 3 | 0~255 | -128~127 |
| smallint | 2 | 5 | 0~65535 | -32768~32767 |
| mediumint | 3 | 8 | 0~16777215 | -8388608~8388607 |
| int | 4 | 11 | 0~4294967295 | -2147483648~2147483647 |
| bigint | 8 | 20 | 0~18446744073709551615 | -9223372036854775808~9223372036854775807 |
2. 浮点数类型,表达形式例如:float(M,D)M是最大位数,D是小数位数,M不能小于D
| 浮点数类型 | 字节数 | 最大有效小数 | 用途 |
| float | 4bytes(32位) | 6位 | 单精度浮点类型 |
| double | 8bytes(64位) | 15位 | 双精度浮点类型 |
| decimal | 取决于M和D | M的范围是1~65,D的范围是0~30 | 小数值 |
附:decimal的字节占比,decimal类型的数据存储形式是,将每9位十进制数存储为4个字节
| Leftover Digits | Number of Bytes | 例子 |
| 0 | 0 |
例1:字段decimal(18,9),18-9=9,这样整数部分和 小数部分都是9,那两边分别占用4个字节 |
| 1-2 | 1 | |
| 3-4 | 2 |
例2:字段decimal(20,6),20-6=14,其中小数部分为6,占3个字节, 而整数部分为14,14-9=5,就是4个字节再加上3个字节,整数部分占7个字节 |
| 5-6 | 3 | |
| 7-9 | 4 |
3. 字符型,需要指定字符长度,超出舍去,text不设置长度
| 字符类型 | 大小 | 范围 | 特点 |
| char | 数字和字母占1个字节,汉字3个字节,表情包4个字节 | 0~255 | 定长,即规定多少多少字符,不够会自动向右用空格占满 |
| varchar | 数字和字母占1个字节,汉字3个字节,表情包4个字节 | 0~65535 | 变长,即规定多少字符就是多少字符,不会自动填满 |
| text | 不能超过,否则报错 | 0~65535 | 不设置长度,但是查询速度最慢 |
4. 时间类型
| 时间类型 | 名称 | 字节 | 格式 | 最小值 | 最大值 |
| year | 年份 | 1 | xxxx | 1999 | 2155 |
| time | 时间 | 3 | HH:MM:SS | -838:59:59 | 838:59:59 |
| date | 日期 | 3 | YYYY-MM-DD | 1000-01-01 | 9999-12-31 |
| datetime | 日期时间 | 8 | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 | 9999-12-31 23:59:59 |
| timestamp | 日期时间 | 4 | YYYY-MM-DD HH:MM:SS | 1970-01-01 00:00:00 UTC | 2038-01-19 03:14:07 UTC |
4. 条件语句
1. where后的运算符(=、>、<、>=、<=、<>等价于!=)
select * from employees where dept = '办公室' select * from employees where salary > 3000 select * from employees where dept <> '办公室'
2. having 条件筛选,用在聚合函数后面
select job,min(sal) from employees group by job having min(sal) > 1500
3. between(在某个范围之间).... and ....
select * from employees where salary between 5000 and 10000
4. not between(不在某个范围之间)... and ...
select * from employees where salary not between 5000 and 10000
5. like 匹配模式,%表示0个或者多个字符,_表示1个字符
select * from employees where dept like '_销%'
6. in(val1,val2...) 包含模式,符合其中条件即可
select * from employees where dept in ("人事部","办公室")
7. and 或条件,满足所有条件触发
select * from employees where salary > 5000 and dept = '办公室'
8. or 与条件,满足其中一个条件即可
![]()
![]()
select * from employees where sex = '男' or dept = '办公室'
5. order by 排序
ASC:升序(默认),可不写
select * from employees order by SAL,JOB 多个条件排序
DESC:降序
select * from employees order by SAL DESC,JOB DESC
6. 通配符
1. %:匹配任意类型和任意长度的字符,表示占用0个或多个字符
%str%:包含str的字符 str%:以str开头的字符 %str:以str结尾的字符
2. _:占用1个字符,通常用来限制表达式的长度
_a:匹配第二个字符为a的字符 __a:匹配第三字符为a的字符
7. 连接符
1. inner join:内连接,返回两表都有的数据,null则不返回
select commodityName,nname from orders as o inner join employees as e on o.id = e.id
2. left join:左连接,以左边的表为基准返回数据,右边null则返回null
select commodityName,nname from orders as o left join employees as e on o.id = e.id
3. right join:右连接,以右边的表为基准返回数据,左边null则返回null
select commodityName,nname from orders right join employees as e on o.id = e.id
4. full outer join:外连接,返回两表所有的数据,MySQL不支持
5. union:查询连接,连接两个表或者多个查询语句
select o.id,o.commodityName from orders as o where o.sal > 20 union select e.id,e.nname from employees as e where e.sex = '男'
8. 表数据的复制
1. select * newtable from oldtable (*所有的列,key可指定的列),MySQL不支持
2. insert into newtable select * from oldtable 将所有的数据复制到新表,两表结构一样
insert into newEmployees select * from employees
3. insert into newTable select * from oldTable where key = val 将指定的行数据复制到新表
insert into newEmployees select * from employees where nname in ('张三','王丽')
4. insert into newTable (key1,key2...) select key1,key2... from oldTable 将指定的列数据复制到新表,两表结构不一样是可使用
insert into newEmployees (id,nname)select id,nname from employees
5. create table newTable like oldTable 将旧表的结构复制到新表中,不复制数据
create table newEmployees like employees
6. create table newTable select * from oldTable 将旧表的结构和数据都复制到新表中
create table newEmployees select * from employees
9. 约束
1. not null:非空约束,指定列不能为空
语法:create table 表 (key1 not null...)

2. unique:保证某列的每一行必须有唯一的值,可以为null,每个表可有多个unique
a:语法:create table 表 (key1,key2..., unique (key1,key2...))

b:语法:alter table 表 add unique (key1,key2...)
![]()
![]() 3. primary key:保证某一列有唯一标识,每个表只能有一个primary key
3. primary key:保证某一列有唯一标识,每个表只能有一个primary key
c:语法:create table 表 (key1,key2...,constraint key unique (key1,key2...) ) 命名unique约束
d:语法:alter table 表 drop index key 撤销unique约束

a: 语法:create table 表 (key primary key,key1...) 列级定义

b: 语法:create table 表 (key1,key2...,primary key (key1)) 表级定义

c: 语法:create table 表 (key1,key2...,primary key (key1 , key2)) 联合主键![]()

d: 语法:alter table 表 add primary key key1
e: 语法:create table 表 (key1,key2...,constraint key peimary key (key1,key2....)) 命名primary key约束
f : 语法:alter table 表 drop primary key 撤销primary key约束
4. foreign key:外键,若有两个表A,B,id是A的主键,而B中也有id字段,则id就是表B的外键,外键约束主要用来维护两个表之间数据的统一性
a:语法:create table 新表 (key1,key2,key...,foreign key(key) references 旧表 (key)) 新表的key的值必须在旧表的key值之中选取
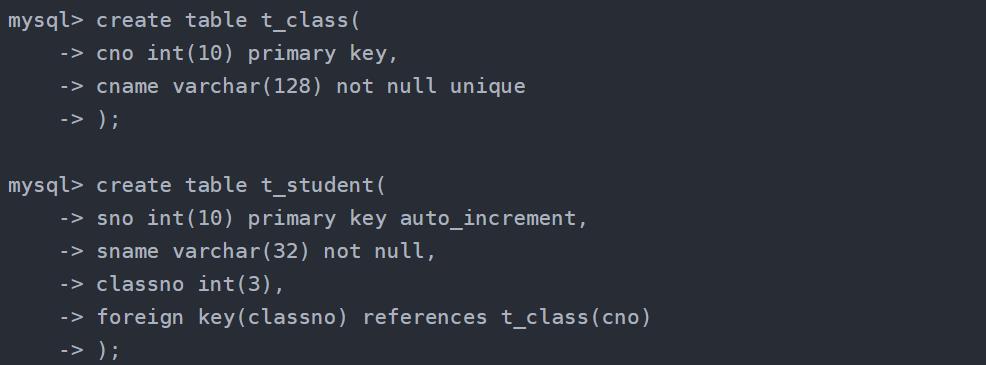
b:语法: alter table 表 add foreign key(key) references 旧表 (key)) 添加外表foreign key
c:语法: create table 新表 (key1,key2,key...,constraint 命名 foreign key(key) references 旧表 (key)) 命名foreign key 约束
d:语法:alter table 表 drop foreign key key1 撤销primary key约束
5. check:保证列中的值符合指定的标准,用来限制值的范围
a:语法: create table 表 (key1,key2.. ,check (key1>3)) 规定key1的值必须大于3
b:语法: alter table 表 add check (key>10) 新建check约束的列
c:语法: create table 表(key1,key2...,constraint 命名 check (key1>3 and key2='val')) 命名check约束
d:语法: alter table 表 drop check key 撤销check的约束,好像只对命名的check有效
6. default:默认值,规定没有给列赋值时的默认值
a:语法: create table 表 (key1,key2 default '默认值'... ) 设置未赋值前的默认值
b:语法: alter table 表 alter key default '默认值' 添加default约束的列
c:语法: alter table 表 alter key default 撤销default的约束
10. 索引
1. 主键索引:primary key 主键即主键索引,值唯一性
create table 表 (key primary key) 主键相当于主键索引
2. 普通索引:index或key,默认的索引
create index 索引名 on 表(key...)或create table 表(key1,key2...,index(key1))
alter table 表 add index 索引名(key) 在已有的表中创建索引
3. 唯一索引:unique index 避免重复的列出现,索引可以重复
create unique index 索引名 on 表(key1,key2) 创建多个索引
create table 表 (key1,key2...,unique index(key)) 建表时创建
alter table 表 add unique index 索引名(key) 在表中添加索引
4. 全文索引:fulltext index 特定引擎才有,能快速定位数据
5. 查看索引信息:show index from 表
6. 撤销索引:drop index 索引名 on 表 或者 alter table 表 drop index 索引名
7. 检查数据库执行情况:explain select * from 表
8. 索引失效的场景:
1. 当where使用多条件字段查询时,只有其中一条件字段有索引,另一条没有,则失效
例:select * from 表 where key1 = val1 and key2 = val2 key1存在索引,key2没有所有,则失效
2. 违反左前缀原则,失效
例:表中有key1,key2,key3创建了索引(按顺序),where查询的第一个条件不是key1时失效
3. 当查询条件中出现了<>、not、in等操作符时,表不使用索引进行查询
4. 查询条件中使用or时索引失效
5. 使用like通配符,使用后置通配符"a%"生效,但是前置通配符"%a"时失效
6. 在索引列上使用函数、数据库内置函数、计算、进行类型转换、索引失败
9. 索引的优缺点:
优点:
1. 唯一索引可以保证每一行数据的唯一性
2. 大大加快了数据的程序速度
缺点:
1. 创建和维护索引需要耗费时间,增加工作量
2. 索引会占磁盘空间,造成内存泄漏
3. 在对数据表进行相关操作时,需要动态维护索引,降低数据维护速度
11. AUTO_INCREMENT自增
语法:create table 表 (id auto_increment,key2...) 指定id为自增列,无序添加初始值,它默认起始值是1,增值为1,不可以直接在创建表的时候赋起(auto_increment),
可以使用alter确定起始值:alter table 表 auto_increment = n
12. VIEW视图
MySQL视图是虚拟图表,但是和普通表一样,不保存数据,不占用内存,可以将需要查询的内容由多张表合并起来(inner join),但是合并的内容不能重复,例如两张表都存在
ID,视图中就不能存在ID
创建视图:create view 视图名 as 查询语句(select a.key1,b.key2 from a inner join b on a.id = b.id)
查询视图:select * from 视图名 where ...
查看视图:show create view 视图名 或者 desc 视图名
更新视图:create or replace view as (select a.key3,b.key4 from a inner join b on a.id=b.id) 或 alter view 视图名 as (select a.key3,b.key4 from a inner join b on a.id=b.id)
删除视图:drop view 视图名1,视图名2
删除视图:drop view 视图名1,视图名2
13. 分组查询,通常配合聚合函数一起使用
1. where 条件语句在条件选择后进行分组,分组的列要和分组函数中的列保持一直
语法:select 分组函数(列)from 表 where 条件语句 group by 分组的列 order by 列
2. having条件语句在分组后再进行条件选择,分组的列要和分组函数中的列保持一直
语法:select 分组函数(列)from 表 group by 分组的列 having 条件语句 order by 列

 浙公网安备 33010602011771号
浙公网安备 33010602011771号