
详解 CALICO_IPV4POOL_IPIP CrossSubnet 模式 bgp模式在跨网段的场景将不能工作;
让暴风雨来得更猛烈些吧
kubernetes网络 – 网络插件 – calico
欢迎加入本站的kubernetes技术交流群,微信添加:加Blue_L。
calico支持host-gateway,vxlan,ipip和bgp网络模式。calico网络插件支持下列功能
- 基于vxlan,ipip的overlay集群网络方案。
- 基于bgp的路由网络方案,以及将podIP,服务的clusterIP,externalIP和LoadBalancerIP路由到集群外的能力。
- kubernetes cni插件,calico和calico-ipam
- kubernetes原生网络策略和扩展网络策略
- 基于eBPF的数据面,实现网络策略和kubernetes服务功能
- 和其他系统(如openstack)的集成
- istio网络策略扩展
架构与组件
https://docs.projectcalico.org/reference/architecture/overview
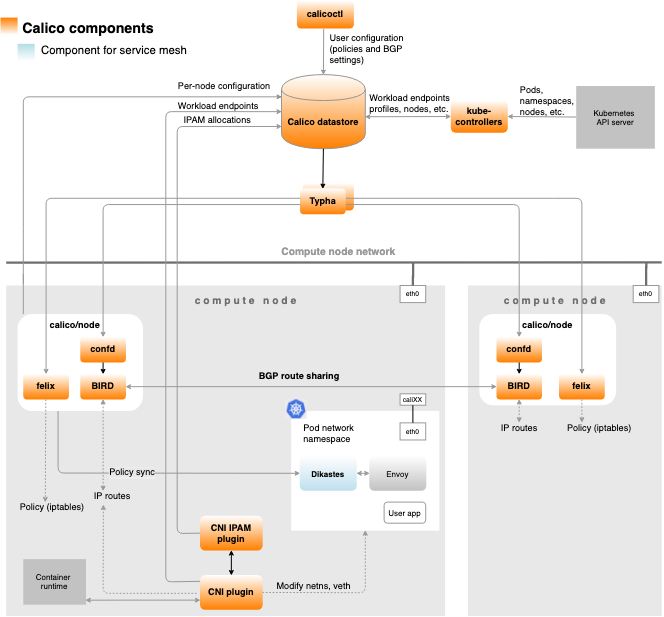
Calico组件
- Felix
- BIRD
- confd
- Dikastes
- CNI plugin
- Datastore plugin
- IPAM plugin
- kube-controllers
- Typha
- calicoctl
Felix
管理主机上的路由规则,数据面访问控制等,提供访问该主机上服务的能力。比如:
- 接口管理管理网络接口设备,比如vxlan,ipip隧道接口设备,arp表信息,配置ip地址转发等。
- 配置路由配置子网和端点的路由信息。
- 配置访问控制如网络策略。
- 状态报告节点上的网络健康数据,错误信息等。
BIRD
获取路由信息,并分发到BGP peers,基于开源的bird软件。
- 路由分发当Felix修改系统路由后(FIB),bird感知到将其分发到其他节点。
- 路由反射传统bgp网络各个节点之间组成mesh,节点数量很多时,会有大量连接,有性能影响。通过使用reflector,将其作为中心节点,所有peer都和他建链接,它想每个peer分发整个集群的路由信息。
confd
检测calico的datastore数据变化以便及时修改bgp配置,如AS编号,日志级别等。它通过修改bird的配置文件并重新加载bird实现这些功能。
Dikastes
执行istio服务网格的网络策略,作为sidecar运行在集群中。
CNI plugin
kubernetes的cni插件的实现,在每个节点上都要部署。
Datastore plugin
存储插件,减轻各个节点对存储引擎的影响。支持kubernetes和etcd。
IPAM plugin
结合calico cni插件使用,使用calico的ippool下分配ip地址。
kube-controllers
检测kubernetes集群资源变化,执行相关动作,包含下列控制器:
- 策略控制器
- 命名空间控制器
- 服务账户控制器
- 工作负载控制器
- 节点控制器
Typha
减轻各个节点对存储中心的影响。目的是争取和存储中心保持一个链接。像Felix和confd都是连接Typha。
calicoctl
客户端工具,可以用来对calico的各种资源执行增删改查等操作。
安装部署
calico的网路配置,网络策略都是通过datastore组件进行存储的。datastore后端存储支持kubernetes和etcd。如果是单独针对kubernetes使用,推荐使用默认的kuberentes后端,如果要和openstack这样的系统进行集成,那么推荐使用etcd后端。我们使用kubernetes后端存储。
快速部署:
curl https://docs.projectcalico.org/manifests/calico.yaml -O
# 修改CALICO_IPV4POOL_CIDR为集群的pod网段,并安装
kubectl apply -f calico.yaml默认情况下,部署完成之后会得到下列功能组件:
- calico的网络策略功能
- calico的cni插件
- calico的ipam插件
- ipip模式的集群网络
- bgp路由
- kubernetes后端存储
关于网络模式的选择,可以参考:Determine best networking option
默认情况下的某系参数配置可能不满足实际需求,那么需要我们进行一些自定义调整。下面是一些较为常规的参数配置说明:
- 网络配置
- calico_backend 可选为bird和vxlan。bird使用bgp配置集群节点建网络和以及外部网络的路由,可结合ipip等模式使用。vxlan只配置集群节点之间的网络。如果配置了这个CALICO_IPV4POOL_VXLAN,不想集群外部通过bgp访问集群内,则可以将calico_backend改为vxlan。
- veth_mtu 在vxlan模式下配置应该要比主机网卡的mtu小50,在ipip模式下应小20,直接路由或bgp时和主机网卡一样大小。
- ippool配置
- CALICO_IPV4POOL_CIDR 集群pod网络的网段配置,如192.168.0.0/16
- CALICO_IPV4POOL_IPIP 是否使用calico的ipip封包,可选值Never,CrossSubnet,Always,CrossSubnet是只有跨子网的时候才使用ipip封包,否则使用直接路由模式。
- CALICO_IPV4POOL_VXLAN 和上面CALICO_IPV4POOL_IPIP配置相同,他们俩二选一。设置跨子网时的k8s的pod网络模式,该值配置为CrossSubnet,只有在集群节点跨不同的子网时才会使用vxlan封包,同一个子网下会采用直接路由模式。
- CALICO_IPV4POOL_BLOCK_SIZE 单个ip块的大小
- bgp配置
- IP_AUTODETECTION_METHOD 设置ip地址匹配模式,可以使用通过接口名配置,可以是逗号分割的接口名列表,每个条目是一个正则表达式。参考:https://docs.projectcalico.org/reference/node/configuration#ip-autodetection-methods,https://docs.projectcalico.org/networking/node。
- 其他配置
- 如果集群不使用bgp功能(calico_backend=vxlan),注释掉探测中的–bird-live和–bird-ready选项
crd资源
calico支持下列crd资源
[root@master1 ~]# kubectl api-resources | grep calico
# 针对于集群的全局bgp配置
bgpconfigurations crd.projectcalico.org/v1 false BGPConfiguration
# 配置哪些节点可以和哪些节点做peer
bgppeers crd.projectcalico.org/v1 false BGPPeer
blockaffinities crd.projectcalico.org/v1 false BlockAffinity
# calico集群状态信息
clusterinformations crd.projectcalico.org/v1 false ClusterInformation
# felix组件的配置
felixconfigurations crd.projectcalico.org/v1 false FelixConfiguration
# calico全局网络策略
globalnetworkpolicies crd.projectcalico.org/v1 false GlobalNetworkPolicy
# 全局网络结合,和policy配合使用的
globalnetworksets crd.projectcalico.org/v1 false GlobalNetworkSet
# 针对特定节点的配置
hostendpoints crd.projectcalico.org/v1 false HostEndpoint
# ip网段,配置,handler,程序内部使用
ipamblocks crd.projectcalico.org/v1 false IPAMBlock
ipamconfigs crd.projectcalico.org/v1 false IPAMConfig
ipamhandles crd.projectcalico.org/v1 false IPAMHandle
# ip地址池配置
ippools crd.projectcalico.org/v1 false IPPool
# kube-controllers组件的配置
kubecontrollersconfigurations crd.projectcalico.org/v1 false KubeControllersConfiguration
# 和global的一个意思
networkpolicies crd.projectcalico.org/v1 true NetworkPolicy
networksets crd.projectcalico.org/v1 true NetworkSetippools资源说明
所有CALICO_IPV4POOL*和CALICO_IPV6POOL*环境变量都是控制默认ippool的参数,如果NO_DEFAULT_POOLS不设置或为false,则calico/node在启动时会基于这些环境变量创建一个默认的ippool,pod的ip地址都是在ippool里分配的。
apiVersion: crd.projectcalico.org/v1
kind: IPPool
metadata:
name: default-ipv4-ippool
spec:
blockSize: 26
cidr: 10.248.0.0/13
# ipipMode和vxlanMode二选一
ipipMode: Always
natOutgoing: true
# 关联ippool到节点,参考:
# https://docs.projectcalico.org/reference/resources/ippool#node-selector
nodeSelector: all()
vxlanMode: Neveripamblocks示例
apiVersion: crd.projectcalico.org/v1
kind: IPAMBlock
metadata:
name: 10-249-40-64-26
spec:
affinity: host:master1
allocations:
- 0
- null
attributes:
- handle_id: ipip-tunnel-addr-master1
secondary:
node: master1
type: ipipTunnelAddress
cidr: 10.249.40.64/31
deleted: false
strictAffinity: false
unallocated:
- 1
- 2配置参考:https://docs.projectcalico.org/archive/v3.18/reference/resources/
配置网络
calico也支持vxlan和ipip网络,这两种网络组成上也非常类似。关于vxlan和ipip网络配置可参考:https://docs.projectcalico.org/networking/vxlan-ipip。
vxlan模式
calico的vxlan网络和flannel的非常类似,flannel默认使用bridge实现数据包如何进入pod和从pod出去,而calico使用路由决定。calico也支持同子网时直接路由,而跨子网时使用隧道。
vxlan模式不依赖bgp网络,所以当指定calico_backend=bird时,vxlan相关路由,直接路由信息不变。节点上多出bird进程,目的应该是将本节点pod信息发布到bgp网络,以便集群外节点可以通过bgp路由连接到集群内。
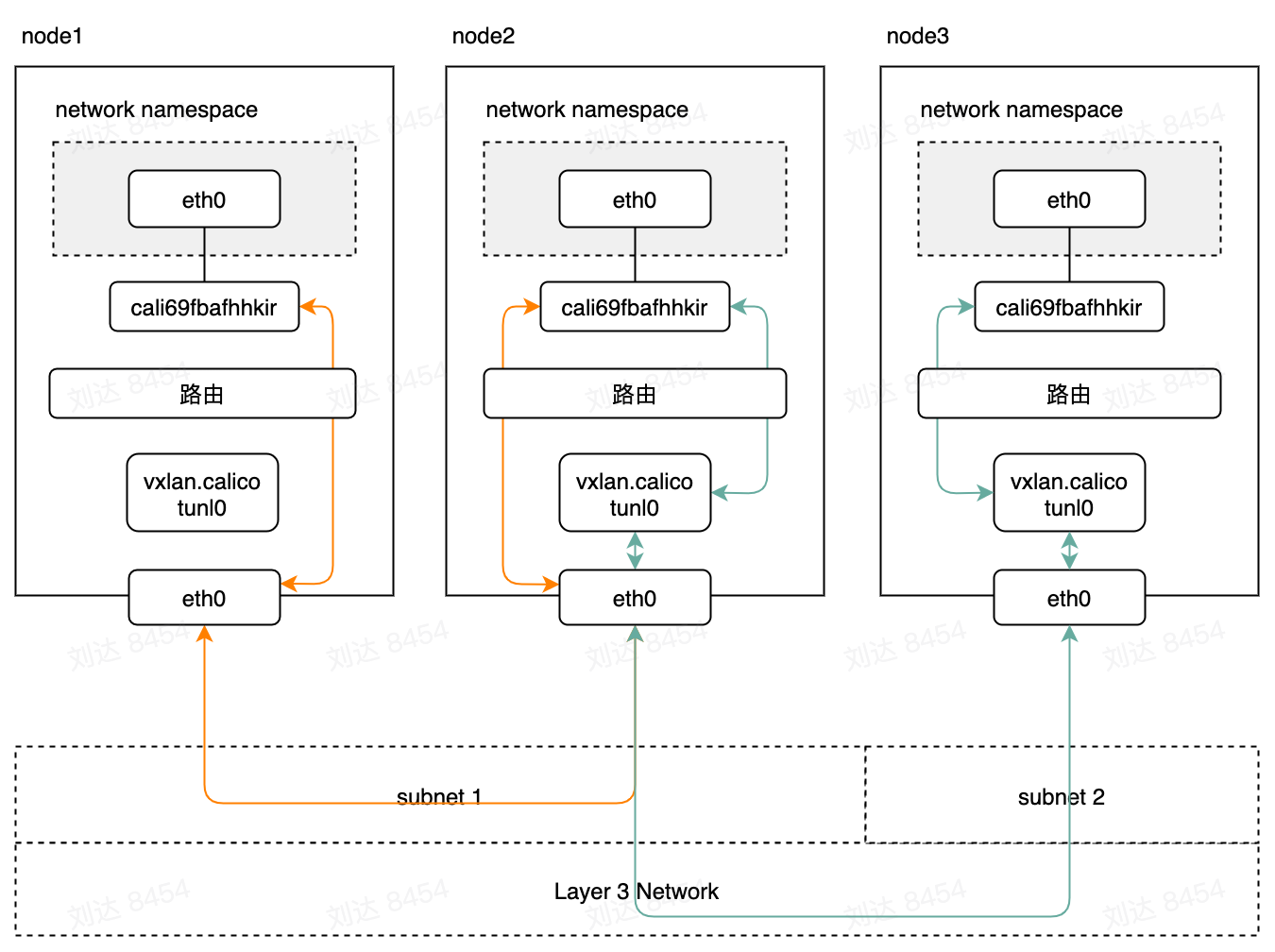
当
- CALICO_IPV4POOL_VXLAN=CrossSubnet(CALICO_IPV4POOL_IPIP=Never),并且主机属于同一个子网
[root@node1 ~]# ip route
default via 192.168.15.253 dev eth0
10.249.40.64/26 via 192.168.3.29 dev eth0 proto 80 onlink
10.250.180.0/26 via 192.168.3.30 dev eth0 proto 80 onlink
10.252.136.0/26 via 192.168.3.31 dev eth0 proto 80 onlink
10.253.11.0/26 via 192.168.3.32 dev eth0 proto 80 onlink
10.255.111.192/26 via 192.168.3.28 dev eth0 proto 80 onlink
10.253.149.0 dev cali01df9361120 scope link
10.253.149.1 dev calib7d7ae49653 scope link
10.253.149.2 dev cali155c22b71c8 scope link
10.253.149.3 dev cali5c252d67ecc scope link
10.253.149.4 dev cali443e68561ea scope link
10.253.149.5 dev cali69fb70dd9c5 scope link
10.253.149.6 dev calibf6903830b8 scope link
10.253.149.7 dev calic26326eb345 scope link当
- CALICO_IPV4POOL_VXLAN=Always(CALICO_IPV4POOL_IPIP=Never)或
- CALICO_IPV4POOL_VXLAN=CrossSubnet(CALICO_IPV4POOL_IPIP=Never)并且主机跨子网
[root@master1 init]# ip route
default via 192.168.15.253 dev eth0
10.249.40.64 dev cali521d494b967 scope link
blackhole 10.249.40.64/26 proto 80
10.250.180.0/26 via 10.250.180.0 dev vxlan.calico onlink
10.252.136.0/26 via 10.252.136.0 dev vxlan.calico onlink
10.253.11.0/26 via 10.253.11.0 dev vxlan.calico onlink
10.253.149.0/26 via 10.253.149.0 dev vxlan.calico onlink
10.255.111.192/26 via 10.255.111.192 dev vxlan.calico onlinkipip模式
ipip模式时需要依赖bgp网络,所以需要配置calico_backend=”bird”,否则不会创建各个ip隧道的路由信息。经测试,ipip网络内的子网到主机的路由不会因为该节点链接不到目标节点,而路由规则更新为额外的一跳。ipip网络的路由和flannel的没什么区别,都是直接路由到对应的节点,不管当前节点是否能访问到目标节点。
当
- CALICO_IPV4POOL_IPIP=CrossSubnet(CALICO_IPV4POOL_VXLAN=Never),并且主机属于同一个子网
[root@master1 init]# ip route
default via 192.168.15.253 dev eth0
10.249.40.64 dev cali521d494b967 scope link
10.250.180.0/26 via 192.168.3.30 dev eth0 proto bird
10.252.136.0/26 via 192.168.3.31 dev eth0 proto bird
10.253.11.0/26 via 192.168.3.32 dev eth0 proto bird
10.253.149.0/26 via 192.168.3.27 dev eth0 proto bird
10.255.111.192/26 via 192.168.3.28 dev eth0 proto bird当
- CALICO_IPV4POOL_IPIP=Always(CALICO_IPV4POOL_VXLAN=Never)或
- CALICO_IPV4POOL_IPIP=CrossSubnet(CALICO_IPV4POOL_VXLAN=Never)并且主机跨子网
[root@master1 init]# ip route
default via 192.168.15.253 dev eth0
10.249.40.64 dev cali521d494b967 scope link
10.250.180.0/26 via 192.168.3.30 dev tunl0 proto bird onlink
10.252.136.0/26 via 192.168.3.31 dev tunl0 proto bird onlink
10.253.11.0/26 via 192.168.3.32 dev tunl0 proto bird onlink
10.253.149.0/26 via 192.168.3.27 dev tunl0 proto bird onlink
10.255.111.192/26 via 192.168.3.28 dev tunl0 proto bird onlink配置bgp网络
按照功能来说,calico的bgp网络可以分为下列两种功能:
- 集群内bgp(iBGP)
- 在不使用overlay网络的情况下,calico的bgp用来配置集群内节点之间的子网路由自动更新配置。
- 在使用ipip模式overlay网络的情况下,calico的bgp用来配置集群内节点之间的子网路由自动更新配置。vxlan模式下不依赖于bgp做集群内的路由分发。
但是集群内bgp都是配置的直接路由,不管节点间是否可以访问,按理说应该支持两个节点不能直接访问的情况下,通过第三个节点作为路由。
- 集群外bgp(eBGP)
通过配置和集群外的路由配置bgp peer可以将集群内的pod,服务的clusterIP,externalIP和LoadBalancerIP发布到集群外的peer上,如果集群外的peer是一个路由器配置,那么所有连接到这个路由器的网络节点都可以通过ip地址直接访问到集群内的服务。如果这个路由器和其他路由器做了bgp peer,那么连接到其他路由器的网络节点也可以通过直接访问集群内的服务。
按照bgp网络的连接模型,calico的bgp网络可以由以下三种情况:
- 完全互联
默认情况下(当然是得指定了calico_backend=bird),calico会组建一个完全互联的网络,集群内的每个节点都和其他节点建立peer链接,通过iBGP协议交换路由信息。这种模式可以应用到任何二层网络,或者ipip模式的overlay网络。这种模式对于中小型网络(比如100节点以下)可以正常工作,但要支持更大集群规模,应该使用路由反射(route reflector)。
- 路由反射
要构建大型集群,可以使用路由反射技术,可以减少bgp peer链接的数量。在这种情况下,集群中一些节点充当route reflector功能使用。这些reflector之间在进行互相连接组成reflector mesh。其他节点则配置为连接到这些reflector中的某些节点(通常是两个做冗余)。
- 架顶模式(Top of Rack,TOR)
在私有部署环境中,可以配置calico直接和机房里的屋里设备直连。这种模式下一般会禁用掉完全互联,并配置calico和机架(机柜)的L3路由器直连做peer。在这种情况下有多种配置方案,取决于实际需求。
禁用完全互联
由于默认是完全互联的bgp网络,在做一些高级配置之前,需要禁用掉完全互联。
calicoctl patch bgpconfiguration default -p '{"spec": {"nodeToNodeMeshEnabled": false}}'配置全局peer
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: my-global-peer
spec:
peerIP: 192.20.30.40
asNumber: 64567为特定节点配置peer
apiVersion: projectcalico.org/v3
kind: BGPPeer
metadata:
name: rack1-tor
spec:
peerIP: 192.20.30.40
asNumber: 64567
nodeSelector: rack == 'rack-1'配置路由反射
calico节点可以用配置为route reflector。首先需要给相应的node配上ID,通常是一个未被使用的ip地址:
calicoctl patch node my-node -p '{"spec": {"bgp": {"routeReflectorClusterID": "244.0.0.1"}}}'然后为这个节点打上标签以表明这是个reflector
kubectl label node my-node route-reflector=true接下来就是配置哪些哪些节点可以和哪些reflector做peer,下面的配置是所有节点和刚才的reflector做peer。
kind: BGPPeer
apiVersion: projectcalico.org/v3
metadata:
name: peer-with-route-reflectors
spec:
nodeSelector: all()
peerSelector: route-reflector == 'true'配置路由发布:https://docs.projectcalico.org/networking/advertise-service-ips
配置cni
https://docs.projectcalico.org/networking/ipam
https://docs.projectcalico.org/reference/cni-plugin/configuration
calico支持host-local和calico-ipam两种ip地址分配插件。
calico-ipam分配ip地址是在ipblock中进行分配,节点和ipblock关联,ipblock可以动态申请,节点上的pod数量和多时可以关联多个ipblock。
host-local分配ip地址需要从一个预定义的网段里进行分配,配置calico使用host-local的话,那么这个网段则使用的是Node.Spec.PodCIDR字段。
calico cni支持为pod分配虚ip:https://docs.projectcalico.org/networking/add-floating-ip。
calico cni支持为pod分配静态ip地址,但是ip地址必须在集群的cluster-cidr和ippool内:https://docs.projectcalico.org/networking/use-specific-ip。
网络策略
https://docs.projectcalico.org/archive/v3.18/security/get-started
eBPF数据面
https://docs.cilium.io/en/stable/bpf/
calico目前ebpf不支持ipv6。通常来讲,ebpf相比于iptables具有这些优点:
- 首包延迟和后续包延迟更低
- 完全支持客户端地址保留
- 服务端直接返回
- 4倍于基于iptables的数据面的吞吐量(是否需要硬件支持没写)
ebpf和iptables或ipvs模式的性能对比测试可以参考测试1和测试2。如果开启了网络策略,那么会有更多的iptables规则影响网络性能。
calico会在pod网卡,隧道网卡,主机网卡上挂上ebpf程序 ,这样calico就可以在早期处理数据包的转发和过滤功能,从而直接跳过iptables。
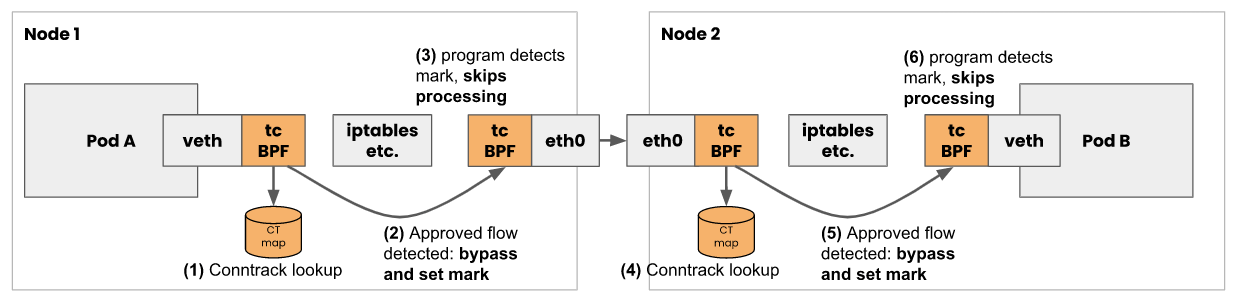
calico将网略策略转换成ebpf map中的数据结构,通过ip set匹配策略选择器。
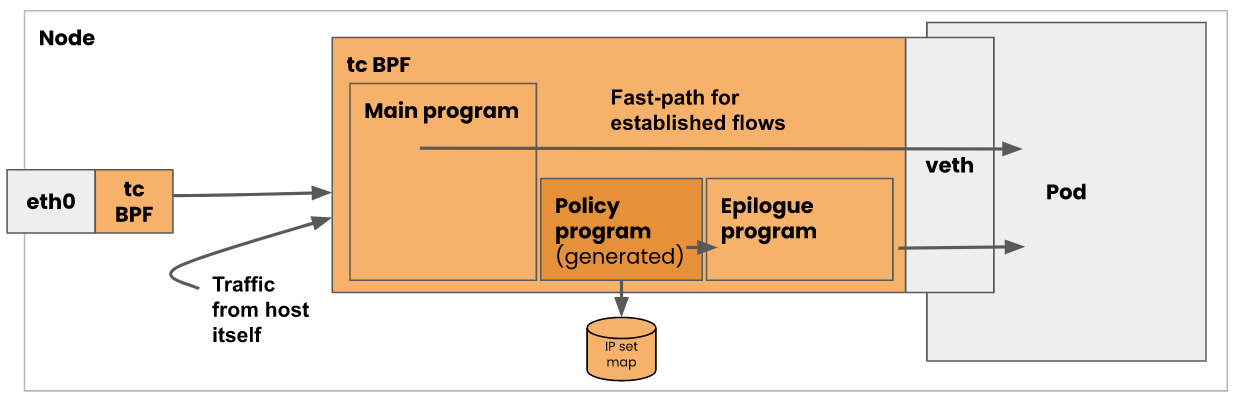
calico还具备连接时负载的功能,通过socket的ebpf hook,calico可以在应用连接kubernetes服务的时候修改目的地址为pod的ip,避免了使用nat机制。
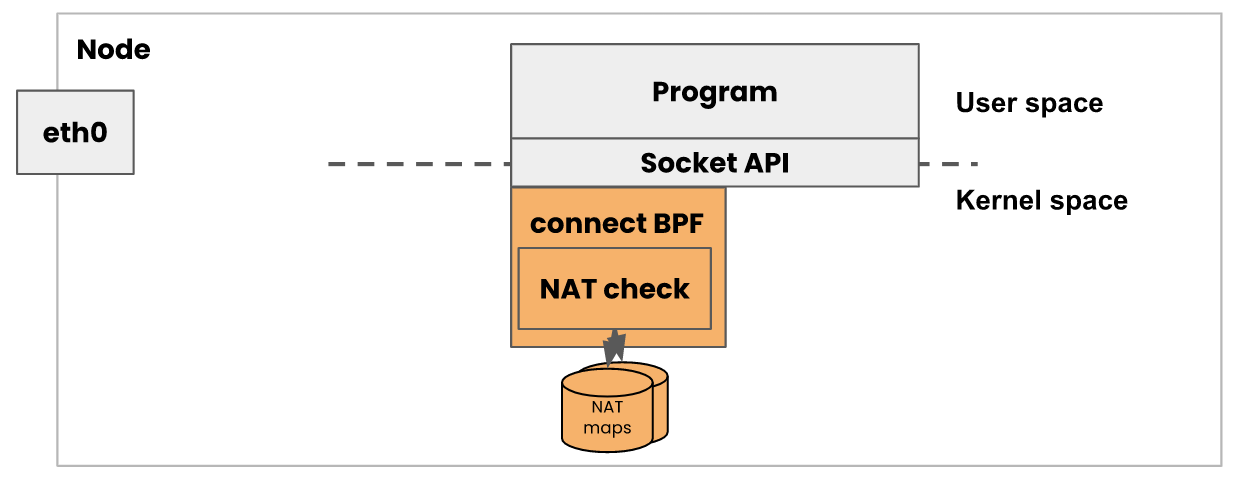
calico中,ebpf程序是基于c+llvm进行开发的,会由calico/node进程将其挂载到内核钩子上。calico的go代码部分负责维护map存储,动态管理不同表中的策略,转发等规则。
文章导航
1 Reply to “kubernetes网络 – 网络插件 – calico”
发表回复
1. 概述
Calico是一个基于 BGP 的纯三层网络方案。它在每个计算节点都利用 Linux kernel 实现了一个高效的虚拟路由器 vRouter 来进行数据转发。每个 vRouter 都通过 BGP 协议将本节点上运行容器的路由信息向整个 Calico 网络广播,并自动设置到达其他节点的路由转发规则。
Calico 保证所有容器之间的数据流量都通过 IP 路由的方式完成互联互通。Calico 节点组网可以直接利用数据中心的网络结构 (L2/L3),不需要额外的 NAT,隧道或者 Overlay 网络,没有额外的封包解包,节省 CPU 资源,提高网络效率。
2. 架构
工作组件:
Felix:运行在每台节点上的 agent 进程。主要负责路由维护和ACLs(访问控制列表),使得该主机上的 endpoints 资源正常运行提供所需的网络连接
Etcd:持久化存储 calico 网络状态数据
BIRD (BGP Client):将 BGP 协议广播告诉剩余的 calico 节点,从而实现网络互通
BGP Route Reflector:BGP 路由反射器,可选组件,用于较大规模组网
3. 部署
清理cni相关配置:
ip link set cni0 down
ip link delete cni0
rm -rf /etc/cni/net.d
rm -rf /var/lib/cni
安装 Calico:
# 1. 下载插件
$ wget https://docs.projectcalico.org/v3.20/manifests/calico.yaml
# CIDR的值,与 kube-controller-manager中“--cluster-cidr=10.244.0.0/16” 一致
$ vi calico.yaml
...
spec:
...
template:
...
spec:
...
containers:
...
- name: calico-node
...
env:
- name: DATASTORE_TYPE
value: "kubernetes"
- name: IP_AUTODETECTION_METHOD # new add, multi interfaces
value: interface=ens33
...
# Auto-detect the BGP IP address.
- name: IP
value: "autodetect"
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP # IPIP mode by default
value: "Always"
# Enable or Disable VXLAN on the default IP pool.
- name: CALICO_IPV4POOL_VXLAN
value: "Never"
...
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
# 2. 安装网络插件
$ kubectl apply -f calico.yaml
# 3. 检查是否启动
$ kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-654b987fd9-cq26z 1/1 Running 0 11m
calico-node-fkcvj 1/1 Running 0 11m
calico-node-np65c 1/1 Running 0 11m
calico-node-p8g9t 1/1 Running 0 11m
# 4. 节点状态正常
$ kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready control-plane,master 7d18h v1.21.4
k8s-node01 Ready <none> 7d18h v1.21.4
k8s-node02 Ready <none> 7d18h v1.21.4
# 5. 安装管理工具
$ wget -O /usr/local/bin/calicoctl https://github.com/projectcalico/calicoctl/releases/download/v3.20.4/calicoctl-linux-amd64
$ chmod +x /usr/local/bin/calicoctl
# 6. 节点状态
$ calicoctl node status
Calico process is running.
IPv4 BGP status
+----------------+-------------------+-------+----------+-------------+
| PEER ADDRESS | PEER TYPE | STATE | SINCE | INFO |
+----------------+-------------------+-------+----------+-------------+
| 192.168.80.101 | node-to-node mesh | up | 06:15:16 | Established |
| 192.168.80.102 | node-to-node mesh | up | 06:15:15 | Established |
+----------------+-------------------+-------+----------+-------------+
IPv6 BGP status
No IPv6 peers found.
创建测试应用:
# busybox-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: busybox-deploy
spec:
replicas: 3
selector:
matchLabels:
app: busybox
template:
metadata:
labels:
app: busybox
spec:
containers:
- name: busybox
image: busybox:1.28.4
command:
- sleep
- "86400"
4. IPIP 模式
将一个IP数据包封装到另一个IP包中,即把IP层封装到IP层的一个tunnel。其作用基本相当于一个基于IP层的网桥。一般来说,普通的网桥是基于mac层的,不需要IP,而这个IPIP则通过两端的路由做一个 tunnel,把两个本来不通的网络通过点对点连接起来。
配置环境变量:CALICO_IPV4POOL_IPIP=Always
流量:tunl0设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
效率:流量需要tunl0设备封装,效率略低。
4.1 Pod 网络
$ kubectl get pod -l app=busybox -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-deploy-5c8bbcc5f7-ddmm9 1/1 Running 0 68s 10.244.58.193 k8s-node02 <none> <none>
busybox-deploy-5c8bbcc5f7-fhqvh 1/1 Running 0 68s 10.244.85.194 k8s-node01 <none> <none>
busybox-deploy-5c8bbcc5f7-ksr4z 1/1 Running 0 68s 10.244.58.194 k8s-node02 <none> <none>
$ kubectl exec -it busybox-deploy-5c8bbcc5f7-ddmm9 -- /bin/sh
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if13: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1480 qdisc noqueue
link/ether 06:bf:22:76:89:a9 brd ff:ff:ff:ff:ff:ff
inet 10.244.58.193/32 brd 10.244.58.193 scope global eth0
valid_lft forever preferred_lft forever
/ # ip route
default via 169.254.1.1 dev eth0 # 默认写死的路由IP地址
169.254.1.1 dev eth0 scope link
4.2 宿主机网络
节点:k8s-node02
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.80.2 0.0.0.0 UG 0 0 0 ens33
10.244.1.0 192.168.80.101 255.255.255.0 UG 0 0 0 tunl0
10.244.58.192 0.0.0.0 255.255.255.192 U 0 0 0 *
10.244.58.193 0.0.0.0 255.255.255.255 UH 0 0 0 cali918b33f2bbe
10.244.58.194 0.0.0.0 255.255.255.255 UH 0 0 0 cali54491a66381
10.244.85.192 192.168.80.101 255.255.255.192 UG 0 0 0 tunl0 # 使用隧道tunl0, 访问10.244.85.192/26网络
10.244.235.192 192.168.80.100 255.255.255.192 UG 0 0 0 tunl0
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.70.0 0.0.0.0 255.255.255.0 U 0 0 0 ens38
192.168.80.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
补充:路由Flags含义
U: up
H: host,主机路由,多为达到数据包的路由
G: gateway,网络路由,如果没有说明目的地是直连的
D: Dynamically 该路是重定向报文修改
M: 该路由已被重定向报文修改
ping包流程:10.244.85.195/26 => 10.244.85.192 =>192.168.80.241,即通过tul0发到k8s-node01
4.3 抓包分析
节点 k8s-node01 上的 pod 访问 k8s-node02 上的pod:
$ kubectl exec -it busybox-deploy-5c8bbcc5f7-ddmm9 -- /bin/sh
# ping 10.244.85.194
节点 k8s-node02 上:
$ tcpdump -i ens33 -vvv -w ipip.pcap
15. BGP 模式
边界网关协议(Border Gateway Protocol)是互联网上一个核心的去中心化自治路由协议。它通过维护IP路由表或前缀来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而使用基于路径、网络策略或规则集来决定路由。因此,它更适合称为矢量性协议,而不是路由协议。
BGP通俗讲就是接入到机房的多条线路融合为一体,实现多线单IP。BGP机房优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其他技术指标来确定的,不会占用服务器的任何系统。
配置环境变量:CALICO_IPV4POOL_IPIP=Never
流量:使用主机路由表信息导向流量
适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
效率:原生hostGW,效率高。
5.1 Pod 网络
$ kubectl get pod -l app=busybox -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox-deploy-5c8bbcc5f7-94fqh 1/1 Running 0 15s 10.244.58.192 k8s-node02 <none> <none>
busybox-deploy-5c8bbcc5f7-m2h72 1/1 Running 0 15s 10.244.58.193 k8s-node02 <none> <none>
busybox-deploy-5c8bbcc5f7-rxmcc 1/1 Running 0 15s 10.244.85.193 k8s-node01 <none> <none>
$ kubectl exec -it busybox-deploy-5c8bbcc5f7-94fqh -- /bin/sh
/ # route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
/ # ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: tunl0@NONE: <NOARP> mtu 1480 qdisc noop qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
4: eth0@if17: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 4e:77:d1:be:6c:fc brd ff:ff:ff:ff:ff:ff
inet 10.244.58.192/32 brd 10.244.58.192 scope global eth0
valid_lft forever preferred_lft forever
5.2 宿主机网络
节点 k8s-node02:
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.80.2 0.0.0.0 UG 0 0 0 ens33
10.244.1.0 192.168.80.101 255.255.255.0 UG 0 0 0 ens33
10.244.58.192 0.0.0.0 255.255.255.255 UH 0 0 0 cali86c3817fabd
10.244.58.192 0.0.0.0 255.255.255.192 U 0 0 0 *
10.244.58.193 0.0.0.0 255.255.255.255 UH 0 0 0 calib35fb91ccc9
10.244.85.192 192.168.80.101 255.255.255.192 UG 0 0 0 ens33 # 10.244.85.192 网段走路由
10.244.235.192 192.168.80.100 255.255.255.255 UGH 0 0 0 ens33
172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 docker0
192.168.70.0 0.0.0.0 255.255.255.0 U 0 0 0 ens38
192.168.80.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33
$ ip route
default via 192.168.80.2 dev ens33 proto static
10.244.1.0/24 via 192.168.80.101 dev ens33 proto bird
10.244.58.192 dev cali86c3817fabd scope link
blackhole 10.244.58.192/26 proto bird # 黑洞路由,如果没有其他优先级更高的路由,主机会将所有目的地址为10.244.58.192/26的网络数据丢弃掉
10.244.58.193 dev calib35fb91ccc9 scope link
10.244.85.192/26 via 192.168.80.101 dev ens33 proto bird
10.244.235.192 via 192.168.80.100 dev ens33 proto bird
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
192.168.70.0/24 dev ens38 proto kernel scope link src 192.168.70.102
192.168.80.0/24 dev ens33 proto kernel scope link src 192.168.80.102
5.3 互通
calico使用BGP网络模式通信网络传输速率较好,但是跨节点后pod不能通信。
k8s-node02 上的 pod 尝试访问 k8s-node01 上的pod,失败:
$ kubectl exec -it busybox-deploy-5c8bbcc5f7-94fqh -- /bin/sh
/ # ping -c 3 10.244.85.193
PING 10.244.85.193 (10.244.85.193): 56 data bytes
--- 10.244.85.193 ping statistics ---
3 packets transmitted, 0 packets received, 100% packet loss
6. 总结
6.1 IPIP vs BGP
IPIP BGP
流量 tunl0封装数据,形成隧道,承载流量 路由信息导向流量
适用场景 Pod跨网段互访 Pod同网段互访,适合大型网络
效率 需要tunl0设备封装,效率略低 原生hostGW, 效率高
类型 overlay underlay
6.2 Calico 问题
缺乏租户隔离
Calico的三层方案是直接在host上进行路由寻址,多租户如果想使用同一个 CIDR网络将面临地址冲突问题
路由规模
路由规模和pod分布有关,如果pod离散分布在host集群中,势必产生较多的额路由项
iptables规则规模
每个容器实例都会产生iptables规则,当实例多时,过多的iptables规则会造成负责性和不可调试性,同时也存在性能损耗
跨子网时的网关路由问题
当对端网络不为二层可达时,需要通过三层路由器,此时网关要支持自定义路由配置,即Pod的目的地址为本网段的网关地址,再由网关进行跨三层转发
————————————————
版权声明:本文为CSDN博主「elihe2011」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/elihe2011/article/details/123075118

卧槽!牛逼!