
Windows上安装运行Spark
1.下载Scala: https://www.scala-lang.org/download/
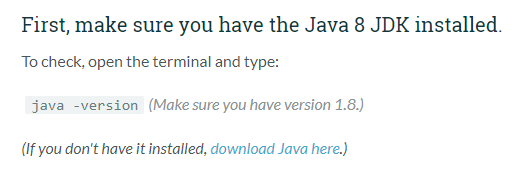
①注意:必须下载官方要求的JDK版本,并设置JAVA_HOME,否则后面将出现很多麻烦!
②Scala当前最新版本为2.13.0,但是建议不要使用最新的版本,此处下载的是2.11.12
Scala所有版本列表:https://www.scala-lang.org/download/all.html

③设置环境变量

2.安装后在cmd中输入scala出现如下提示表示成功

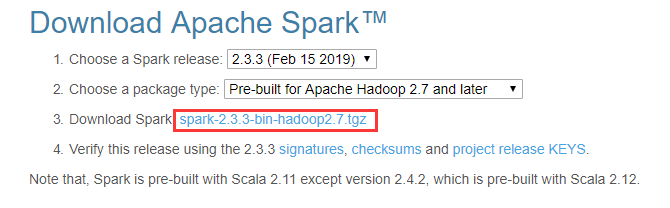
3.下载Spark:http://spark.apache.org/downloads.html
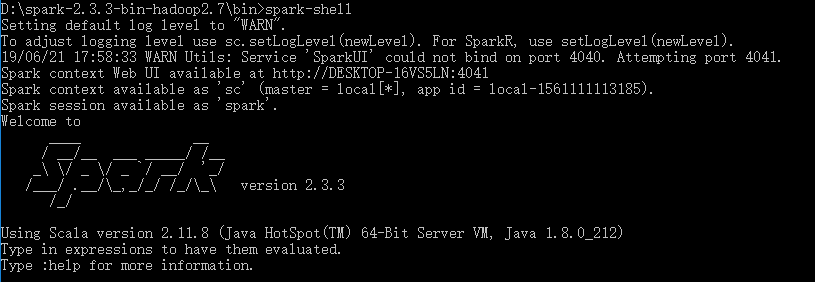
4.进入spark-2.3.3-bin-hadoop2.7\bin,cmd中输入spark-shell
①出现下面错误,表示需要安装python。安装时选择加到系统路径中,安装完cmd中输入python验证是否安装成功。

②出现下面错误,表示找不到Hadoop。需要安装Hadoop并设置HADOOP_HOME的系统路径。关于Windows下的Hadoop安装,可以参考《Windows上安装运行Hadoop》。

③出现下面的WARN可以不用理会,正常使用。

如果实在受不了WARN的话,则在spark-2.3.3-bin-hadoop2.7\conf\log4j.properties(默认是有template后缀的,直接去掉这个后缀)中增加
log4j.logger.org.apache.hadoop.util.NativeCodeLoader=ERROR
④屏蔽后的显示
下面的内容为使用IDEA写一个Scala的demo并使用Spark-submit运行。
5.下载IDEA的Scala插件

6.创建Scala的IDEA项目

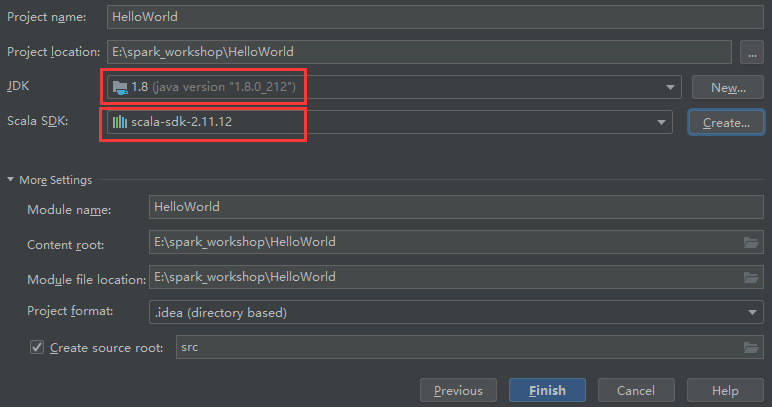
7.选择相应的JDK和Scala,创建一个HelloWorld项目
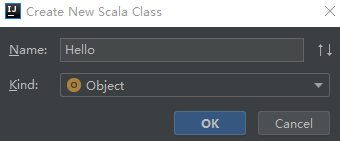
8.创建一个名字为Hello的Scala Object,会生成一个Hello.scala文件
9.在文件中输入如下代码
object Hello {
def main(args: Array[String]): Unit = {
println("Hello World");
}
}
10.在IDEA中Run一下,正常显示

11.使用Project Structure->Artifacts打包成HelloWorld.jar
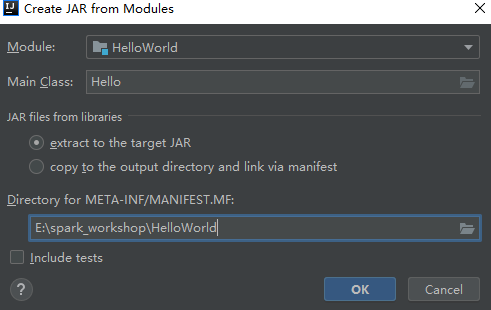
12.将HelloWorld.jar拷贝到spark-2.3.3-bin-hadoop2.7\bin中,在cmd中执行
spark-submit --class Hello HelloWorld.jar

以上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号