
如何使用 libtorch 实现 AlexNet 网络?
如何使用 libtorch 实现 AlexNet 网络?
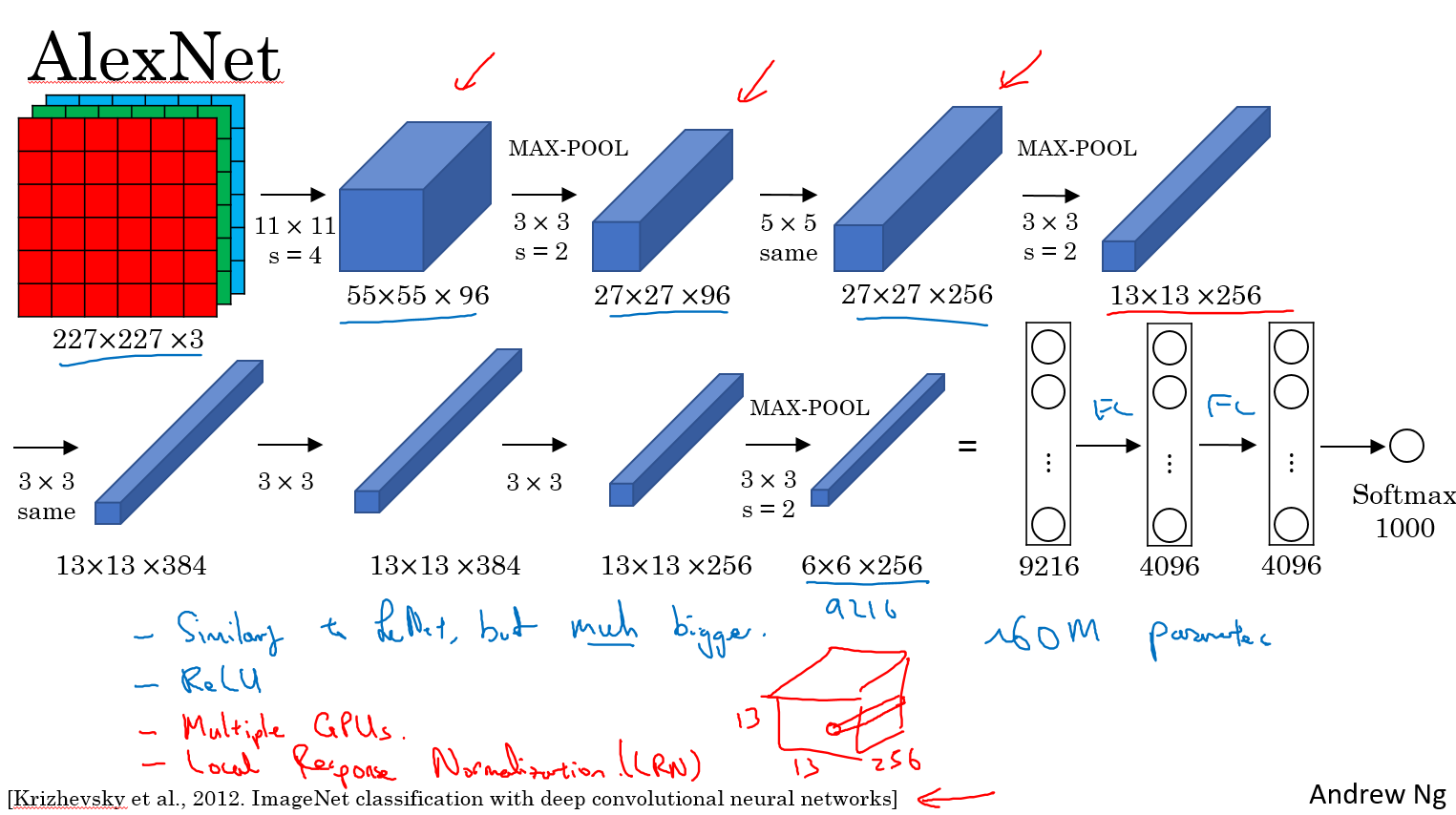
按照图片上流程写即可。输入的图片大小必须 227x227 3 通道彩色图片
// Define a new Module.
struct Net : torch::nn::Module {
Net() {
conv1 = torch::nn::Conv2d(torch::nn::Conv2dOptions(3, 96, { 11,11 }).stride({4,4}));
conv2 = torch::nn::Conv2d(torch::nn::Conv2dOptions(96, 256, { 5,5 }).padding(2));
conv3 = torch::nn::Conv2d(torch::nn::Conv2dOptions(256, 384, { 3,3 }).padding(1));
conv4 = torch::nn::Conv2d(torch::nn::Conv2dOptions(384, 384, { 3,3 }).padding(1));
conv5 = torch::nn::Conv2d(torch::nn::Conv2dOptions(384, 256, { 3,3 }).padding(1));
fc1 = torch::nn::Linear(256*6*6,4096);
fc2 = torch::nn::Linear(4096, 4096);
fc3 = torch::nn::Linear(4096, 1000);
}
// Implement the Net's algorithm.
torch::Tensor forward(torch::Tensor x) {
x = conv1->forward(x);
x = torch::relu(x);
//LRN
x = torch::max_pool2d(x, { 3,3 }, { 2,2 });
x = conv2->forward(x);
//LRN
x = torch::relu(x);
x = torch::max_pool2d(x, { 3,3 }, { 2,2 });
x = conv3->forward(x);
x = torch::relu(x);
x = conv4->forward(x);
x = torch::relu(x);
x = conv5->forward(x);
x = torch::relu(x);
x = torch::max_pool2d(x, { 3,3 }, { 2,2 });
x = x.view({ x.size(0),-1 });
x = fc1->forward(x);
x = torch::relu(x);
x = torch::dropout(x,0.5,is_training());
x = fc2->forward(x);
x = torch::relu(x);
x = torch::dropout(x, 0.5, is_training());
x = fc3->forward(x);
x = torch::log_softmax(x,1);
return x;
}
// Use one of many "standard library" modules.
torch::nn::Conv2d conv1{ nullptr };
torch::nn::Conv2d conv2{ nullptr };
torch::nn::Conv2d conv3{ nullptr };
torch::nn::Conv2d conv4{ nullptr };
torch::nn::Conv2d conv5{ nullptr };
torch::nn::Linear fc1{ nullptr };
torch::nn::Linear fc2{ nullptr };
torch::nn::Linear fc3{ nullptr };
};
具体可参考这个
name: "AlexNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "conv1"
top: "conv1"
}
layer {
name: "norm1"
type: "LRN"
bottom: "conv1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "norm1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 2
kernel_size: 5
group: 2
}
}
layer {
name: "relu2"
type: "ReLU"
bottom: "conv2"
top: "conv2"
}
layer {
name: "norm2"
type: "LRN"
bottom: "conv2"
top: "norm2"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "norm2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "conv3"
type: "Convolution"
bottom: "pool2"
top: "conv3"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
}
}
layer {
name: "relu3"
type: "ReLU"
bottom: "conv3"
top: "conv3"
}
layer {
name: "conv4"
type: "Convolution"
bottom: "conv3"
top: "conv4"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 384
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu4"
type: "ReLU"
bottom: "conv4"
top: "conv4"
}
layer {
name: "conv5"
type: "Convolution"
bottom: "conv4"
top: "conv5"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 256
pad: 1
kernel_size: 3
group: 2
}
}
layer {
name: "relu5"
type: "ReLU"
bottom: "conv5"
top: "conv5"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8"
type: "InnerProduct"
bottom: "fc7"
top: "fc8"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
inner_product_param {
num_output: 1000
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8"
top: "prob"
}
转载请注明出处并保持作品的完整性,谢谢

