

Perceptron, Support Vector Machine and Dual Optimization Problem (2)
Generalizing Linear Classification
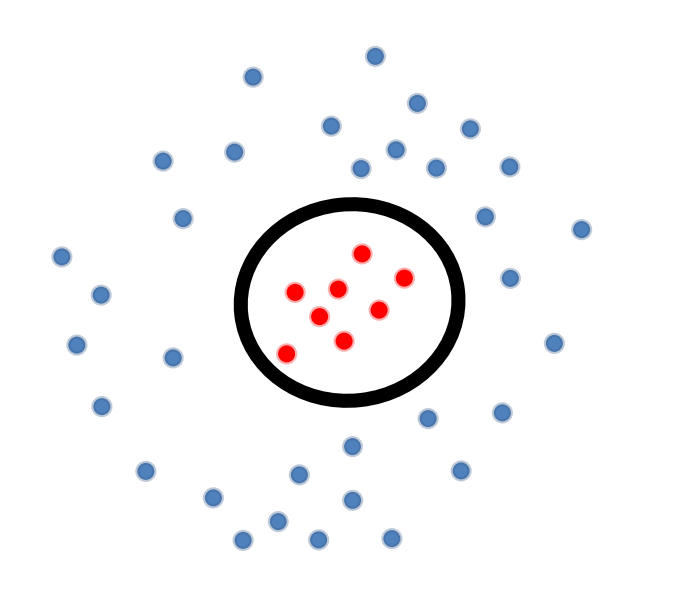
假设我们有如上图的 training data,注意到此时 。
那么 decision boundary :
即,decision boundary 为某种椭圆,例如:半径为 的圆(),如上图中的黑圈所示。我们会发现,此时 decision boundary not linear in 。
但是, 在某些空间里却是线性的:
因此,如果我们对数据进行特征变换(feature transformation):
那么 在 transformed feature space 中变为线性的。
Geometric view on feature transformation
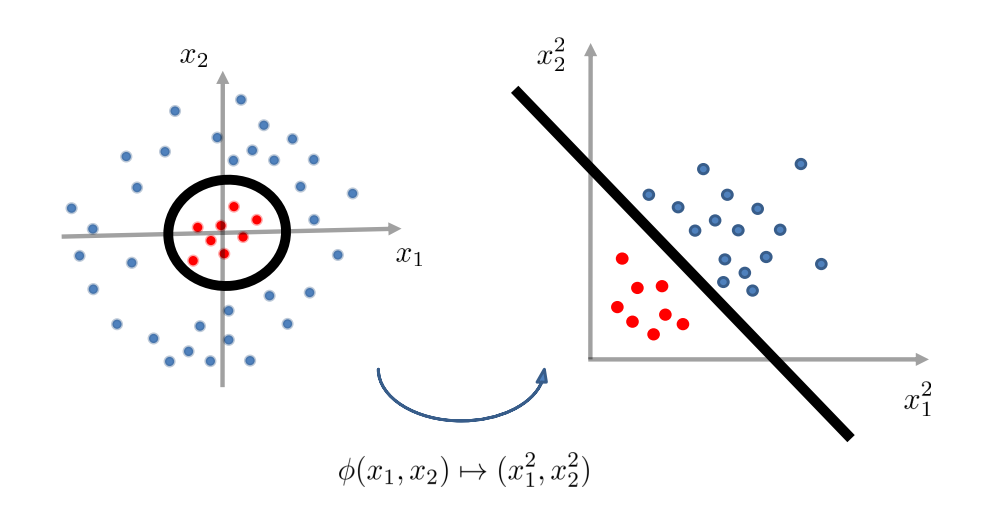
Feature Transformation for Quadratic Boundaries
case
generic quadratic boundary 如下:
feature transformation 则为:
case
generic quadratic boundary 如下:
feature transformation 则为:
- 注意,以上的 以及下面会提到的 指的是数据的维度。
Theorem.
给定 个互不相同的数据点:,总是存在一个 feature transformation ,使得无论的 的 label 如何,它在 transformed space 中总是线性可分的。
Proof.
给定 个数据点,考虑以下映射(映射至 ):
即,映射为一个 one-hot 向量,除第 行处为 ,其它坐标处的值都为 。
那么,由 linear weighting 引出的 decision boundary 完美地分割了 input data。
-
解释:
证明的意思是,输入的数据有 个。对于每一个数据点,feature transform 到一个 one-hot vector,只有这条数据在输入的 个数据中排的位置所对应的坐标处取 ,其余全部取 。假设输入三个数据:,则:
这样极端的操作有利有弊:
-
优点:
任意的问题都将变为 linear separable。
-
缺点:
-
计算复杂度:
generic kernel transform 的时间复杂度通常是 ,有些常用的 kernel transform 将 input space 映射到 infinite dimensional space 中。
-
模型复杂度:
模型的概括能力(generalization performance)通常随模型复杂度的下降而下降。即,若向简化模型,通常需要以牺牲模型的表现作为代价。
-
-
回顾时间复杂度 的定义:
那么 满足:
也就是说时间复杂度最低也与 呈线性。
The Kernel Trick (to Deal with Computation)
如果直接暴露在 generic kernel space 中进行运算,需要时间复杂度 。但是相对而言地,kernel space 中的两个数据点的点积可以被更快地求出,即:
Examples.
-
在 空间中的数据的 quadratic kernel transform:
-
Explicit transform:
-
Dot products:
-
-
径向基函数(Radial Basis Function, i.e., RBF):
-
Explicit transform:infinite dimension!
-
Dot products:
-
Kernel 变换的诀窍在于,在实现分类算法的时候只通过 “点积” 的方式接触数据。
Examples.
The Kernel Perceptron(核感知机)
回忆感知机算法,更新权重向量的核心步骤为:
等价地,算法可以写为:
其中, 为在 上发生错误的次数。
因此,分类问题变为:
其中 输入函数 的新数据向量,注意与 区分。
因此,在空间内的分类问题:
若在 tranformed kernel space 中处理,则:
算法具体如下:
在最后注意到, 中的点积 是相似度(similarity)的一种衡量方式,故自然能够被其它自定义的相似度衡量方式所替换。
所以,我们可以在任意自定义的非线性空间中,隐性地(implicitly)进行运算,而不需要承担可能的巨大计算量成本。
本文来自博客园,作者:车天健,转载请注明原文链接:https://www.cnblogs.com/chetianjian/p/17270426.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构