
利用Tess4J实现图片识别
一、下载
1.进入官网下载页面
https://sourceforge.net/projects/tess4j/
2.点击download
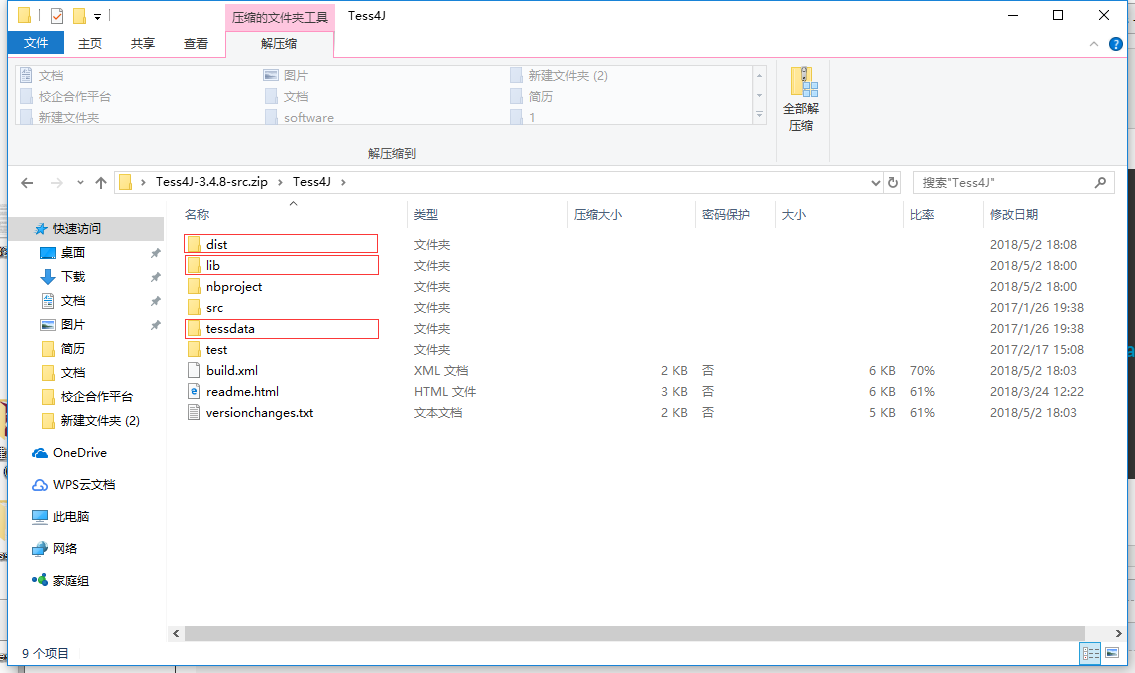
3.下载后解压,目录如下,圈出的三个文件夹是需要用到的
二、使用Tess4J
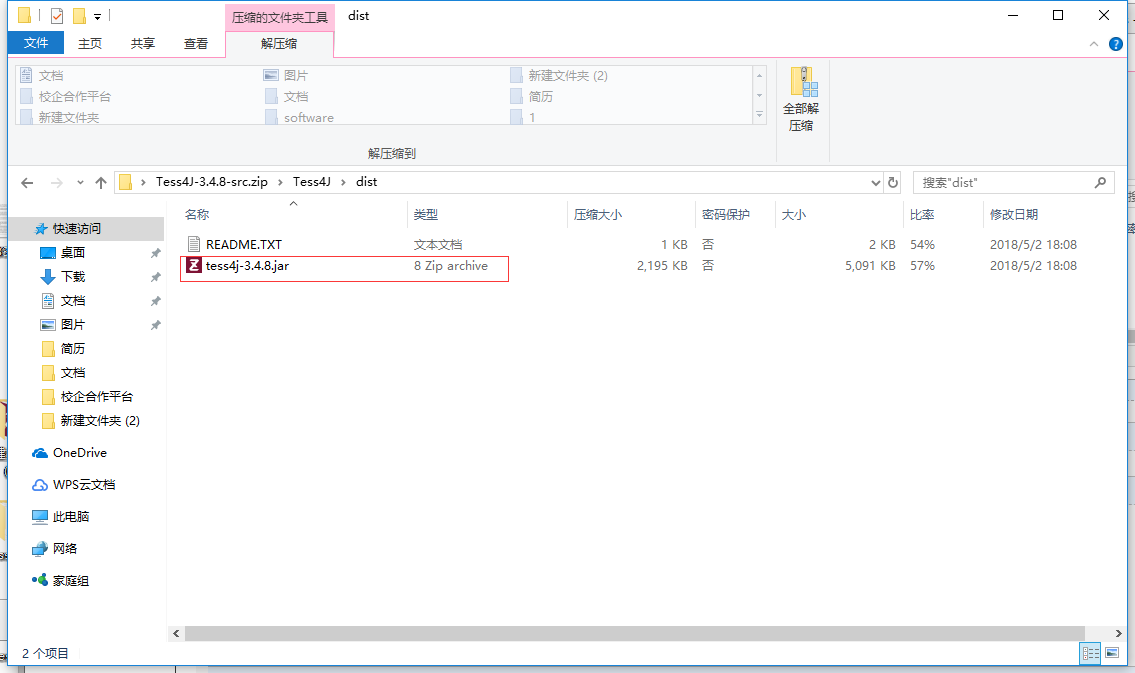
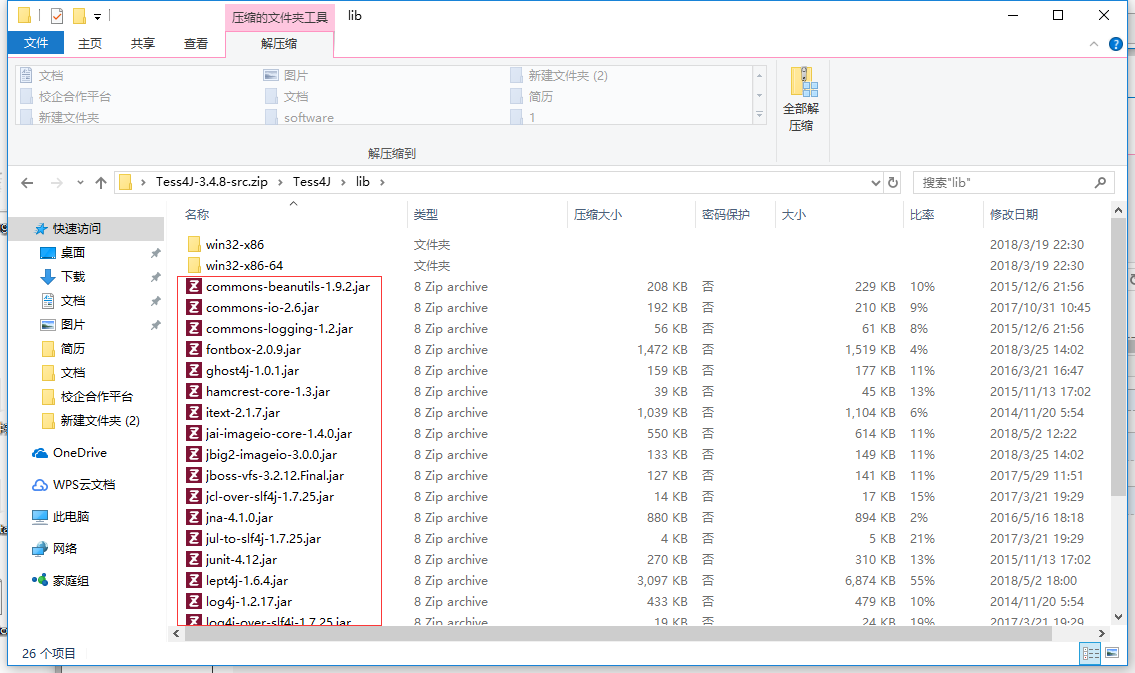
1.将dist和lib下的包导入java项目
2.将 tessdata 文件夹复制进项目的根目录
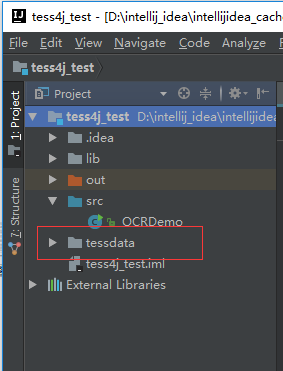
3.示范代码如下
public class OCRDemo { public static void main(String[] args) { try { double start=System.currentTimeMillis(); File imageFile = new File("C:\\Users\\dan\\Desktop\\12345.png");//图片位置 ITesseract instance = new Tesseract(); //instance.setDatapath("");//设置tessdata位置 instance.setLanguage("chi_sim");//选择字库文件 String result = instance.doOCR(imageFile);//开始识别 double end=System.currentTimeMillis(); System.out.println(result);//打印图片内容 System.out.println("耗时"+(end-start)/1000+" s"); } catch (TesseractException e) { e.printStackTrace(); } } }
注意事项:
①如果tessdata没有放入根目录,务必设置teedata的位置
instance.setDatapath("");//设置tessdata位置
②选择字库文件不需要写上后缀,默认 tessdata 包中可能没有 chi_sim 这个中文包,需要自己下载
https://github.com/tesseract-ocr/tessdata
三、运行结果

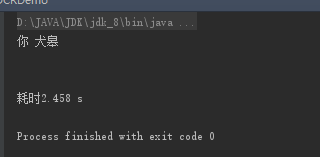
官方字库识别率还是偏低的,如果对精度要求高的话需要自己训练字库了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号