
torch中DataLoader加载字典
参考资料:
https://pytorch.org/docs/stable/data.html
我们都知道,Pytorch加载数据的常规流程是先定义一个Dataset,然后使用DataLoader来成Batch地加载数据。当我们在Dataset中定义的__getitem__返回的数据是array或者tensor的话,Pytorch都会尽量地将数据转换为tensor并将数据叠起来添加一个batch_size维度。也就是实现类似torch.stack的效果。
但是,如果Dataset中定义的__getitem__返回的是一个字典的话,Pytorch更展现了其智能之处。
下面一个截图展示了我的实验结果:
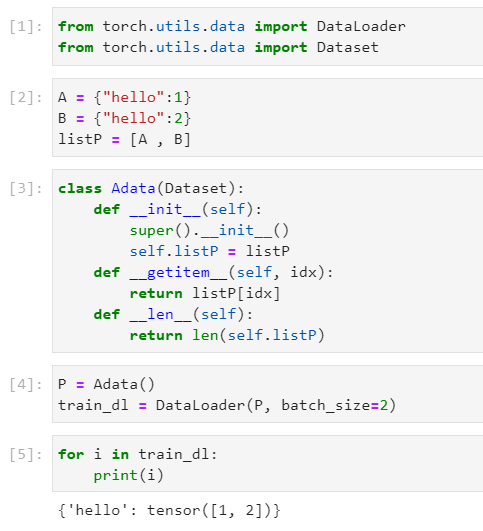
即,当我们的Dataset返回的是一个字典时,Pytorch不会傻傻地将字典“叠起来”交给你,而是会遍历字典的每一个key,然后将对应key下面的键值叠起来,最后返回一个字典!而这正是我们预期的好的行为!

