
深度学习中常见的激活函数
上一篇文章介绍了激活函数的作用,就想一并整理一下深度学习领域中常见的激活函数。在深度学习中,常见的激活函数有三种:sigmoid函数,tanh函数,ReLU函数。我们可以在LSTM网络中同时见到tanh函数和sigmoid函数,ReLU函数对于CNN则是不可缺少的。
下面分别进行介绍。
1.sigmoid函数(S型增长函数)
sigmoid函数能够将取值为$(-\infty,+\infty)$的数映射到$(0,1)$。公式和图形如下:$$S(x)=\frac{1}{1+e^{-z}}$$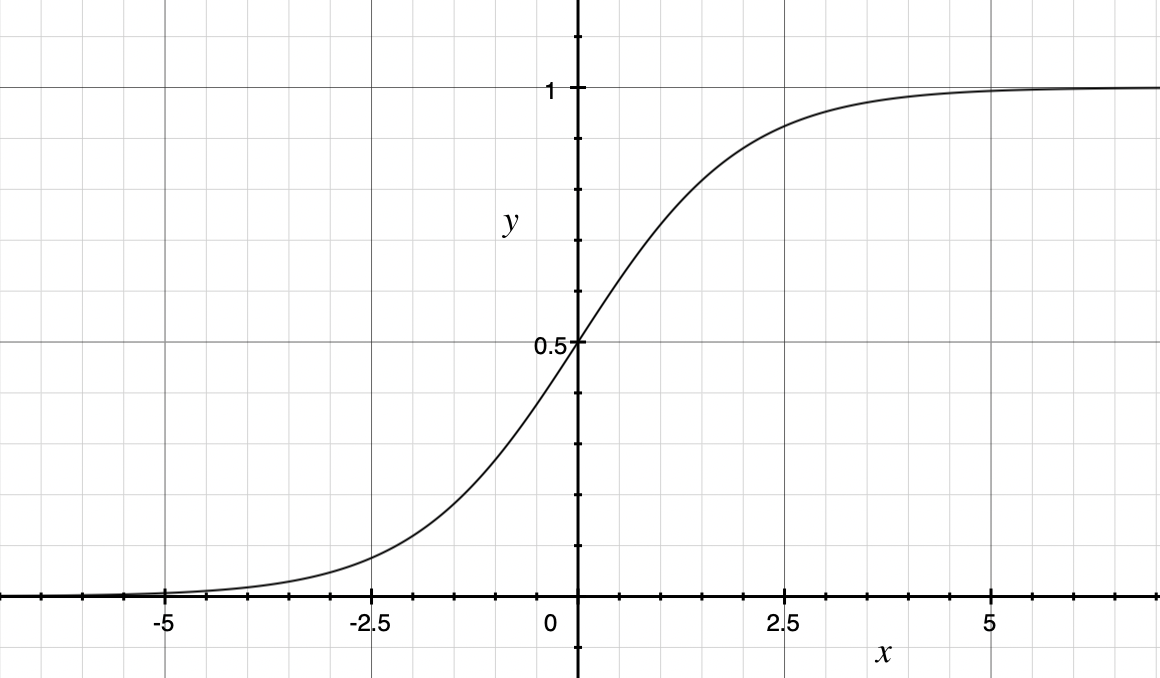
sigmoid函数作为非线性激活函数却不被经常使用,具有以下几个缺点:
1.当x非常大或者非常小的时候,sigmoid函数的导数将接近0,这会导致权重的梯度接近于0,使得梯度更新非常缓慢,即梯度消失。
2.函数的输出不是以0为均值,将不便于下层的计算。
总之:sigmoid函数可用在网络的最后一层,作为输出层进行二分类,尽量不要使用在隐藏层。
2.tanh函数(双曲正切函数)
比sigmoid函数常见,将取值为$(-\infty,+\infty)$的数映射到$(-1,1)$。公式和图形如下:$$\tanh(x)=\frac{e^z-e^{-z}}{e^z+e^{-z}}$$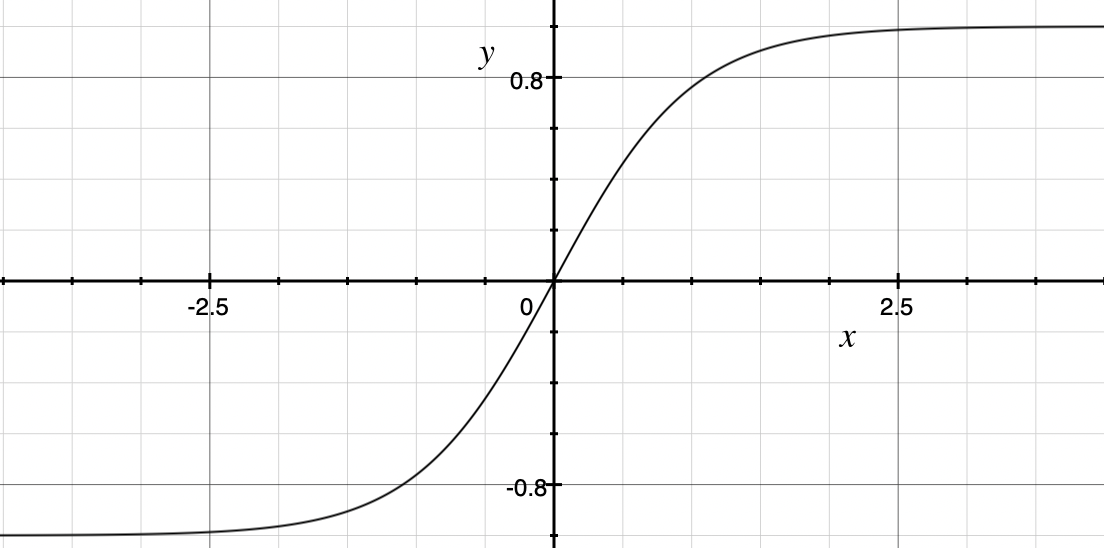
tanh函数在0附近很短一段区域可以看作是线性的。由于tanh函数均值为0,弥补了sigmoid函数的缺点。
tanh函数的缺点和sigmoid函数一样,当x很大或者很小的时候,会导致梯度很小,权重更新缓慢,即梯度消失问题。
3.ReLU函数(修正线性单元)
ReLU是一种分段线性函数,弥补了sigmoid和tanh函数的梯度消失问题。公式和图形如下:$$ReLU(x)=\begin{cases} 1, & \text {if $z>0$ } \\ 0, & \text{if $z<0$} \end{cases}$$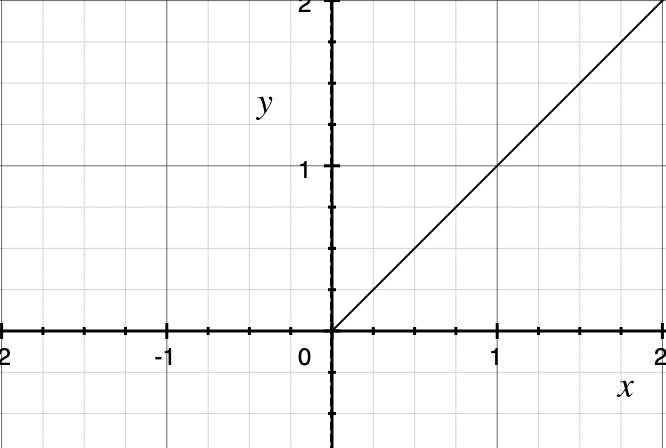
ReLU函数的优点:
1.当输入为正数的时候(大多数时候),不存在梯度消失的问题。
2.ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。
ReLu函数的缺点:
当输入为负时,梯度为0,会产生梯度消失的问题。

