【博文阅读】2023/09/26
一、ICCV 2023 | Apple提出FastViT:快速卷积和Transformer混合架构
论文名称:FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
论文地址:https://arxiv.org/pdf/2303.14189
代码地址:https://github.com/apple/ml-fastvit
博文地址:https://mp.weixin.qq.com/s/ieoDVGIEgmpxGRrsm61cDw (公众号:CVer)

本文提出了一种通用的 CNN 和 Transformer 混合的视觉基础模型,移动设备和 ImageNet 数据集上的精度相同的前提下,FastViT 比 CMT 快3.5倍,比 EfficientNet 快4.9倍,比 ConvNeXt 快1.9倍
- (1)是一种CNN+Transformer混合架构的低延时模型。
- (2)引入新的token mixer,叫做RepMixer,它使用结构重新参数化技术,通过删除网络中的Shorcut来降低内存访问成本。
- (3)进一步使用大核卷积使得FastViT精度得到提升。
对于性能这块作者在 iPhone 12 Pro 设备和 NVIDIA RTX-2080Ti desktop GPU 上进行了延迟实验比较。
FastViT 整体架构如下图所示。
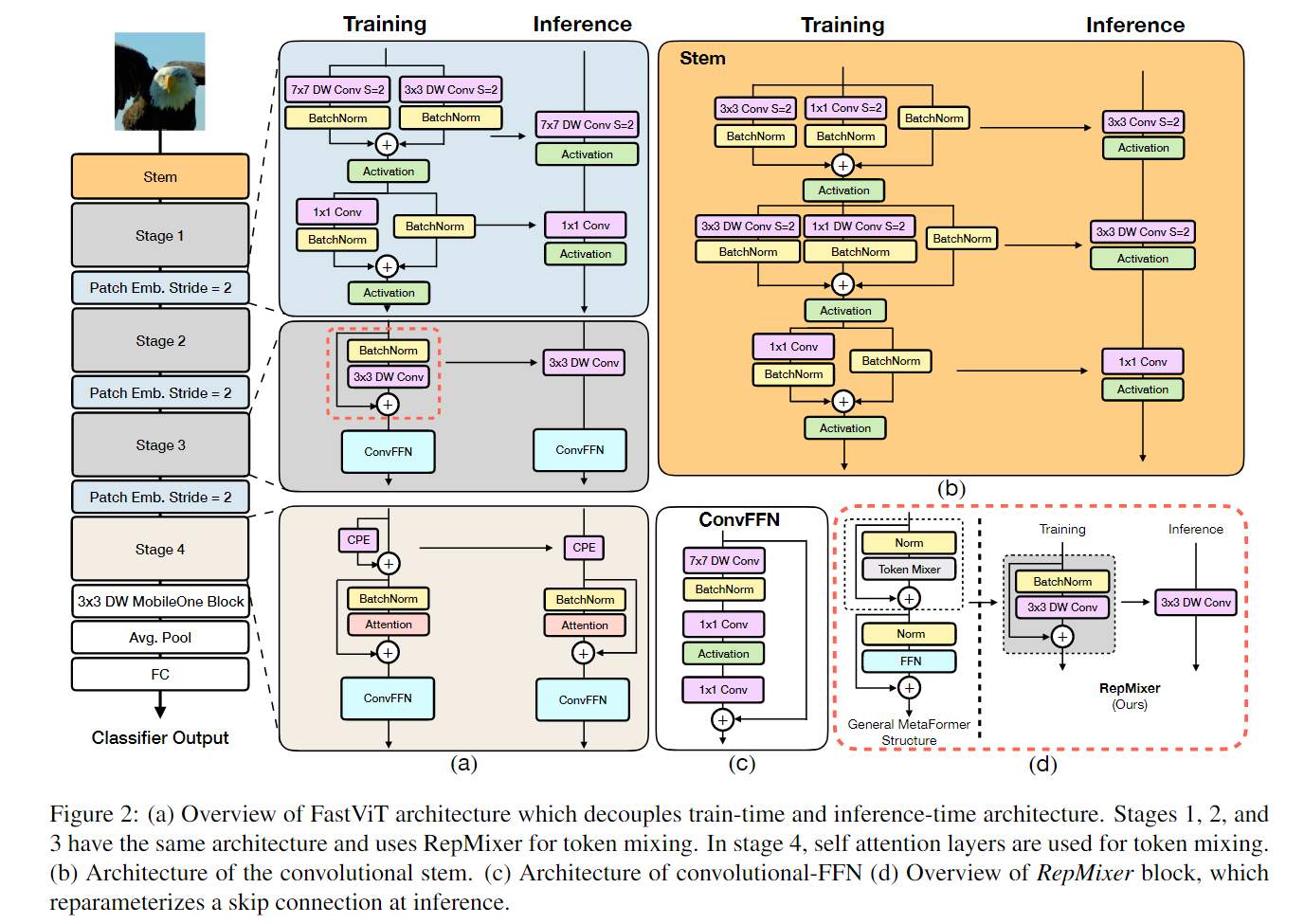
FastViT 采用了4个 stage 的架构,每个 stage 相对于前一个的分辨率减半,通道数加倍。前3个 stage 的内部架构是一样的,都是训练的时候采用下式:
![]()
推理的时候采用结构重参数化得到下式:
![]()
第4个 stage 的内部架构如图2 (a) 所示,采用 Attention 来作为 token mixer,可能是为了性能考虑,宁愿不采用结构重参数化,牺牲延时成本,以换取更好的性能。
值得注意的是,每个 Stage 中的 FFN 使用的并不是传统的 FFN 架构,而是如图2 (c) 所示的,带有大核 7×7 卷积的 ConvFFN 架构。
Stem 的结构
Stem 是整个模型的起点,如图2 (b) 所示,FastViT 的 Stem 在推理时的结构是 3×3 卷积 + 3×3 Depth-wise 卷积 + 1×1 卷积。在训练时分别加上 1×1 分支或者 Identity 分支做结构重参数化。
Patch Embedding 的架构
Patch Embedding 是模型在 Stage 之间过渡的部分,FastViT 的 Patch Embedding 如图2 (a) 所示,在推理时的结构是 7×7 大 Kernel 的 Depth-wise 卷积 + 1×1 卷积。在训练时分别加上 3×3 分支做结构重参数化。
位置编码
位置编码使用条件位置编码,它是动态生成的,并以输入 token 的局部邻域为条件。这些编码是由 depth-wise 运算符生成的,并添加到 Patch Embedding 中。
二、结构重参数化
文章标题:结构重参数化Re-parameterization
文章地址:https://zhuanlan.zhihu.com/p/555967204
结构重参数化(structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。推荐大佬的文章:
不对称卷积块(Asymmetric Convolution Block, ACB).
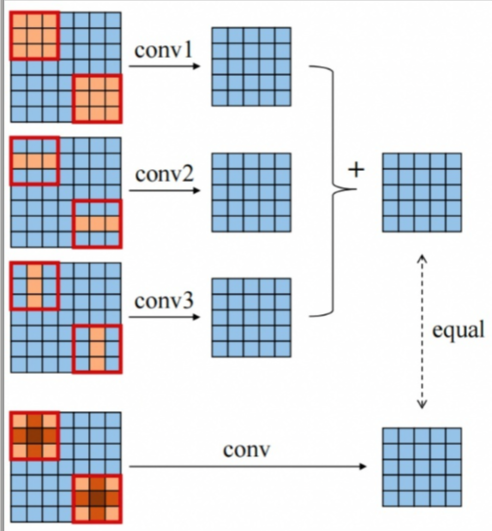
论文中只关注3x3卷积,给定一个模型,我们将每个卷积(以及后面跟着的BN层,如果有的话)替换为ACB,它由三个并行的卷积层构成,卷积核大小分别为3 × 3, 1 × 3和3 × 1。我们可以使用与原始模型相同的配置来训练,而不训练调整任何额外的参数。
总结ACB可以涨点的两个原因:
- 增强了模型对旋转畸变的鲁棒性;
- 方形卷积核骨架部分的权重对模型的表征能力比其它位置更重要,ACB进一步增强了卷积核的骨架部分。
三个分支(3 × 3, 1 × 3和3 × 1)分别进行“吸BN”后(BN fusion),我们再将三个分支进行融合(branch fusion)还原成模型原始的结构,这样在推理时用融合后的权重,在提升精度的同时也没有增加推理时间。
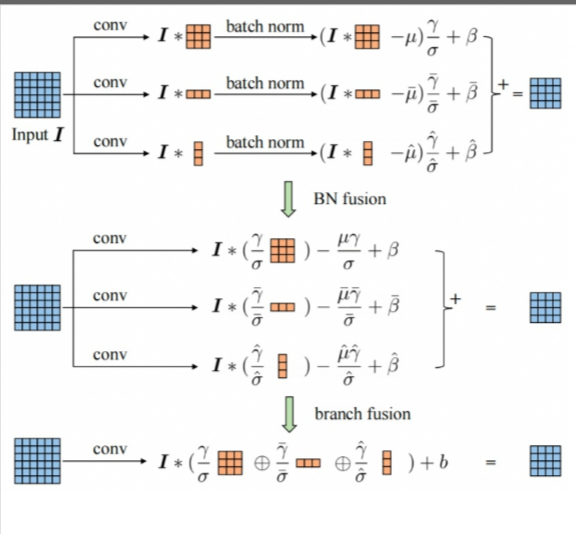
需要注意的是,虽然ACB可以等价地转换为标准卷积层,但这种等价性只在推理时成立,因为训练动态不同,从而导致不同的性能。训练过程的不等价性是由于卷积核权重的随机初始化,以及它们所参与的不同计算流所产生的梯度的不同。
推理阶段重参数化
因为单分支结构推理速度快等优点,在推理阶段通过结构重参数化将训练时的多分支结构等价转换成单分支结构
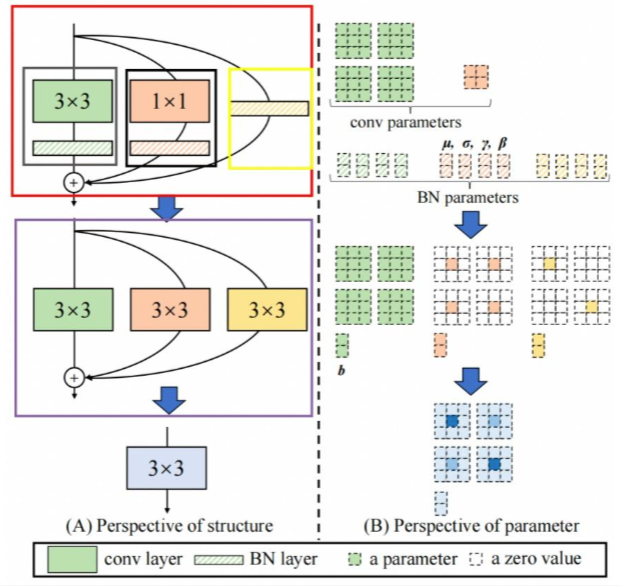
- 步骤1-首先通过式3将残差块中的卷积层和BN层进行融合,该操作在很多深度学习框架的推理阶段都会执行。图中的灰色框中执行Conv3x3+BN层的融合,图中的黑色矩形框中执行Conv1x1+BN层的融合,图中的黄色矩形框中执行Conv3*3(卷积核设置为全1)+BN层的融合。
- 步骤2-将融合后的卷积层转换为Conv3*3,即将具体不同卷积核的卷积均转换为具有3*3大小的卷积核的卷积。由于整个残差块中可能包含Conv1*1分支和Identity两种分支,如图中的黑框和黄框所示。对于Conv1*1分支而言,整个转换过程就是利用3*3的卷积核替换1*1的卷积核,具体的细节如图中的紫框所示,即将1*1卷积核中的数值移动到3*3卷积核的中心点即可;对于Identity分支而言,该分支并没有改变输入的特征映射的数值,那么我们可以设置一个3*3的卷积核,将所有的9个位置处的权重值都设置为1,那么它与输入的特征映射相乘之后,保持了原来的数值,具体的细节如图中的褐色框所示。
- 步骤3-合并残差分支中的Conv3*3。即将所有分支的权重W和偏置B叠加起来,从而获得一个融合之后的Conv3*3网络层。
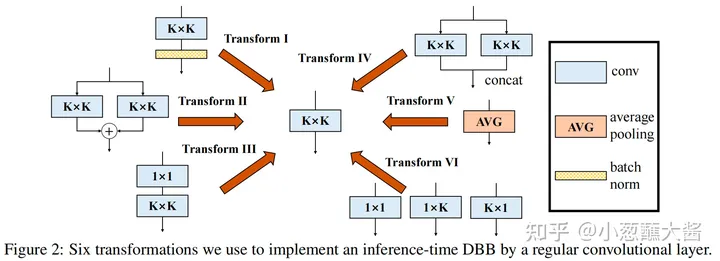
六种变换(six transformations)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号