【立体匹配--深度学习】(粗读)
目录
001 GCNet
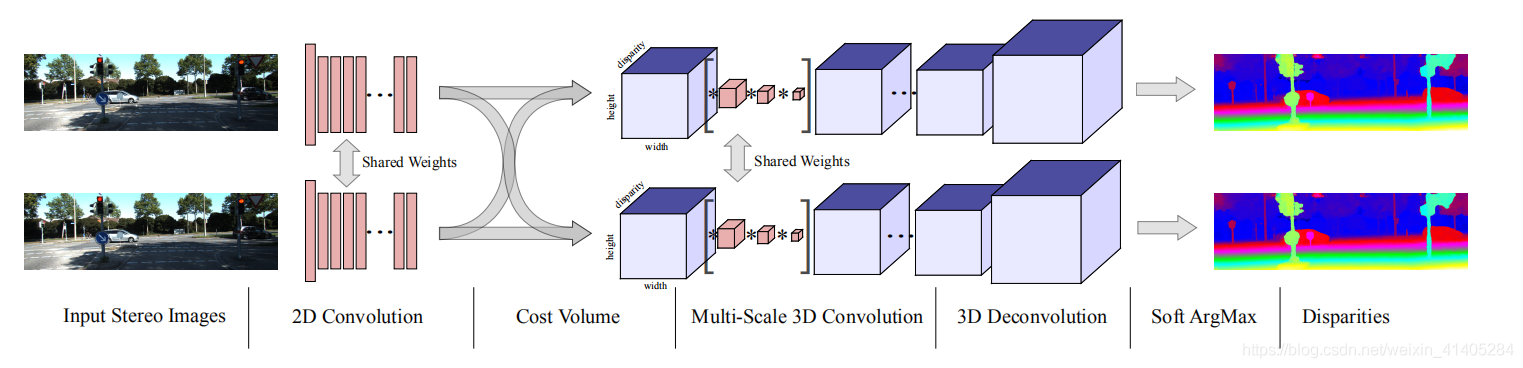
第一个入门的论文是GCNet,是一个端到端的视差生成网络。
创新点:
1、引入3D卷积
2、softmax操作
3、串联生产cost colume
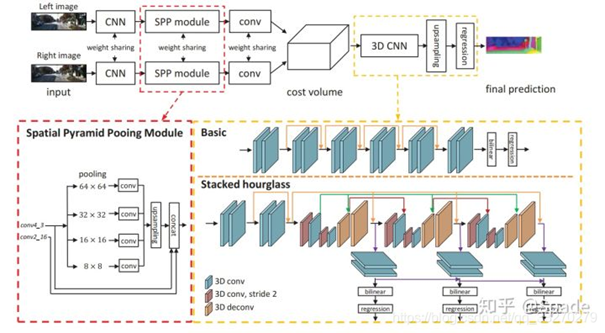
002 PSM-Net
Code(https://github.com/JiaRenChang/PSMNet)
•创新点1(红框)-- 引入了空间金字塔池化模块(spatial pyramid pooling,SPP)。用SPP聚合多尺度的信息。
•创新点2 (黄框)-- 堆叠漏斗网络(stacked hourglass networks),用3D卷积做的encoder-decoder结构。降低算力,融合多级特征。
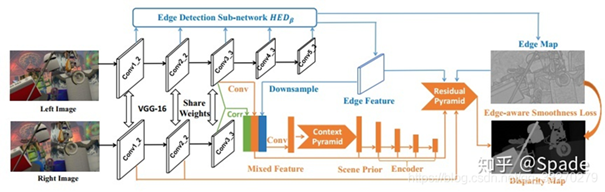
003 EdgeStereo
网络不仅能够预测视差图,还训练一个边缘子网络预测边缘图,将边缘信息整合到主网络中,指导视差学习。
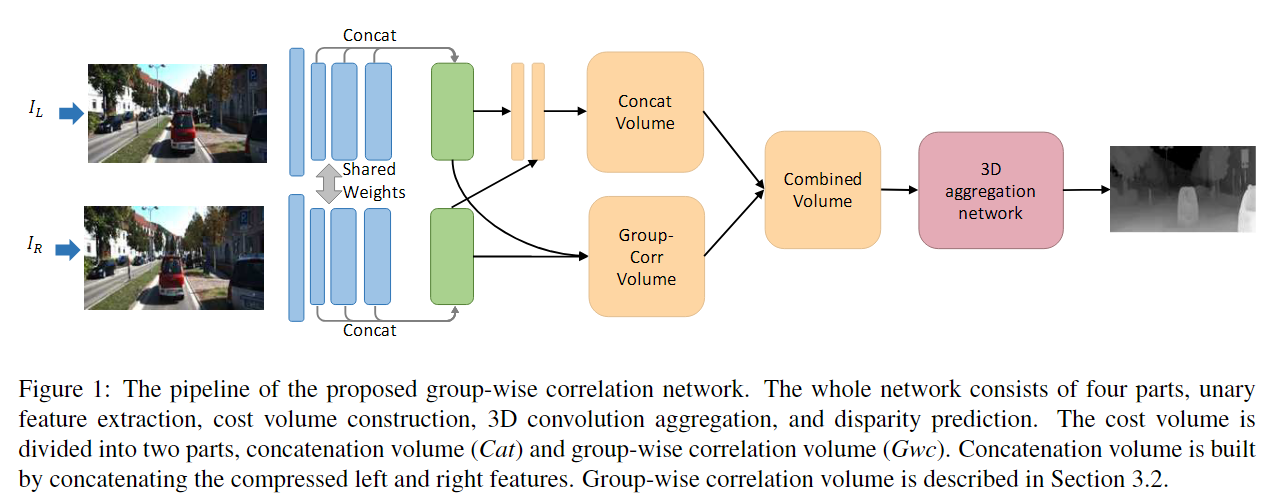
004 GwcNet
GwcNet源于文章《Group-Wise Correlation Stereo Network》,是CVPR2019的文章。代码
文章链接。无论是什么时候的理论发展,总是站在前人的基础上一步一步的去推进,GwcNet也是在PSMNet上进行的扩展。在前人基础上,做出一些一些的改进,才有了精度更好的效果,而GwcNet相比起PSMNet则做出了这样的改动:
- 使用group-wise相关的代价空间。所谓“Group-wise”就是对多通道的特征图沿着通道分组。比如文中实验部分提到的左右特征图是320通道的,就分为了40组,每组8个通道。组相关的计算是按照向量内积的方式,但是因为一组有多个通道,又不会丢失很多信息。
- 使用了改进的3D stacked 沙漏网络(hourglass network)。
其group-wise相关的代价空间对后来的网络有一定的借鉴意义。
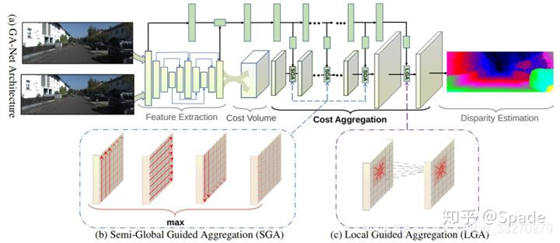
005 GA-Net
Code(https://github.com/feihuzhang/GANet )
本文主要针对立体匹配中的代价聚合(从得到cost volume到softmax回归计算视差这一部分)进行优化,传统方法就是堆叠的3D卷积,3D卷积的参数量是很高的。而本文中提出了两种网络层,用更少的参数就可以达到相同的效果。一种是对半全局匹配的修改,称为半全局聚合层(semi-global aggregation layer),另一种是局部指导的聚合层(local guided aggregation layer),也是借鉴传统立体匹配方法的代价滤波策略(后面会稍微具体地解释)。前者聚合全图多个方向的代价,使得在遮挡区域、低纹理区域也有较好的估计;后者聚合局部代价来处理那些较细的结构和物体边缘。
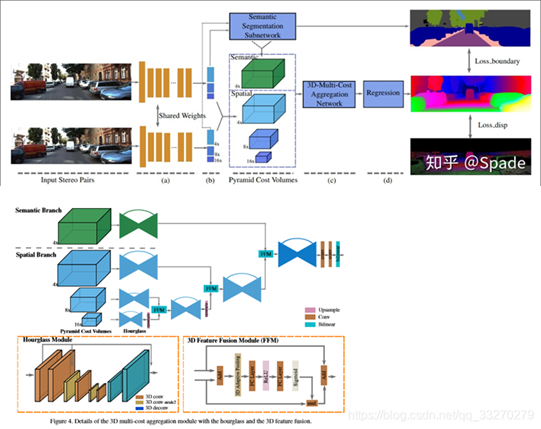
006 SSPCV-Net
•加入语义分割任务
•构建多个不同尺度的cost volume
•针对多个cost volume,提出一种融合方式
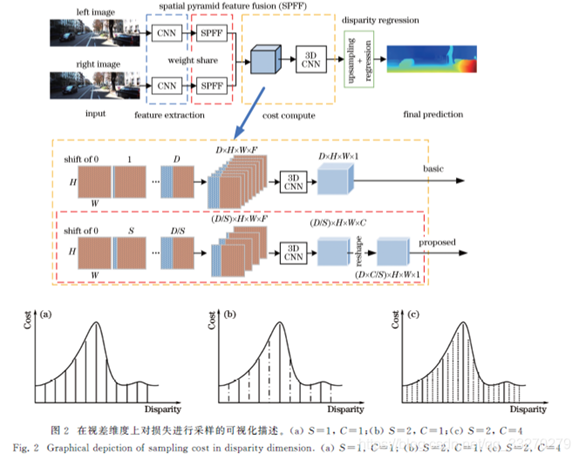
007 WSM-Net
Code (https://github.com/wyf2017/WSMCnet )
提出一种在视差维度上使用稀疏损失体进行立体匹配的方法。采用宽步长平移右视角特征图构建稀疏的三维损失体,使三维卷积模块所需的显存和计算资源均降低数倍。采用多类别输出的方式对匹配损失在视差维度上进行非线性上采样,并结合两种损失函数训练模型,在保证运行效率的同时提高算法精度。在KITTI测试集上,与基准算法相比,所提算法不仅提高了精度,而且运行时间缩短了约40%。
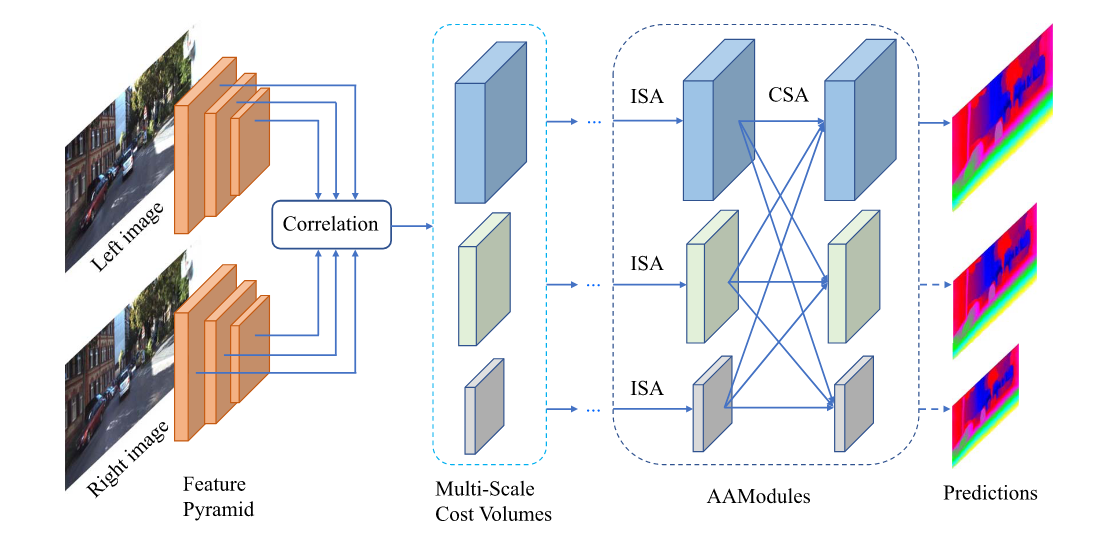
008 AANet
文章《AANet: Adaptive Aggregation Network for Efficient Stereo Matching》,是CVPR2020的文章。代码
本文提出一种新型的端到端立体匹配网络AANet,具体来说,首先提出了一种基于稀疏点的尺度内代价聚合方法,这组稀疏点被自适应地采样于与当前像素点具有相似视差的区域中,从而缓解视差不连续处的边缘肥胖问题。还学习了内容自适应权重以实现特定位置权重的代价聚合,旨在克服常规卷积中空间共享性质的固有缺点。此外,本文使用神经网络层近似传统的跨尺度代价聚合算法来处理大的无纹理区域。这两个模块都简单、轻量且互补,从而形成有效且高效的成本聚合架构。
思想:
1.首先提出了一种新的基于稀疏点的尺度内成本聚合表示方法。如图1所示,对一组稀疏点进行自适应采样,以定位在具有相似差异的区域,缓解了差异不连续[29]下的边缘增胖问题。自适应权重实现成本聚合的特定位置加权。利用deformable convolution实现。
2.我们通过利用神经网络层并行构建多尺度成本体积并允许自适应多规模交互,利用神经网络层,进一步逼近传统的跨尺度成本聚合算法,即使在低纹理或无纹理区域也能产生精确的视差预测。
3.我们还在特征提取阶段广泛利用了key ideas,从而实现了高效和准确的自适应聚合网络(AANet)。
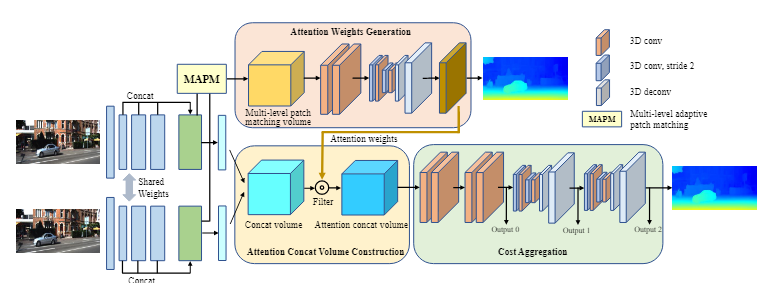
009 ACVNet
文章:《Attention Concatenation Volume for Accurate and Efficient Stereo Matching》 代码2022 (CVPR)
- Concatenation volume包含丰富但冗余的内容信息。
- Correlation volume是衡量左右图像特征相似性,可以隐含地反映图像中相邻像素之间的关系,即属于同一类的相邻像素往往具有密切的相似性。
基于这两个发现,使用correlation volume编码像素关系可以帮助concatenation volume抑制冗余信息。作者想要借此减轻代价聚合的负担同时提升准确度。
ACV利用了correlation volume生成注意力权重来滤波concatenation volume。为了得到可靠的correlation volume,使用多层适应patch matching来生成更精准的相似特征,该方法在不同特征层级使用不同大小的patch。
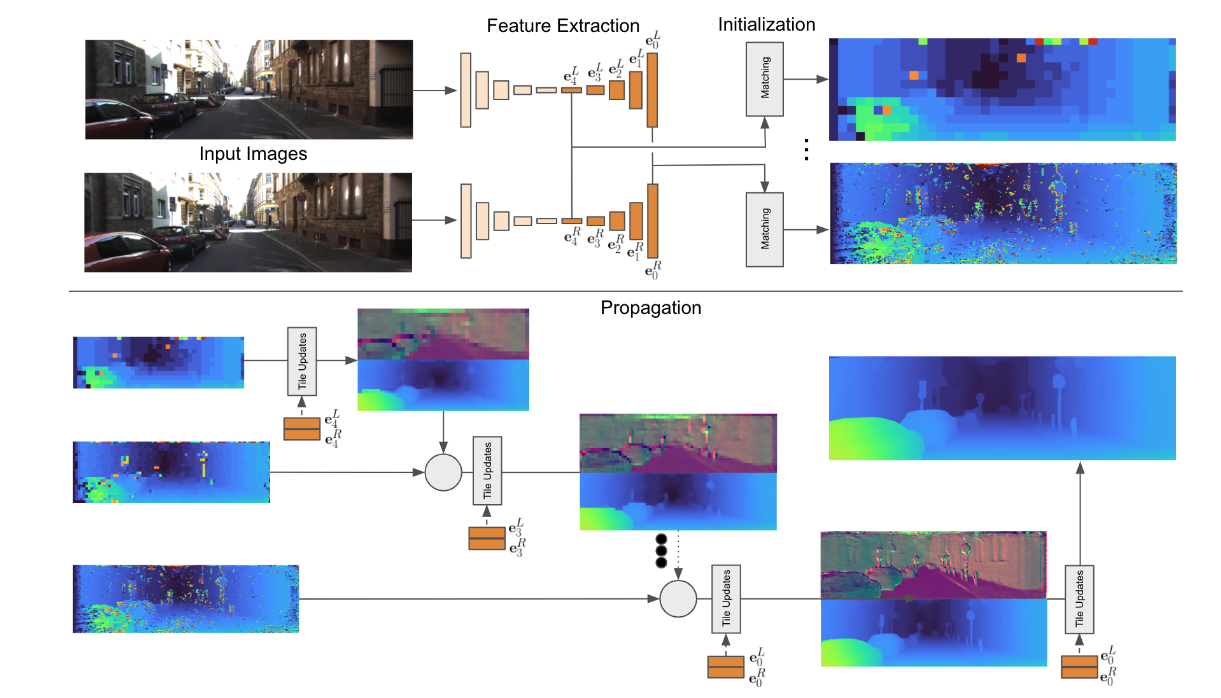
010 HiTNet
文章:《HITNet: Hierarchical Iterative Tile Refinement Network for Real-time Stereo Matching》 2021 (CVPR)
本文提出一种不需要构建代价体来进行立体匹配的方法,通过多分辨率初始化、可微的传播过程与warp机制来实现视差预测。此外基于倾斜窗口的假设来提升几何warp与上采样操作的精度;创新点如下:
- 提出一种高效的多分辨率初始化步骤,能够使用学习到的特征计算高分辨率匹配;
- 基于倾斜窗口假设与学习到的特征进行视差传播;
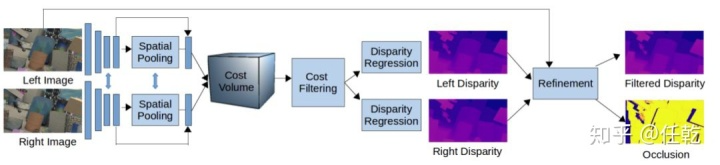
011 StereoDRNet
《StereoDRNet: Dilated Residual Stereo Net》 2019
代价聚合阶段,采用不同膨胀系数的膨胀卷积,聚合尺度下的深度信息。
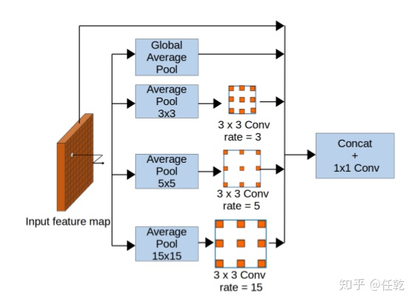
(1)特征提取部分采用Vortex Pooling architecture,结构示意图如下
(2)特征相减构建cost volume
(3)3D膨胀卷积减半计算量,huber loss计算视差。
(4)优化网路以几何误差Eg,光照强度误差Ep和为优化视差图作为输入,通过(residual learning)生成视差图和遮挡图。
012 DeepPruner
《DeepPruner: Learning Efficient Stereo Matching via Differentiable PatchMatch》 2019-09
代价聚合阶段,
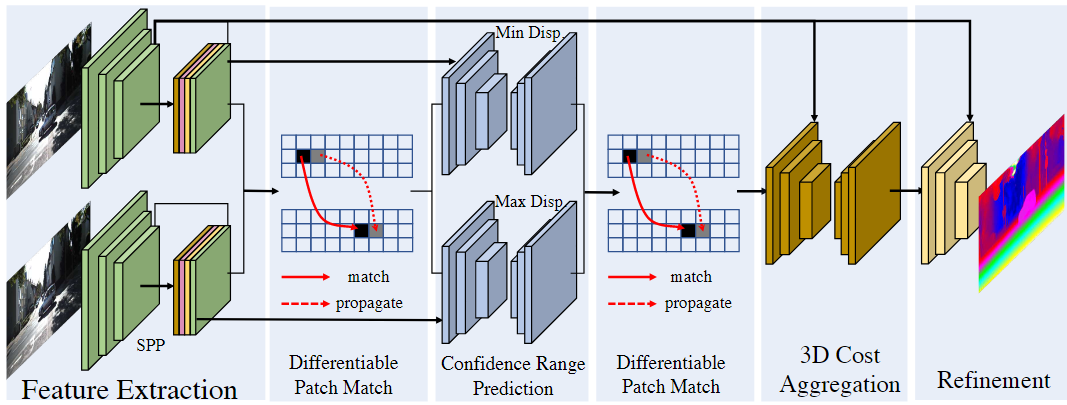
1.目的:我们的目标是显著加快当前最先进的立体声算法的运行速度,以实现实时推理。
2.网络结构:一个可微的PatchMatch模块、剪枝减小视差搜索范围、一个图像引导的细化模块
3.评价:全可微、端对端、62ms实时
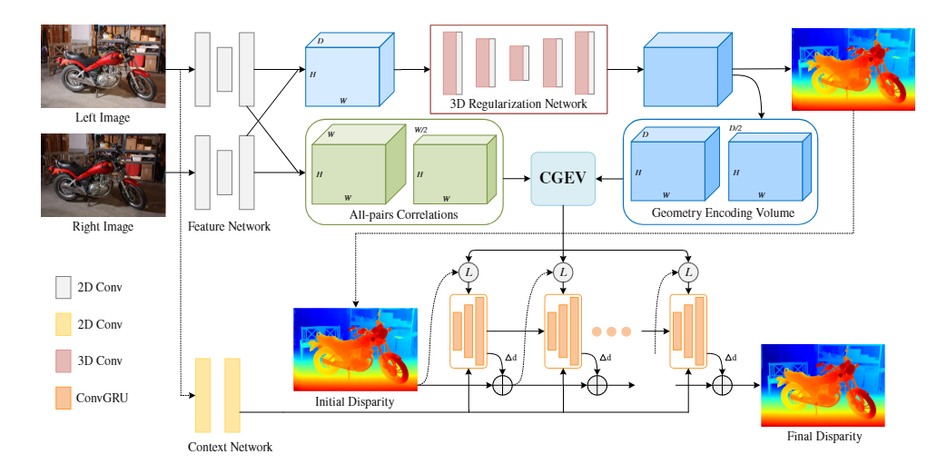
013 IGEV-Stereo
《IGEV-Stereo: Iterative Geometry Encoding Volume for Stereo Matching》 2023-03
视差优化阶段,提出的IGEV Stereo构建了一个组合的几何编码代价空间,该代价空间融合几何和上下文信息以及局部匹配细节,对逐步迭代索更新视差图进行指导。
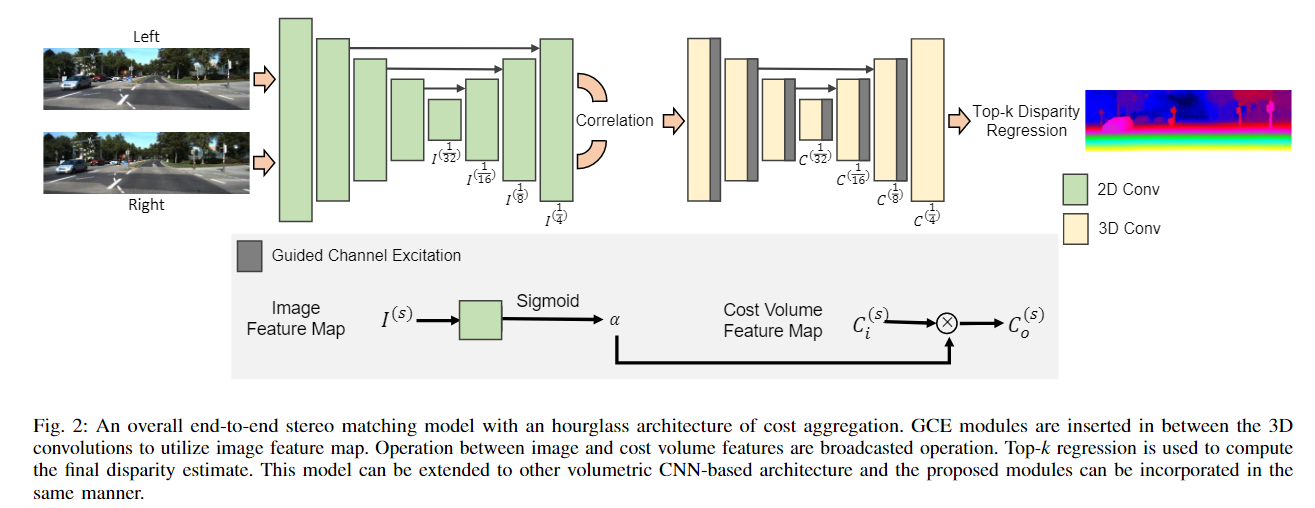
014 CoEx
文章《_Real-Time Stereo Matching via Guided Cost Volume Excitatio》(CVPR 2021) 代码
问题:使用3D卷积进行聚合的深层堆叠计算成本高且内存效率低
核心思想:提出了引导代价体激励(GCE),以利用从图像中提取的特征图作为代价聚合的指导来提高性能;提出了一种新的视差回归方法来代替soft-argmax(argmin)来计算前k个匹配代价值的视差,并表明它可靠地提高了性能;构建了一个实时立体匹配网络CoEx,它优于其他面向速度的方法,并与最先进的模型相比时显示出竞争力。
实现方法:
- 特征提取:使用MobileNetV2作为我们的主干特征提取器,因为它具有轻量级的特性,并构建了一个U-Net方式的上采样模块,在每个尺度层次上都有长跳跃连接;
- 构建代价体:在左右图像的1/4尺度上提取的特征图构建相关层,以输出D/4×H/4×W/4代价体;
- 代价聚合:遵循GC-Net,具有3D卷积的沙漏结构,但减少了通道数量和网络深度以降低计算代价,在每一个模块之后加入引导代价体激励;
- Top-k视差回归
(轻量级)EPE:0.6854 显卡:RTX 2080Ti (27ms) 参数量:2.7M
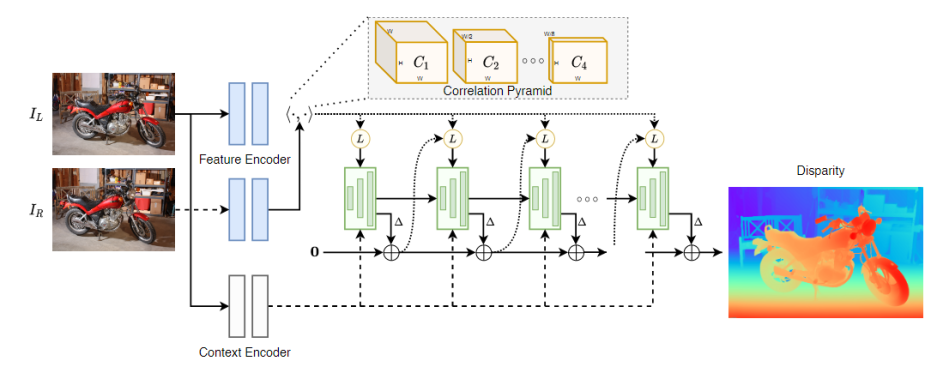
015 RAFT-Stereo
《RAFT-Stereo: Multilevel Recurrent Field Transforms for Stereo Matching》2021(3D Vision Best Paper)
引入了多级卷积gru,它更有效地在图像上传播信息。GRUs?
● 构建多尺度Conv-GRU模块,迭代优化时增大网络感受野,从而增加对大范围无/弱纹理区域的适应性;
● Slow-Fast GRU:通过使用小分辨多更新、大分辨率少更新的策略,保持精度的同时提升了速度。
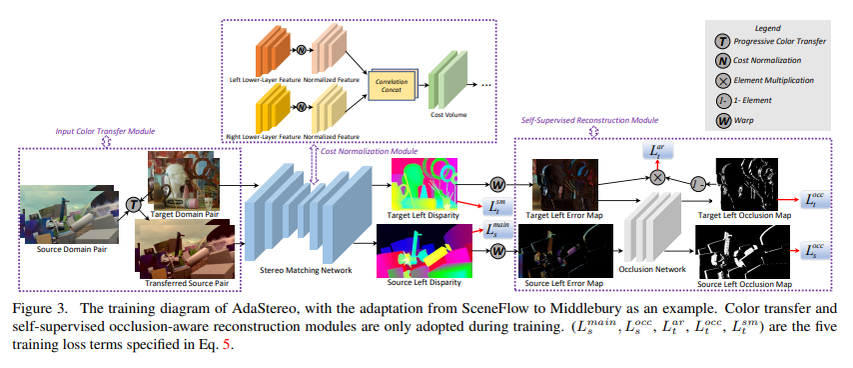
016 AdaStereo
《AdaStereo: A Simple and Efficient Approach for Adaptive Stereo Matching》2020(arxiv) 商汤+香港大学
总结下来就是对input/cost volume/output的域对齐。网络的整体结构如下:
- 对于input的对齐,non-adversarial progressive color transfer的方式来进行从source domain到target domain的颜色转换。转换到LAB空间,按target均值方差,通过加减乘除,改变source的均值方差。
- 对于cost volume的对齐,在输入图片对的底层特征上做了channel-based normalization和pixel-based normalization,从而保证了cost volume的数值范围变化不大。
- 对于output的对齐,引入了自监督的立体匹配方式,主要通过reconstruction loss和smooth loss来约束网络的训练,只不过在计算occlusion mask的时候没有像某些方法一样采用左右一致性检验来生成,而是用了一个专门的网络来预测,这个网络可以通过source images的训练过程获取label从而正常训练。
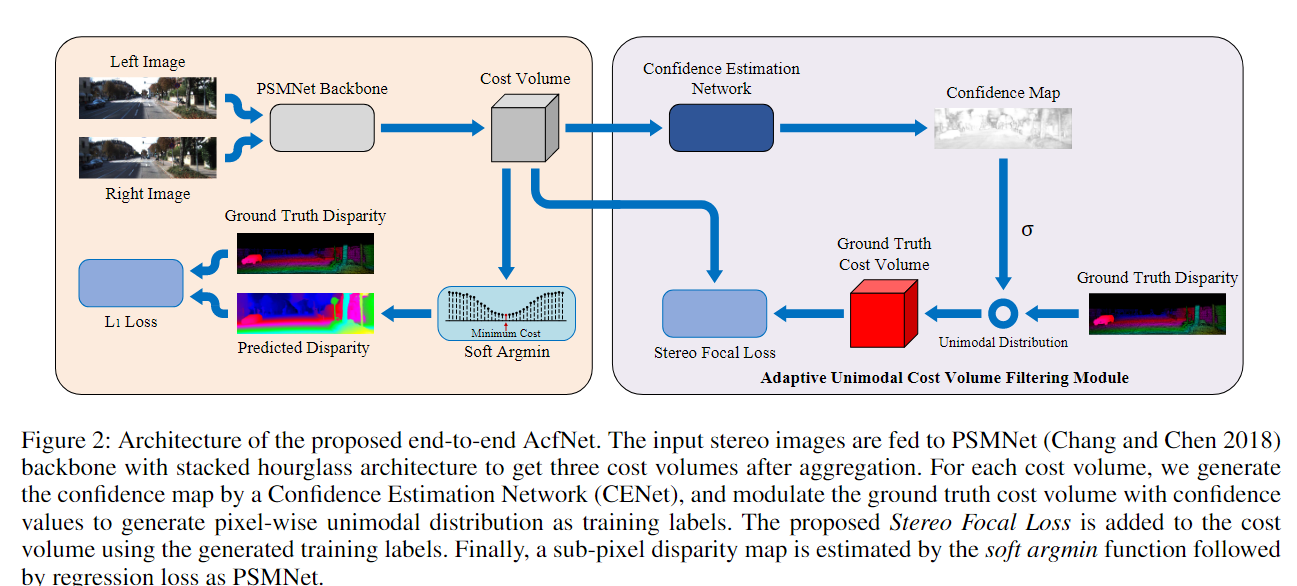
017 AcfNet
《Adaptive Unimodal Cost Volume Filtering for Deep Stereo Matching》2020 (AAAI)
代码
本文提出自适应单峰成本体积过滤网络 (AcfNet),使用在真实视差处达到峰值的单峰分布直接监督成本量(过滤成本量),向成本量添加约束。 此外,设计一个置信估计网络来估计每个像素的单峰分布的方差以明确模拟不同上下文下的匹配不确定性,控制单峰真值分布的清晰度。
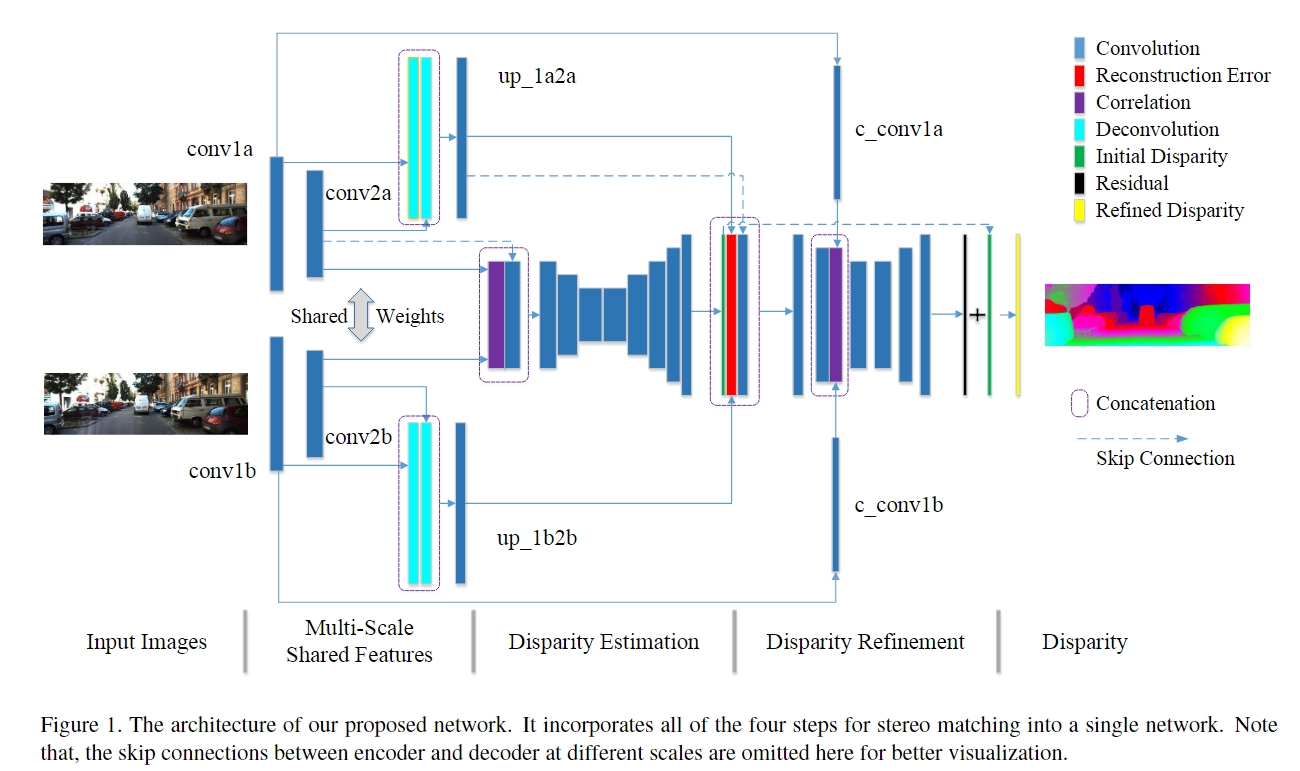
018 iResNet
《Learning for Disparity Estimation through Feature Constancy》CVPR 2018
核心思想:提出迭代残差网络iResnet,将立体匹配的所有步骤合并到一个网络来改善视差估计精度和计算效率。该网络分成三步模块:多尺度共享特征提取、初始视差估计和视差改进,最关键的贡献是使用特征恒量用于视差改进的子网络。这篇属于“多阶段”策略的论文,这个多阶段和端到端不矛盾,就是看上去像一种有先后顺序的感觉
实现方法:
-
多尺度共享特征提取:输入图像先提取多尺度的特征,左右图像的共享权重提取的特征用于视差估计和视差细化;
-
初始视差估计:视差估计网络借鉴了DispNetC,采用了encoder-decoder结构,采取跳跃连接。但不同于DispNetC,这里获得全分辨率的初始视差图。相关层连接左图特征,引入低级语义特征,有助于改进视差估计。
-
视差改进:初始视差在深度不连续区域面临挑战,因此需要进行视差细化进一步提升性能。因此用特征恒量(即特征相关和重建误差:利用估计的视差图和右图可以重建出左图,重建的左图和真实的左图之间的误差)改进。视差改进子网络估计初始视差的残差,残差和初始视差的总和就是改进的视差图。
-
迭代优化:为了从多尺度融合特征中提取更多信息并最终提高视差估计精度,提出了一种迭代细化方法。具体来说,将第二个子网络生成的改进视差图视为新的初始视差图,然后重复特征恒量计算和视差改进过程以获得新的细化视差。重复此过程,直到两次连续迭代之间的改进很小。请注意,随着迭代次数的增加,改进会降低。
(轻量级)EPE:1.40 显卡:Nvidia Titan X (90ms) 参数量:43.11M
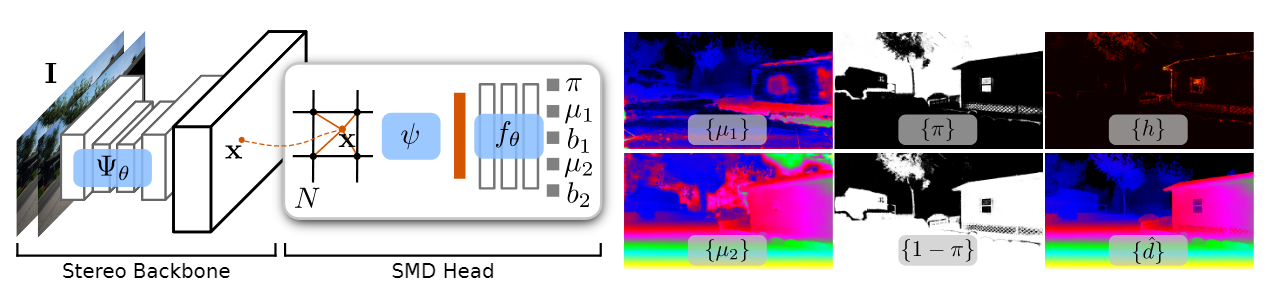
019 SMD-Nets
文章《SMD-Nets: Stereo Mixture Density Networks》2021 (CVPR) 代码
问题:恢复尖锐边界和高分辨率输出
在本文中,我们提出了立体混合密度网络(Stereo Mixture Density Networks, SMD-Nets),这是一种简单而有效的学习框架,可与广泛的2D和3D体系结构兼容,改善了这两个问题。
具体来说,我们利用双峰混合密度作为输出表示,并表明这允许在不连续点附近进行清晰而精确的视差估计,同时明确地对观测中固有的任意不确定性进行建模。此外,我们将视差估计作为图像域的连续问题,允许我们的模型在任意空间精度查询视差。
贡献:
- 一种新颖的立体匹配学习框架,利用紧凑的参数化双峰混合密度作为输出表示,并可以使用简单的基于似然的损失函数进行训练。其简单的公式提升了深度不连续处的锐利表现,并提供了不确定性度。
- 一个连续函数公式的表达,旨在不增大内存占用的前提下,得到任意空间分辨率的视差图。
- 一种高分辨率、大规模合成的双目立体数据集,其视差真值分辨率为3840x2160,场景包括室内和室外。
020 CREStereo
《CREStereo:Practical Stereo Matching via Cascaded Recurrent Network with Adaptive Correlation》 2022 (CVPR)
针对问题:将训练得到的匹配模型应用到实际场景下时输出效果会出现较大退化
这篇文章对于实际场景中存在的问题提出了一种合成数据、真实数据联合训练的多层次迭代优化双目视差估计算法加以解决,文章的主要贡献点可以总结为如下几点:
- 网络结构上:提出AGCL(Adaptive Group Correlation Layer),首先使用channel-group局部窗口计算local feature attention,之后在视差图解码预测的不同阶段上交替使用2D和1D的kernel实现局部搜索,此外通过学习的形式感知kernel的偏移offset实现更精准地搜索匹配;
- 参考RAFT中迭代优化的策略,这里文章也采用这种coarse-to-fine的迭代优化形式。除此,还可以通过在infer阶段建立图像金字塔实现级联优化,从而得到更准确的视差估计;
- 在现有合成数据集的基础上使用Blender针对复杂场景(如纤细物体、新的视差分布、图像光照变化等)进行仿真数据合成(数据量为20w),作为现有公开数据集数据的补充;
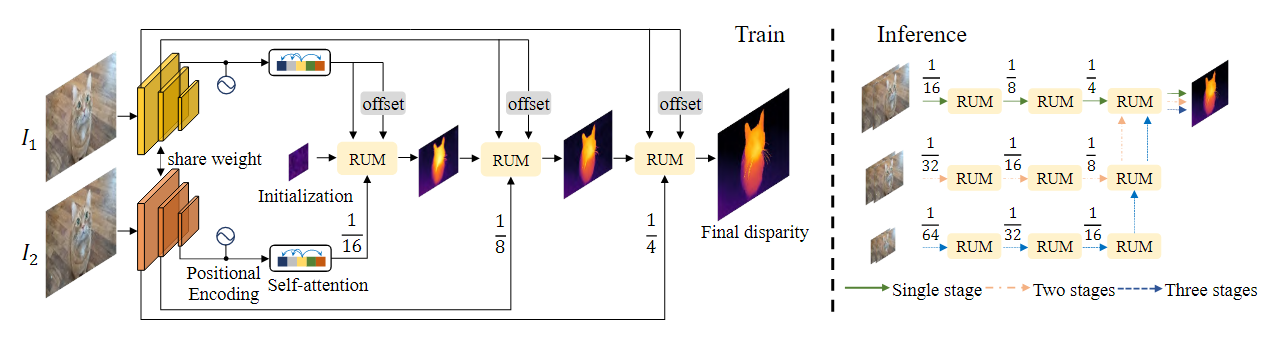
021 ChiTransformer
《ChiTransformer: Towards Reliable Stereo from Cues》 2022 (CVPR)
问题:(单目和和双目互补)立体匹配技术面临着搜索空间受限、区域闭塞和尺寸过大的挑战。单眼深度估计可以避免这些,并且可以利用提取的单目线索获得令人满意的结果,但单目缺乏立体关系,而且单目预测本身的可靠性较低,特别是在高度动态或混乱的环境中。
核心思想:提出了一种基于光学交错的自监督双目深度估计方法,其中设计了具有门控位置交叉注意(GPCA)层的视觉转换器(ViT),以实现视图之间的特征敏感模式检索,同时保留通过自注意聚合的广泛上下文信息。随后,通过混合层与检索到的模式对有条件地校正来自单个视图的单目线索。
贡献:
(1)极化注意机制,
(2)可学习的极面几何,
(3)深度线索校正方法,
模型优于现有的自监督立体声方法,并达到了最先进的精度。此外,由于其通用性,ChiTransformer可以应用于鱼眼图像而不扭曲,产生视觉上满意的结果。
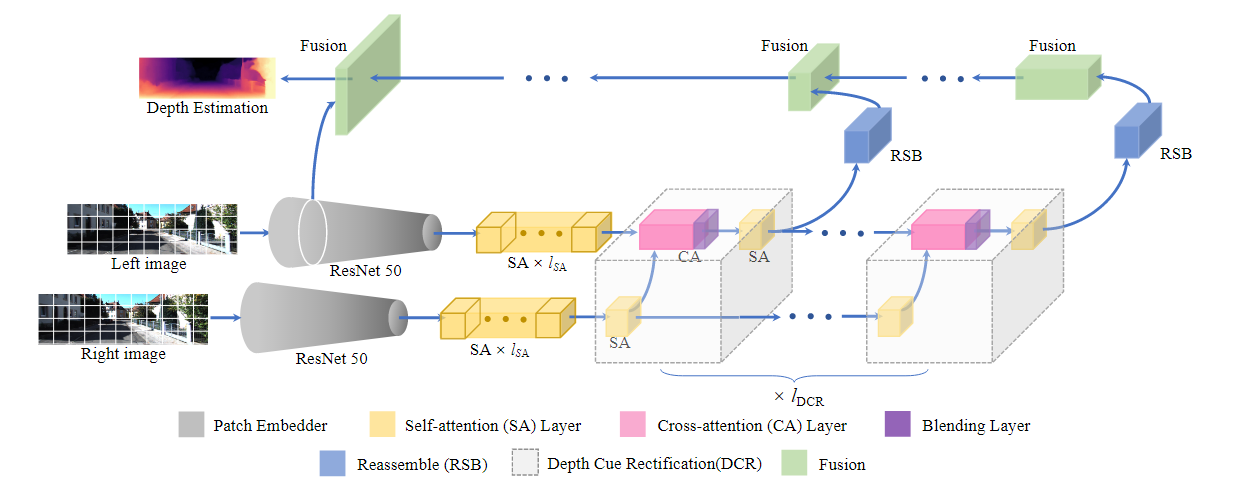
022 NS-Stereo
《NeRF-Supervised Deep Stereo》 2023 (CVPR)
问题:获得灵活和可拓展的训练样本来释放深度立体网络的全部潜力仍然是一个待解决的问题。
工作内容:我们介绍了一种新的框架,可以轻松地训练深度立体网络,并且没有任何地面真理。通过利用最先进的神经渲染解决方案,我们从单个手持相机收集的图像序列中生成立体训练数据。在它们之上,进行了nerf监督的训练过程,从中我们利用渲染的立体三组来补偿遮挡和深度图作为代理标签。这导致立体网络能够预测尖锐和详细的视差图。
贡献:
- 一种使用神经渲染和用户收集的图像序列收集和生成立体训练数据的新范式。
- NeRF监督训练协议,将渲染图像三元组和深度图相结合,以解决遮挡问题并增强精细细节。
- 最先进的零样本泛化在具有挑战性的立体数据集上产生,无需利用任何地面真实或真实的立体图像
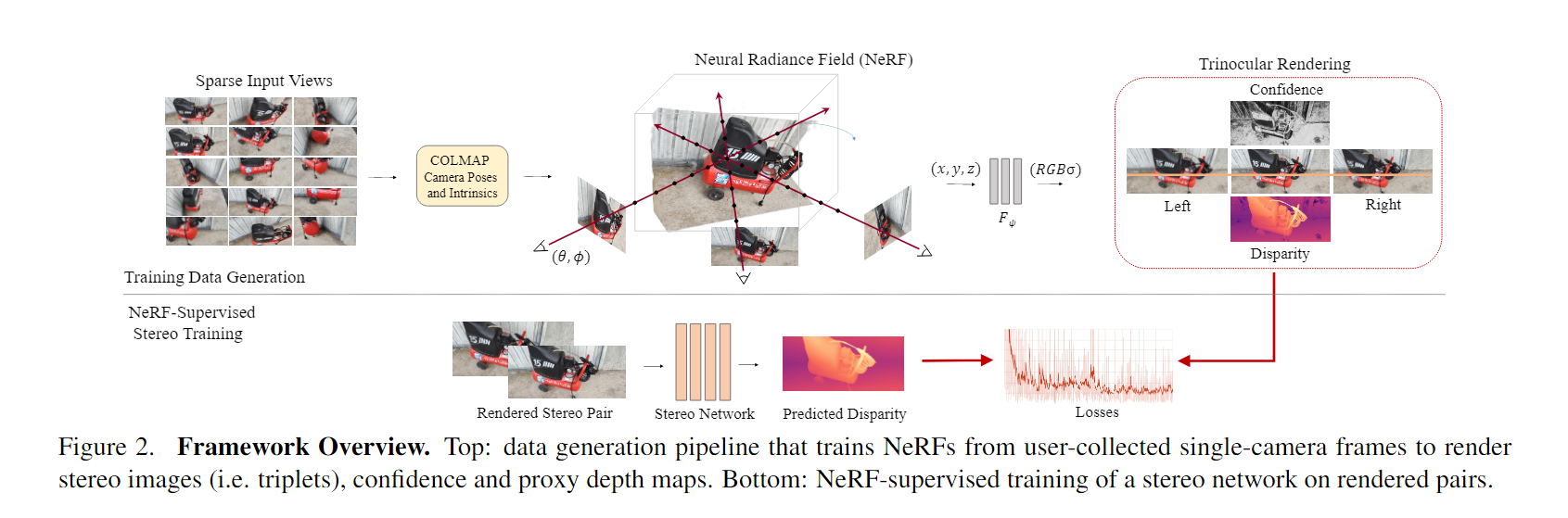
就是用NeRF分别生成左右视图的深度图,并warp到中间位置,跟双目网络生产的结果进行对比求损失,自监督,只需要左右视图,不需要额外的深度数据
文中说,NeRF监督的框架可以使立体匹配网络在自监督的情况下达到有监督的效果!
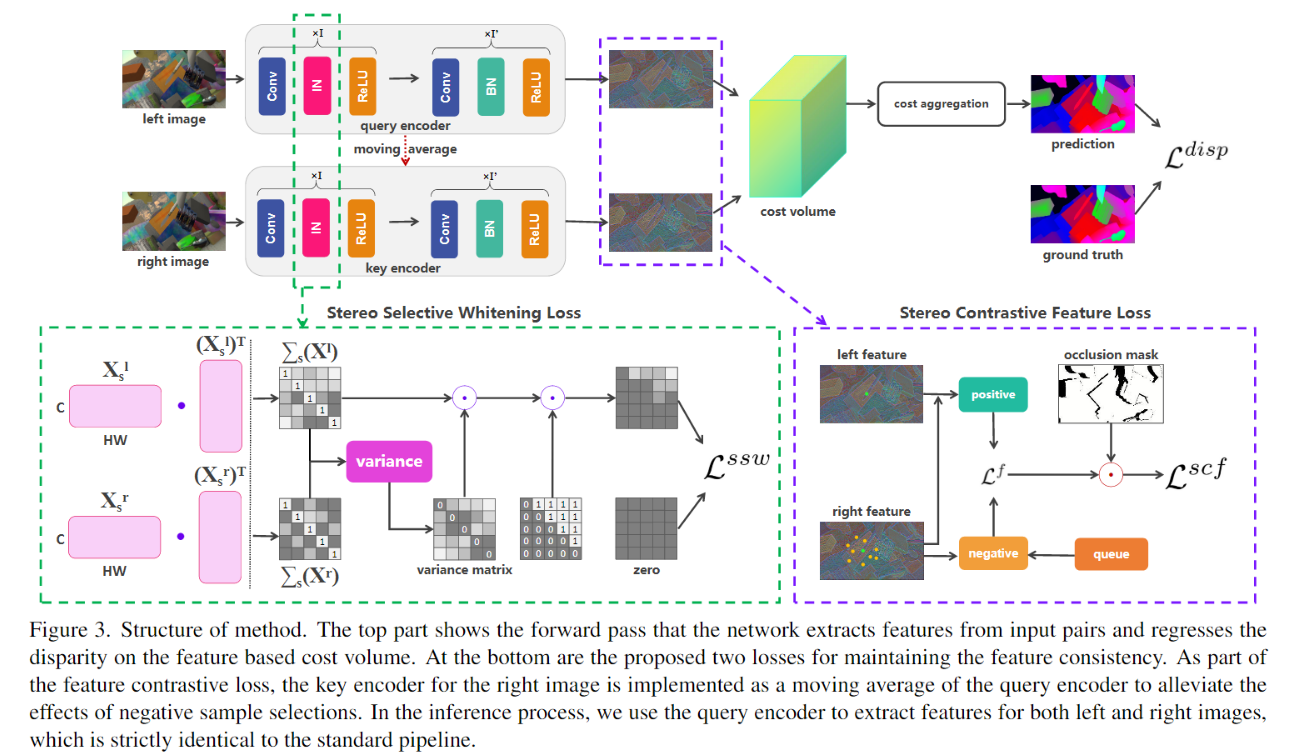
023 FCStereo (2022 CVPR)
【关键词】损失函数 域一致性 EPE : 0.86
【论文】:Revisiting Domain Generalized Stereo Matching Networks from a Feature Consistency Perspective (2022 CVPR)
贡献:
(1)Stereo Contrastive Feature Loss(SCF loss)
文章就对匹配点对儿最后得到的特征进行了loss计算(差异计算)来保证一致性
(2)Stereo Selective Whitening Loss(SSW loss)
SCF loss只能保证同一域内匹配点的特征不变或者近似,但是无法保证域改变后也能保证这种不变性,因此,又引入了一个对于特征维度的约束,即分别算出左图和右图的协方差矩阵(维度为C*C,计算的时候WH看成某一个通道的向量特征),然后两个协方差矩阵做差值,用此差值矩阵来计算loss
024 CFNet(2021 CVPR)
关键词】coarse-to-fine 视差范围差异 多级代价空间 自适应视差候选估计
【论文】:CFNet: Cascade and Fused Cost Volume for Robust Stereo Matching
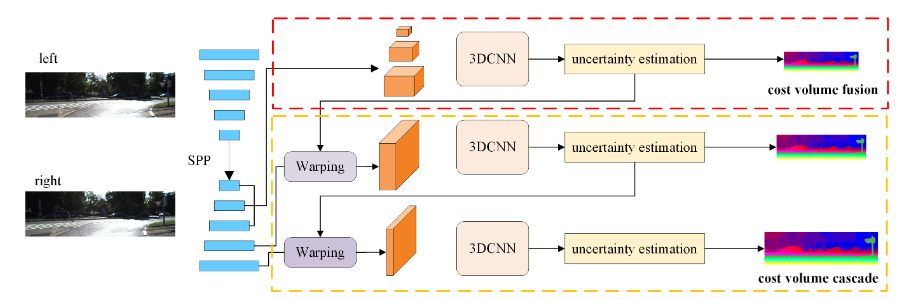
文章围绕cost volume展开研究,认为影响目前立体匹配网络鲁棒性差的原因是1)各个数据集的输入分布不同2)各个数据集的视差范围不同。
○ 针对1)文章提出了融合cost volume的方式,企图通过不同scale的融合可以增强网络的感受野,在增加整体信息的同时可以兼顾细节信息;
○ 针对2)文章提出了级联cost volume的方式,但是和以往的coarse-to-fine的方式不同,文章认为初步得到coarse的视差后,进一步搜索的范围不应该是固定的,往往视差估计时会有一个置信度或者说不确定度,不确定度越大的,进一步搜索的范围应该越大,因此,文章通过预测不确定度,根据不确定度来锁定搜索的最大值最小值,然后这个范围内通过均值采样确定固定个数的视差候选值。
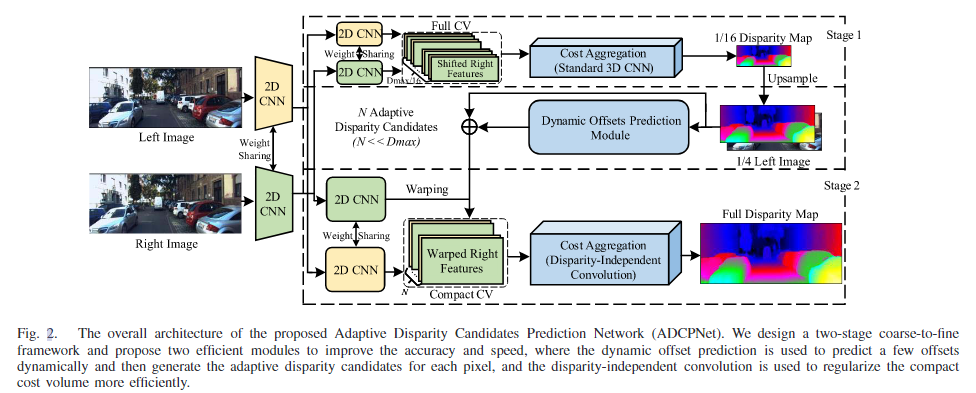
025 ADCPNet (2022 1区)
【关键词】coarse-to-fine 轻量 自适应视差候选
【论文】:Adaptive Disparity Candidates Prediction Network for Efficient Real-Time Stereo Matching
本文还采用了从粗到精的方法来满足移动应用的实时性。然而,我们的工作与上述模型在以下三个方面有所不同
(1)提出了一种自适应预测模块来代替现有的常数偏移,以适应不同图像位置的不同校正范围。
(2)我们提出了一种差异无关的卷积(即权重不共享的CNN),而不是使用传统的3D CNN来正则化紧凑的代价体积。
(3)由于所提出的两个模块的有效性,我们采用了一种两阶段的粗精设计,可以同时实现精度和速度。
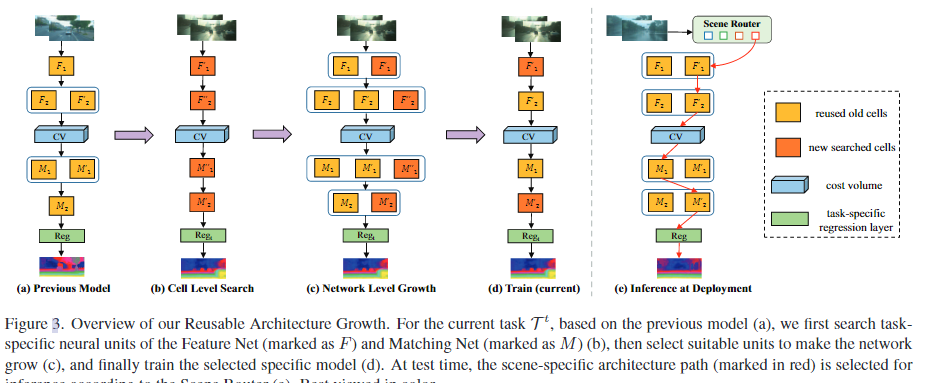
026 RAG (2022 CVPR)
【关键词】持续学习 神经单元搜索 架构增长
【论文】:Continual Stereo Matching of Continuous Driving Scenes with Growing Architecture
Reusable Architecture Growth (RAG) framework
我们的贡献总结如下:
- 我们提出了一个可重用架构增长框架(RGA),由特定任务的神经单元搜索和架构增长组成。该框架可以在不发生灾难性遗忘的情况下持续学习估计新场景的视差,同时表现出良好的学习神经单元的可重用性。
- 进一步引入场景路由器模块(Scene Router),在推理时自适应地选择当前场景的特定场景架构路径。与连续自适应方法相比[31,43],我们的方法可以快速适应快速的场景切换,并且计算效率更高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号