20212101陈雨扬 实验四
实验四 Python综合实践
课程:《Python程序设计》
班级: 2121
姓名:陈雨扬
学号:20212101
实验教师:王志强
实验日期:2022年5月31日
必修/选修: 公选课
一、实验目的及内容
夏天来了,南方的舍友对北京的天气变化情况表示很困惑,部分原话为“北京蓝天好少见诶”、“天天阴天”、“你们北京都不下雨的吗?(震惊脸)”身为北京人的我本想反驳,然而一时之间竟发现自己对北京的天气也不甚了解。所以此次实验我想通过爬虫爬取一下2021年全年北京的天气情况并进行统计,对去年北京的天气情况有一个大致的掌握。
由于本人对于课堂上的知识掌握度不高,基础薄弱,所以在百度、b站上对相关知识又进行了更加深入的学习,最终艰难地完成了此次实验。
二、实验过程及结果
2.1实验思路
在http://www.tianqi.com网站爬取2021年全年北京的天气数据,汇总后写入csv,而后对数据进行处理及可视化,最终生成轮播图。
2.2实验过程
·导入爬虫所需模块
import requests # 替代浏览器进行网络请求
from lxml import etree # 数据预处理
import csv # 写入csv文件
·找出url规律
# url的规律:……年份+月份.hml
for month in range(1,13): # 即1-12月(含头不含尾)
# 某年某月的天气信息
if month < 10:
weather_time='2021'+('0'+str(month))
else:
weather_time = '2021' + str(month)
url = f'https://lishi.tianqi.com/beijing/{weather_time}.html'
找到url规律后,就可对这一系列的url发送网络请求。
·爬虫阶段(封装到一个单独的函数中)
def getWeather(url):
weather_info=[] # {'日期':...,'最高气温':...,'天气':... }
# 请求头
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.64 Safari/537.36 Edg/101.0.1210.53'
}
# 发起请求(非结构化的数据)
resp=requests.get(url, headers=headers)
# 数据预处理 xpath(xpath数据语法:满足网页结构的语法)
resp_html=etree.HTML(resp.text)
# xpath提取当前月所有数据(每个月)
resp_list=resp_html.xpath("//ul[@class='thrui']/li")
# for循环迭代遍历每日数据
for li in resp_list:
# 每天的数据放入字典
day_weather_info = {}
# 日期 {'date_time':'2021-12-01'}
day_weather_info['date_time']=li.xpath('./div[1]/text()')[0].split(' ')[0] # 只取空格前的日期,舍去星期几
# 最高气温
high=li.xpath("./div[2]/text()")[0]
day_weather_info['high']=high[:high.find('℃')] # 字符串切割 索引 切割到℃的索引位置
# 最低气温
low=li.xpath("./div[3]/text()")[0]
day_weather_info['low']=low[:low.find('℃')]
# 天气状况
day_weather_info['weather']=li.xpath("./div[4]/text()")[0]
weather_info.append(day_weather_info)
# 返回数据
print(weather_info)
return weather_info
·调用爬虫函数
# 爬虫获取每个月的天气信息
weather = getWeather(url)
# 每月数据存入年数据
weathers.append(weather)
print(weathers)
·汇总数据并写入csv
# 数据写入 csv(一次性写入)
with open('weather.csv','w',newline='') as csvfile:
writer=csv.writer(csvfile)
# 写入列名:columns_name
writer.writerow(['日期','最高气温','最低气温','天气'])
list_year = [] # 新建年表(存放365个日数据)
for month_weather in weathers: # 第一层循环:循环每个月的数据
for day_weather_dict in month_weather: # 在每个月里循环每天的字典数据
list_year.append(list(day_weather_dict.values())) # 把字典数据的值转换为列表放到年数据里
writer.writerows(list_year) # 写入数据
得到“weather.csv”
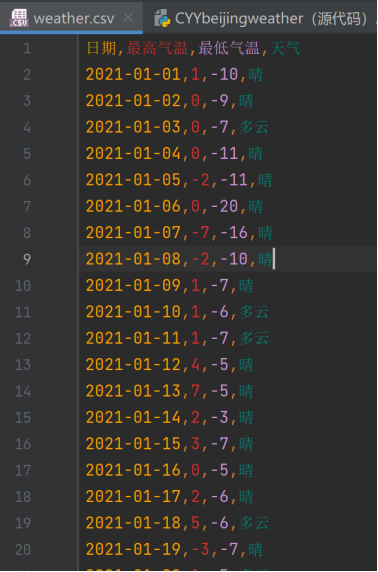
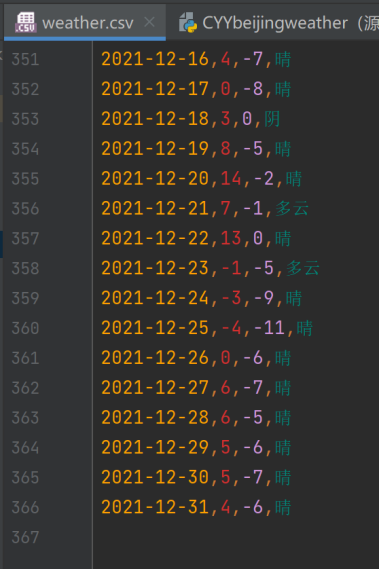
·导入爬虫所需模块
import pandas as pd # pandas主要用于读取、处理、储存数据
from pyecharts import options as opts # 数据可视化
from pyecharts.charts import Pie, Bar, Timeline
·数据处理
# 读取数据
df = pd.read_csv('weather.csv',encoding='gb18030')
# print(df['日期'])
df['日期'] = df['日期'].apply(lambda x:pd.to_datetime(x))
# print(df['日期'])
df['month']=df['日期'].dt.month
# print(df['month'])
df_agg = df.groupby(['month','天气']).size().reset_index()
# print(df_agg)
# 设置df_agg列名
df_agg.columns = ['month','tianqi','count']
# print(df_agg)
data = df_agg[df_agg['month']==1][['tianqi','count']]\
.sort_values(by='count',ascending=False).values.tolist()
# 布尔取值。依次取月份、天气、计数,
# 再用sort_values()进行排序(默认True从小到大排序,False从大到小)
# 得到的数据values不含表头
# print(data)
·数据可视化
# 时间序列
timeline = Timeline()
# 播放设置:时间间隔1s=1000ms
timeline.add_schema(play_interval=1000)
for month in df_agg['month'].unique():
data = (
df_agg[df_agg['month']==month][['tianqi','count']]
.sort_values(by='count',ascending=True)
.values.tolist()
)
# 绘制柱状图
bar = Bar()
# x轴:天气状态
bar.add_xaxis([x[0] for x in data])
# y轴:次数
bar.add_yaxis('',[x[1] for x in data])
# 横放柱状图
bar.reversal_axis()
# 将计数标签放在图形右边
bar.set_series_opts(label_opts=opts.LabelOpts(position='right'))
# 设置下图表的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='北京2021年每月天气变化'))
# 将设置好的bar对象放置到时间轮播图中,且标签选择月份
timeline.add(bar,f'{month}月')
# 将放置好的图标保存为html文件
timeline.render('weather.html')
2.3实验结果
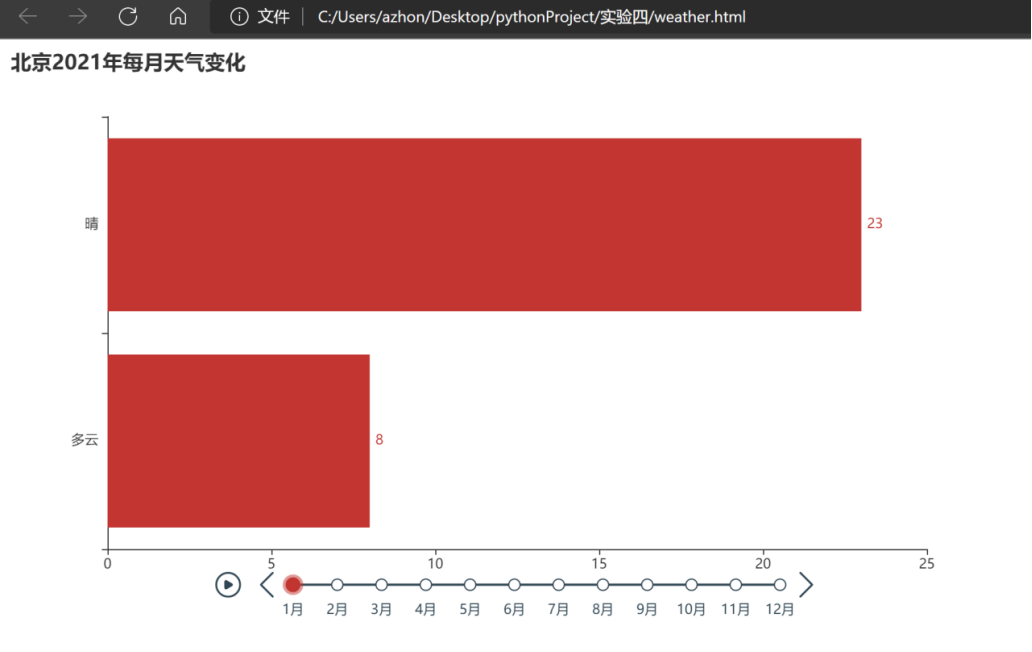
得到2021年北京天气变化轮播图。
·在云服务器上运行

2.4补充知识
·requests模块
最基本的HTTP请求模块,可以用它来模拟发送一请求,只需要给库方法传入URL还有额外的参数,就可以模拟实现这个过程了。
·pandas模块
强大的数据处理模块。可以解决数据的预处理工作,如数据类型的转换、缺失值的处理、描述性统计分析和数据的汇总等。
·构造序列:

通过字典构造不同,第一列为具体的行名称,对应字典中的键,第二列为序列的实际值,对应字典中的值。
·读取文本文件:
使用Pandas中的read_table函数或者read_csv函数

header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称
·groupby函数
主要作用:进行数据的分组以及分组后的组内运算
主要涉及步骤:
拆分:根据指定的标准对数据进行切割,并分为不同的组别
应用:分别在每个组中应用函数
组合:将所有的结果组合为数据结构
一、实验中遇到的问题
1)导入模块部分全为灰色,以为出错了

解决:百度搜索后得知是因为还未使用到这些模块,太心急啦!
2)每次运行生成的轮播图都会产生随机错误,包括x轴月份错乱甚至直接变成天气状况等,很头疼。

解决:仔细检查后发现误将[]打成了{ },修改后即可生成正确的图像。
3)企图在云服务器中下载lxml库,然而只能下到python2.7里,参照了百度的多种方法还是无法下到python3.7里,导致程序无法运行。
解决:借了课代表同学的云服务器,在他的服务器上运行成功。
一、课程总结
作为一名以前基本没有接触过计算机的小白来说,这学期同时学习C语言和python确实是有些吃力。虽然上学期选课时信心满满,喊着“我要好好学python!”的口号为抢到了这门课庆幸不已,然而这学期并没有尽力去学,很多时候没听懂或是跟不上就干脆地放弃了,没有努力补上。现在反思起来,实在是愧对老师的付出,也愧对自己的初心。
不过一学期下来收获也是不小的。虽说对很多具体的知识点没有深入掌握,但对python这门语言有了大体的了解,最重要的是有了一种亲切感、熟悉感,燃起了兴趣。印象最深刻的是老师灿烂的笑容,每次讲python都是乐呵呵的,给人一种没有什么困难克服不了的明媚心情,一种打心底的鼓舞。抱着这样的心态学习python,便觉得轻松了很多。
对课程的建议:平时每次课后可以留一些小作业,以便加深印象。清楚地记得当时讲数组的那堂课,课上听得可明白了,但课后发现自己什么都打不出来。如果当时上完课就进行练习巩固的话,或许能有更深刻的印象。
最后,由衷地感谢老师的教导,带我们走入奇妙的python世界。漫漫暑假,我打算继续进行对python的学习,多少弥补些这学期的遗憾,真正学到些技术。人生苦短,我学python!谢谢老师~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号