
这大概是最细的YOLOX中的Mosaic And Mixup 实现源码分析了吧
博客园排版有bug,更好的阅读体验请见我的新博客
前言
看了yolox后发现数据增强是真的nb,但是自己想如何实现的时候就感觉不太行了(不能简洁的实现)。又一想,数据增强这种trick肯定会用到其他网络的dataloader里面啊,所以仔细研究了一下代码复现一下。
最后附上我自己封装的mosaic和mixup,不自己封装到时候现copy别人的都不知bug在哪 虽然核心与原论文差不多
Mosaic
源码分析
下面根据yolox源码进行分析:
yolox想法是先生成一个Dataset类,然后根据这个类可以进行iterater,故写了一个pull_item函数。
基于以上,然后可以定义到MosaicDetection类
class MosaicDetection(Dataset):
"""Detection dataset wrapper that performs mixup for normal dataset."""
def __init__(
self, dataset, img_size, mosaic=True, preproc=None,
degrees=10.0, translate=0.1, mosaic_scale=(0.5, 1.5),
mixup_scale=(0.5, 1.5), shear=2.0, perspective=0.0,
enable_mixup=True, mosaic_prob=1.0, mixup_prob=1.0, *args
):
super().__init__(img_size, mosaic=mosaic)
self._dataset = dataset
self.preproc = preproc
self.degrees = degrees
self.translate = translate
self.scale = mosaic_scale
self.shear = shear
self.perspective = perspective
self.mixup_scale = mixup_scale
self.enable_mosaic = mosaic
self.enable_mixup = enable_mixup
self.mosaic_prob = mosaic_prob
self.mixup_prob = mixup_prob
self.local_rank = get_local_rank()
参数含义就不讲了,关键是self._dataset这个字段,可以看出Mosaic是在原先的Dataset基础上实现的。
也就是说需要的只是重写getitem和len,下面开始讲解getitem
第一部分 图片拼接
def __getitem__(self, idx):
if self.enable_mosaic and random.random() < self.mosaic_prob:
mosaic_labels = []
input_dim = self._dataset.input_dim
input_h, input_w = input_dim[0], input_dim[1]
# yc, xc = s, s # mosaic center x, y
# 画布大小为input_h,input_w
# 拼接公共点位置
yc = int(random.uniform(0.5 * input_h, 1.5 * input_h))
xc = int(random.uniform(0.5 * input_w, 1.5 * input_w))
# 3 additional image indices
indices = [idx] + [random.randint(0, len(self._dataset) - 1) for _ in range(3)]
for i_mosaic, index in enumerate(indices):
img, _labels, _, img_id = self._dataset.pull_item(index)
# 得到的第一张图片的原始大小
h0, w0 = img.shape[:2]
scale = min(1. * input_h / h0, 1. * input_w / w0)
# 放大到input size
img = cv2.resize(
img, (int(w0 * scale), int(h0 * scale)), interpolation=cv2.INTER_LINEAR
)
# generate output mosaic image
(h, w, c) = img.shape[:3]
# 生成一个新的画布,颜色是114
if i_mosaic == 0:
mosaic_img = np.full((input_h * 2, input_w * 2, c), 114, dtype=np.uint8)
# suffix l means large image, while s means small image in mosaic aug.
# 根据图片的先后顺序分别放入左上、右上、左下、右下四个方向。
# 函数返回的是基于画布的新坐标 和 原图像的坐标(要注意由于0.5-1.5倍,原图像可能会超出画布范围
(l_x1, l_y1, l_x2, l_y2), (s_x1, s_y1, s_x2, s_y2) = get_mosaic_coordinate(
mosaic_img, i_mosaic, xc, yc, w, h, input_h, input_w
)
# 赋值到画布
mosaic_img[l_y1:l_y2, l_x1:l_x2] = img[s_y1:s_y2, s_x1:s_x2]
plt.imshow(mosaic_img)
plt.show()
# 坐标偏移量
padw, padh = l_x1 - s_x1, l_y1 - s_y1
labels = _labels.copy()
# Normalized xywh to pixel xyxy format
# 个人觉得这个注释意思有问题(可能我理解错了?下面细说
# 这是转换到新坐标轴的坐标
if _labels.size > 0:
# 左上角坐标
labels[:, 0] = scale * _labels[:, 0] + padw
labels[:, 1] = scale * _labels[:, 1] + padh
# 右下
labels[:, 2] = scale * _labels[:, 2] + padw
labels[:, 3] = scale * _labels[:, 3] + padh
mosaic_labels.append(labels)
plt.imshow(mosaic_img)
plt.show()
大概思路是先随机得到四张图片,然后创建一个大小为网络输入两倍的input,随机(0.5-1.5 scale)生成一个mosaic center(简单理解就是四张图片的公共点)。之后按照顺序拼接到左上、右上、左下、右下四个部分。
当一张图片放入画布时,得到x,y的原偏移量(padw,padh),然后计算偏移后的bbox位置。
有个问题是新bbox的坐标,注释写的是xywh转x1 y1 x2 y2,但是个人实现的时候发现输入是bbox的x1y1x2y2转换能正确框出,有无评论区大佬说明一下。
第二部分:图像旋转与剪切
if len(mosaic_labels):
# 将bbox超出画布部分变为画布边缘
mosaic_labels = np.concatenate(mosaic_labels, 0)
np.clip(mosaic_labels[:, 0], 0, 2 * input_w, out=mosaic_labels[:, 0])
np.clip(mosaic_labels[:, 1], 0, 2 * input_h, out=mosaic_labels[:, 1])
np.clip(mosaic_labels[:, 2], 0, 2 * input_w, out=mosaic_labels[:, 2])
np.clip(mosaic_labels[:, 3], 0, 2 * input_h, out=mosaic_labels[:, 3])
# 顺时针旋转degree°,输出新的图像和新的bbox坐标
mosaic_img, mosaic_labels = random_perspective(
mosaic_img,
mosaic_labels,
degrees=self.degrees,
translate=self.translate,
scale=self.scale,
shear=self.shear,
perspective=self.perspective,
border=[-input_h // 2, -input_w // 2],
) # border to remove
这一部分就比较简单了,先是用clip函数处理好画布,然后旋转一个角度,旋转后bbox坐标变化其实可以不用关心,因为角度很小物体几乎超不出bbox的范围。细究旋转代码可以自己去看看我不想看了,最后还裁剪成了input size,所以这个最后输出还是input size而不是2*input size
Mix up
论文mosaic后半部分还增加了mixup(可选,但默认使用
# -----------------------------------------------------------------
# CopyPaste: https://arxiv.org/abs/2012.07177
# -----------------------------------------------------------------
if (
self.enable_mixup
and not len(mosaic_labels) == 0
and random.random() < self.mixup_prob
# 如果mosaic_prob=0.5 mixup_prob=0.5这里0.5*0.5是0.25的概率mixup了
):
mosaic_img, mosaic_labels = self.mixup(mosaic_img, mosaic_labels, self.input_dim)
# 这里还增加了其他的预处理
mix_img, padded_labels = self.preproc(mosaic_img, mosaic_labels, self.input_dim)
img_info = (mix_img.shape[1], mix_img.shape[0])
# -----------------------------------------------------------------
# img_info and img_id are not used for training.
# They are also hard to be specified on a mosaic image.
# -----------------------------------------------------------------
return mix_img, padded_labels, img_info, img_id
else:
# 这个else是和mosaic的if对应的,不mosaic则默认只有预处理
self._dataset._input_dim = self.input_dim
img, label, img_info, img_id = self._dataset.pull_item(idx)
img, label = self.preproc(img, label, self.input_dim)
return img, label, img_info, img_id
# mixup函数
def mixup(self, origin_img, origin_labels, input_dim):
jit_factor = random.uniform(*self.mixup_scale)
# 图像是否翻转
FLIP = random.uniform(0, 1) > 0.5
cp_labels = []
# 保证不是背景 load_anno函数不涉及图像读取会更快(coco类
while len(cp_labels) == 0:
cp_index = random.randint(0, self.__len__() - 1)
cp_labels = self._dataset.load_anno(cp_index)
# 确定不是背景后再载入img
img, cp_labels, _, _ = self._dataset.pull_item(cp_index)
# 创建画布
if len(img.shape) == 3:
cp_img = np.ones((input_dim[0], input_dim[1], 3), dtype=np.uint8) * 114
else:
cp_img = np.ones(input_dim, dtype=np.uint8) * 114
# 计算scale
cp_scale_ratio = min(input_dim[0] / img.shape[0], input_dim[1] / img.shape[1])
# resize
resized_img = cv2.resize(
img,
(int(img.shape[1] * cp_scale_ratio), int(img.shape[0] * cp_scale_ratio)),
interpolation=cv2.INTER_LINEAR,
)
# 放入画布
cp_img[
: int(img.shape[0] * cp_scale_ratio), : int(img.shape[1] * cp_scale_ratio)
] = resized_img
# 画布放大jit factor倍
cp_img = cv2.resize(
cp_img,
(int(cp_img.shape[1] * jit_factor), int(cp_img.shape[0] * jit_factor)),
)
cp_scale_ratio *= jit_factor
if FLIP:
cp_img = cp_img[:, ::-1, :]
# 以上创建好了一个可以mix up的图像
# 下面开始mix up
# 创建的画布向输入的图像上面叠加
origin_h, origin_w = cp_img.shape[:2]
target_h, target_w = origin_img.shape[:2]
# 取最大面积然后全部padding 0
padded_img = np.zeros(
(max(origin_h, target_h), max(origin_w, target_w), 3), dtype=np.uint8
)
# 放入新画布(也只有新画布
padded_img[:origin_h, :origin_w] = cp_img
# 随机偏移量
x_offset, y_offset = 0, 0
if padded_img.shape[0] > target_h:
y_offset = random.randint(0, padded_img.shape[0] - target_h - 1)
if padded_img.shape[1] > target_w:
x_offset = random.randint(0, padded_img.shape[1] - target_w - 1)
# 裁剪画布
padded_cropped_img = padded_img[
y_offset: y_offset + target_h, x_offset: x_offset + target_w
]
# 调整scale后画布中图像的bbox坐标
cp_bboxes_origin_np = adjust_box_anns(
cp_labels[:, :4].copy(), cp_scale_ratio, 0, 0, origin_w, origin_h
)
# 是否镜像翻转
if FLIP:
cp_bboxes_origin_np[:, 0::2] = (
origin_w - cp_bboxes_origin_np[:, 0::2][:, ::-1]
)
# 调整裁剪后bbox坐标(以裁剪左上角为新的原点
cp_bboxes_transformed_np = cp_bboxes_origin_np.copy()
cp_bboxes_transformed_np[:, 0::2] = np.clip(
cp_bboxes_transformed_np[:, 0::2] - x_offset, 0, target_w
)
cp_bboxes_transformed_np[:, 1::2] = np.clip(
cp_bboxes_transformed_np[:, 1::2] - y_offset, 0, target_h
)
# 通过五个条件判断offset是否合理,下面细说
keep_list = box_candidates(cp_bboxes_origin_np.T, cp_bboxes_transformed_np.T, 5)
# 满足条件则合并label和image
if keep_list.sum() >= 1.0:
cls_labels = cp_labels[keep_list, 4:5].copy()
box_labels = cp_bboxes_transformed_np[keep_list]
labels = np.hstack((box_labels, cls_labels))
origin_labels = np.vstack((origin_labels, labels))
origin_img = origin_img.astype(np.float32)
origin_img = 0.5 * origin_img + 0.5 * padded_cropped_img.astype(np.float32)
return origin_img.astype(np.uint8), origin_labels
总体来说比较好理解,因为坐标变换方法和mosaic相同,而最头疼的就是坐标变换了。
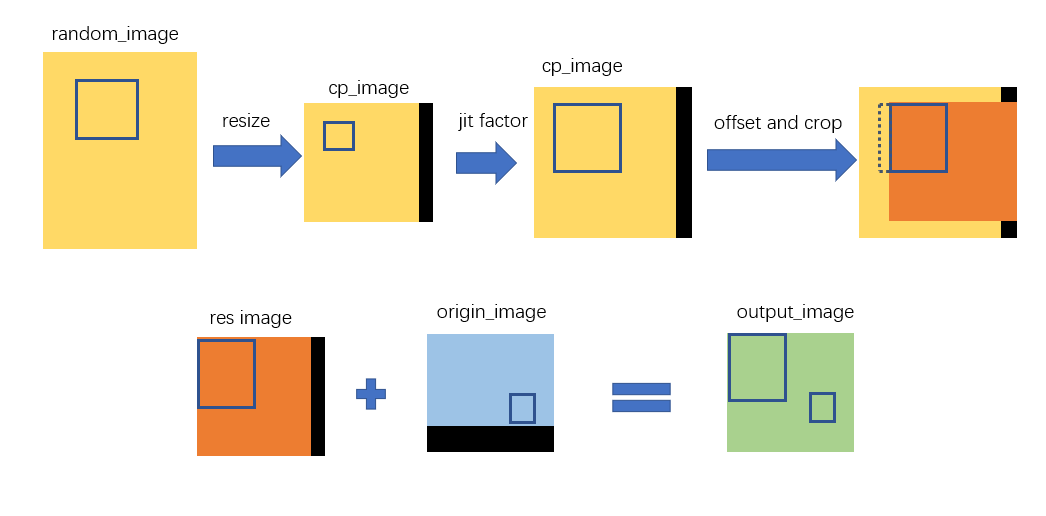
首先随机出一个非背景图像(必定有bbox的图像),然后缩放到input size,再放入input size(比如650*640)大小的画布。然后画布整体放大到jit facotr倍,在原图和新图中寻找最大的画布,在大画布中随机出裁剪偏移量,裁剪,检查没问题后mix up即可。
大致流程如下(省略了寻找最大的画布过程):
下面讲检查函数box_candidates:
def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.2):
# box1(4,n), box2(4,n)
# Compute candidate boxes which include follwing 5 things:
# box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
ar = np.maximum(w2 / (h2 + 1e-16), h2 / (w2 + 1e-16)) # aspect ratio
return (
(w2 > wh_thr)
& (h2 > wh_thr)
& (w2 * h2 / (w1 * h1 + 1e-16) > area_thr)
& (ar < ar_thr)
) # candidates
就是将偏移后的box和偏移前的box进行比较,四项指标分别是偏移后的box宽度,高度,面积,box长宽比
注释里写的五个实现只有四个
{% image https://cdn.jsdelivr.net/gh/dummerchen/My_Image_Bed03@image_bed_001/img/20210926215440.png ,alt='最终结果,中间的那两个是mix up',height=60vh %}
自用代码
因为yolox等里面肯定是用了各种东西对dataloader加速比如pycoco类封装(这个包不是很懂)、preload等,一时半会也看不完。只好剥离了,loader的效率估计不会那么高 以后变成大牛了再加吧
# -*- coding:utf-8 -*-
# @Author : Dummerfu
# @Contact : https://github.com/dummerchen
# @Time : 2021/9/25 14:06
import math
from draw_box_utli import draw_box
from torch.utils.data import Dataset
from VocDataset import VocDataSet
import matplotlib as mpl
import random
import cv2
import numpy as np
from matplotlib import pyplot as plt
mpl.rcParams['font.sans-serif'] = 'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
def get_mosaic_coordinate(mosaic_image, mosaic_index, xc, yc, w, h, input_h, input_w):
# TODO update doc
# index0 to top left part of image
if mosaic_index == 0:
x1, y1, x2, y2 = max(xc - w, 0), max(yc - h, 0), xc, yc
small_coord = w - (x2 - x1), h - (y2 - y1), w, h
# index1 to top right part of image
elif mosaic_index == 1:
x1, y1, x2, y2 = xc, max(yc - h, 0), min(xc + w, input_w * 2), yc
small_coord = 0, h - (y2 - y1), min(w, x2 - x1), h
# index2 to bottom left part of image
elif mosaic_index == 2:
x1, y1, x2, y2 = max(xc - w, 0), yc, xc, min(input_h * 2, yc + h)
small_coord = w - (x2 - x1), 0, w, min(y2 - y1, h)
# index2 to bottom right part of image
elif mosaic_index == 3:
x1, y1, x2, y2 = xc, yc, min(xc + w, input_w * 2), min(input_h * 2, yc + h) # noqa
small_coord = 0, 0, min(w, x2 - x1), min(y2 - y1, h)
return (x1, y1, x2, y2), small_coord
def random_perspective(
img,
targets=(),
degrees=10,
translate=0.1,
scale=0.1,
shear=10,
perspective=0.0,
border=(0, 0),
):
# targets = [cls, xyxy]
height = img.shape[0] + border[0] * 2 # shape(h,w,c)
width = img.shape[1] + border[1] * 2
# Center
C = np.eye(3)
C[0, 2] = -img.shape[1] / 2 # x translation (pixels)
C[1, 2] = -img.shape[0] / 2 # y translation (pixels)
# Rotation and Scale
R = np.eye(3)
a = random.uniform(-degrees, degrees)
# a += random.choice([-180, -90, 0, 90]) # add 90deg rotations to small rotations
s = random.uniform(scale[0], scale[1])
# s = 2 ** random.uniform(-scale, scale)
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(0, 0), scale=s)
# Shear
S = np.eye(3)
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Translation
T = np.eye(3)
T[0, 2] = (
random.uniform(0.5 - translate, 0.5 + translate) * width
) # x translation (pixels)
T[1, 2] = (
random.uniform(0.5 - translate, 0.5 + translate) * height
) # y translation (pixels)
# Combined rotation matrix
M = T @ S @ R @ C # order of operations (right to left) is IMPORTANT
###########################
# For Aug out of Mosaic
# s = 1.
# M = np.eye(3)
###########################
if (border[0] != 0) or (border[1] != 0) or (M != np.eye(3)).any(): # image changed
if perspective:
img = cv2.warpPerspective(
img, M, dsize=(width, height), borderValue=(114, 114, 114)
)
else: # affine
img = cv2.warpAffine(
img, M[:2], dsize=(width, height), borderValue=(114, 114, 114)
)
# Transform label coordinates
n = len(targets)
if n:
# warp points
xy = np.ones((n * 4, 3))
xy[:, :2] = targets[:, [0, 1, 2, 3, 0, 3, 2, 1]].reshape(
n * 4, 2
) # x1y1, x2y2, x1y2, x2y1
xy = xy @ M.T # transform
if perspective:
xy = (xy[:, :2] / xy[:, 2:3]).reshape(n, 8) # rescale
else: # affine
xy = xy[:, :2].reshape(n, 8)
# create new boxes
x = xy[:, [0, 2, 4, 6]]
y = xy[:, [1, 3, 5, 7]]
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T
# clip boxes
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
# filter candidates
i = box_candidates(box1=targets[:, :4].T * s, box2=xy.T)
targets = targets[i]
targets[:, :4] = xy[i]
return img, targets
def box_candidates(box1, box2, wh_thr=2, ar_thr=20, area_thr=0.2):
# box1(4,n), box2(4,n)
# Compute candidate boxes which include follwing 5 things:
# box1 before augment, box2 after augment, wh_thr (pixels), aspect_ratio_thr, area_ratio
w1, h1 = box1[2] - box1[0], box1[3] - box1[1]
w2, h2 = box2[2] - box2[0], box2[3] - box2[1]
ar = np.maximum(w2 / (h2 + 1e-16), h2 / (w2 + 1e-16)) # aspect ratio
return (
(w2 > wh_thr)
& (h2 > wh_thr)
& (w2 * h2 / (w1 * h1 + 1e-16) > area_thr)
& (ar < ar_thr)
) # candidates
def adjust_box_anns(bbox, scale_ratio, padw, padh, w_max, h_max):
bbox[:, 0::2] = np.clip(bbox[:, 0::2] * scale_ratio + padw, 0, w_max)
bbox[:, 1::2] = np.clip(bbox[:, 1::2] * scale_ratio + padh, 0, h_max)
return bbox
class MasaicDataset(Dataset):
def __init__(
self, dataset, input_size=(640,640),mosaic=True, preproc=None,
degrees=10.0, translate=0.1, mosaic_scale=(0.5, 1.5),
mixup_scale=(0.5, 1.5), shear=2.0, perspective=0.0,
enable_mixup=True, mosaic_prob=1.0, mixup_prob=1.0, *args
):
"""
Args:
dataset(Dataset) : Pytorch dataset object.
img_size (tuple):
mosaic (bool): enable mosaic augmentation or not.
preproc (func):
degrees (float):
translate (float):
mosaic_scale (tuple):
mixup_scale (tuple):
shear (float):
perspective (float):
enable_mixup (bool):
*args(tuple) : Additional arguments for mixup random sampler.
"""
self._dataset = dataset
self.input_dim=input_size
self.preproc = preproc
self.degrees = degrees
self.translate = translate
self.scale = mosaic_scale
self.shear = shear
self.perspective = perspective
self.mixup_scale = mixup_scale
self.enable_mosaic = mosaic
self.enable_mixup = enable_mixup
self.mosaic_prob = mosaic_prob
self.mixup_prob = mixup_prob
def __len__(self):
return len(self._dataset)
def __getitem__(self, idx):
if self.enable_mosaic and random.random() < self.mosaic_prob:
mosaic_labels = []
input_h, input_w = self.input_dim[0], self.input_dim[1]
# input_h,input_w=2600,4624
# yc, xc = s, s # mosaic center x, y
# 画布大小为input_h,input_w
# yc = int(random.uniform(0.5 * input_h, 1.5 * input_h))
# xc = int(random.uniform(0.5 * input_w, 1.5 * input_w))
yc=640
xc=640
# 3 additional image indices
indices = [idx] + [random.randint(0, len(self._dataset) - 1) for _ in range(3)]
for i_mosaic, index in enumerate(indices):
img, target = self._dataset.pull_item(index)
_labels=target['labels']
h0, w0 = target['image_info'] # orig hw
scale = min(1. * input_h / h0, 1. * input_w / w0)
# img 放大到input size
img = cv2.resize(
img, (int(w0 * scale), int(h0 * scale)), interpolation=cv2.INTER_LINEAR
)
# generate output mosaic image
(h, w, c) = img.shape[:3]
# draw_box(
# img, _labels[:, :4],
# classes=_labels[:, -1],
# category_index=self._dataset.name2num,
# scores=np.ones(shape=(len(_labels[:, -1]))),
# thresh=0
# )
if i_mosaic == 0:
mosaic_img = np.full((input_h * 2, input_w * 2, c), 114, dtype=np.uint8)
# suffix l means large image, while s means small image in mosaic aug.
(l_x1, l_y1, l_x2, l_y2), (s_x1, s_y1, s_x2, s_y2) = get_mosaic_coordinate(
mosaic_img, i_mosaic, xc, yc, w, h, input_h, input_w
)
mosaic_img[l_y1:l_y2, l_x1:l_x2] = img[s_y1:s_y2, s_x1:s_x2]
padw, padh = l_x1 - s_x1, l_y1 - s_y1
labels = _labels.copy()
# Normalized xywh to pixel xyxy format
if _labels.size > 0:
labels[:, 0] = scale * _labels[:, 0] + padw
labels[:, 1] = scale * _labels[:, 1] + padh
labels[:, 2] = scale * _labels[:, 2] + padw
labels[:, 3] = scale * _labels[:, 3] + padh
mosaic_labels.append(labels)
if len(mosaic_labels):
mosaic_labels = np.concatenate(mosaic_labels, 0)
np.clip(mosaic_labels[:, 0], 0, 2 * input_w, out=mosaic_labels[:, 0])
np.clip(mosaic_labels[:, 1], 0, 2 * input_h, out=mosaic_labels[:, 1])
np.clip(mosaic_labels[:, 2], 0, 2 * input_w, out=mosaic_labels[:, 2])
np.clip(mosaic_labels[:, 3], 0, 2 * input_h, out=mosaic_labels[:, 3])
mosaic_img, mosaic_labels = random_perspective(
mosaic_img,
mosaic_labels,
degrees=self.degrees,
translate=self.translate,
scale=self.scale,
shear=self.shear,
perspective=self.perspective,
border=[-input_h // 2, -input_w // 2],
) # border to remove
# -----------------------------------------------------------------
# CopyPaste: https://arxiv.org/abs/2012.07177
# -----------------------------------------------------------------
if (
self.enable_mixup
and not len(mosaic_labels) == 0
and random.random() < self.mixup_prob
):
mosaic_img, mosaic_labels = self.mixup(mosaic_img, mosaic_labels, self.input_dim)
# mix_img, padded_labels = self.preproc(mosaic_img, mosaic_labels, self.input_dim)
img_info = (mosaic_img.shape[1], mosaic_img.shape[0])
draw_box(
mosaic_img, mosaic_labels[:, :4],
classes=mosaic_labels[:, -1],
category_index=self._dataset.num2name,
scores=np.ones(shape=(len(mosaic_labels[:, -1]))),
thresh=0
)
# 想怎么输出怎么输出
return mosaic_img, mosaic_labels,img_info
else:
img, target = self._dataset.pull_item(idx)
# img, label = self.preproc(img, label, self.input_dim)
return img, target
def mixup(self, origin_img, origin_labels, input_dim):
jit_factor = random.uniform(*self.mixup_scale)
FLIP = random.uniform(0, 1) > 0.5
cp_labels = []
img=None
while len(cp_labels) == 0:
cp_index = random.randint(0, self.__len__() - 1)
img,target = self._dataset.pull_item(cp_index)
cp_labels=target['labels']
draw_box(img,cp_labels[:,:4],cp_labels[:,-1],self._dataset.num2name,scores=np.ones(len(cp_labels[:,-1])))
if len(img.shape) == 3:
cp_img = np.ones((input_dim[0], input_dim[1], 3), dtype=np.uint8) * 114
else:
cp_img = np.ones(input_dim, dtype=np.uint8) * 114
cp_scale_ratio = min(input_dim[0] / img.shape[0], input_dim[1] / img.shape[1])
resized_img = cv2.resize(
img,
(int(img.shape[1] * cp_scale_ratio), int(img.shape[0] * cp_scale_ratio)),
interpolation=cv2.INTER_LINEAR,
)
cp_img[
: int(img.shape[0] * cp_scale_ratio), : int(img.shape[1] * cp_scale_ratio)
] = resized_img
cp_img = cv2.resize(
cp_img,
(int(cp_img.shape[1] * jit_factor), int(cp_img.shape[0] * jit_factor)),
)
cp_scale_ratio *= jit_factor
if FLIP:
cp_img = cp_img[:, ::-1, :]
origin_h, origin_w = cp_img.shape[:2]
target_h, target_w = origin_img.shape[:2]
padded_img = np.zeros(
(max(origin_h, target_h), max(origin_w, target_w), 3), dtype=np.uint8
)
padded_img[:origin_h, :origin_w] = cp_img
x_offset, y_offset = 0, 0
if padded_img.shape[0] > target_h:
y_offset = random.randint(0, padded_img.shape[0] - target_h - 1)
if padded_img.shape[1] > target_w:
x_offset = random.randint(0, padded_img.shape[1] - target_w - 1)
padded_cropped_img = padded_img[
y_offset: y_offset + target_h, x_offset: x_offset + target_w
]
cp_bboxes_origin_np = adjust_box_anns(
cp_labels[:, :4].copy(), cp_scale_ratio, 0, 0, origin_w, origin_h
)
if FLIP:
cp_bboxes_origin_np[:, 0::2] = (
origin_w - cp_bboxes_origin_np[:, 0::2][:, ::-1]
)
cp_bboxes_transformed_np = cp_bboxes_origin_np.copy()
cp_bboxes_transformed_np[:, 0::2] = np.clip(
cp_bboxes_transformed_np[:, 0::2] - x_offset, 0, target_w
)
cp_bboxes_transformed_np[:, 1::2] = np.clip(
cp_bboxes_transformed_np[:, 1::2] - y_offset, 0, target_h
)
keep_list = box_candidates(cp_bboxes_origin_np.T, cp_bboxes_transformed_np.T, 5)
if keep_list.sum() >= 1.0:
cls_labels = cp_labels[keep_list, 4:5].copy()
box_labels = cp_bboxes_transformed_np[keep_list]
labels = np.hstack((box_labels, cls_labels))
origin_labels = np.vstack((origin_labels, labels))
origin_img = origin_img.astype(np.float32)
origin_img = 0.5 * origin_img + 0.5 * padded_cropped_img.astype(np.float32)
return origin_img.astype(np.uint8), origin_labels
if __name__ == '__main__':
pass
# vocdataset=VocDataSet(voc_root=r'E:\py_exercise\Dataset\pear_dataset\voc',)
vocdataset=VocDataSet(
voc_root=r'E:\py_exercise\deep-learning-for-image-processing\pytorch_object_detection\faster_rcnn\taboca\Tobacco',
image_folder_name='JPEGImages'
)
dataset=MasaicDataset(
dataset=vocdataset,
)
next(iter(dataset))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号